
The Significance of Digital Gene Expression Profiles
Abstract
Genes differentially expressed in different tissues, during development, or during specific pathologies are of foremost interest to both basic and pharmaceutical research. “Transcript profiles” or “digital Northerns” are generated routinely by partially sequencing thousands of randomly selected clones from relevant cDNA libraries. Differentially expressed genes can then be detected from variations in the counts of their cognate sequence tags. Here we present the first systematic study on the influence of random fluctuations and sampling size on the reliability of this kind of data. We establish a rigorous significance test and demonstrate its use on publicly available transcript profiles. The theory links the threshold of selection of putatively regulated genes (e.g., the number of pharmaceutical leads) to the fraction of false positive clones one is willing to risk. Our results delineate more precisely and extend the limits within which digital Northern data can be used.
Very large-scale, single-pass partial sequencing of cDNA clones from a large number of libraries has led to the identification of ∼50,000 human genes (Adams et al. 1995; Aaronson et al. 1996;Hillier et al. 1996). However, a precise function or a complete transcript sequence are known for <5000 of these (Adams et al. 1995; Boguski and Schuler 1995). In the absence of functional clues for most of the newly identified genes, evidence of differential expression is the most important criteria to prioritize the exploitation of anonymous sequence data in both basic and pharmaceutical (Nowak 1995; Adams 1996; Bains 1996; Editorial 1996) research. For example, the study of expression profiles in various tumors is central to the new Cancer Genome Anatomy project (Kuska 1996;O’Brien 1997). In contrast to functional assays, the quantitative analysis of gene expression level lends itself to large-scale implementation. Two main approaches have been proposed (1) “analog” methods based on hybridization to arrayed cDNA libraries (Lennon and Lehrach 1991; Gress et al. 1992; Nguyen et al. 1995; Schena et al. 1995; Zhao et al. 1995) or oligonucleotide “chips” (Fodor et al. 1991; Southern et al. 1992; Guo et al. 1994; Matson et al. 1995); and (2) “digital” methods, based on the generation of sequence tags. This paper focuses on the latter. The sequence tag-based method (Okubo et al. 1992; Matsubara and Okubo 1994) consists of generating a large number (thousands) of expressed sequence tags (ESTs) (Adams et al. 1991; Wilcox et al. 1991; Adams et al. 1992; Khan et al. 1992) from 3′-directed regional non-normalized cDNA libraries. Recently, Velculescu et al. (1995) have introduced the serial analysis of gene expression (SAGE). Although tags are 100–300 nucleotides in length in the original EST approach, the SAGE method only requires nine nucleotides, therefore allowing a larger throughput. In both protocols, the number of tags is reported to be proportional to the abundance of cognate transcripts in the tissue or cell type used to make the cDNA library. The variation in the relative frequency of those tags, stored in computer databases, is then used to point out the differential expression of the corresponding genes: This is the concept of a “digital Northern” comparison. In the absence of a sound theoretical framework, the validity of the method has only been verified for a handful of genes in the context of two cellular differentiation systems (Lee et al. 1995; Okubo et al. 1995) inducible in vitro. Yet, with a total number of human genes of ∼80,000 or more, it is not intuitive that sequencing a mere few thousand tags (a typical experiment) from highly redundant non-normalized cDNA libraries can produce a useful picture, or realistic “transcript profile,” of a given tissue, development stage, or cell type. What variations in tag numbers allow for a reliable inference about differential expression? How many tags should be generated? Here we present the statistical framework required to answer those questions and analyze transcript profiles in a quantitative manner.
RESULTS
In Methods we establish the probability distribution governing the occurrence of the same rare event in duplicate experiments. This probability distribution is a general result applicable to a wide variety of experimental situations, although this paper focuses on its use to analyze digital gene expression patterns. The main and only mathematical assumption behind the derivation is that the observed events are rare and part of a large population of possible outcomes (the distribution of which is not specified). In the context of a digital Northern, one event is the observation of a given cDNA sequence tag, and the experiment consists of the random picking and partial sequencing of a number N of cDNA clones. Given the usual complexity (i.e., the number of different genes expressed) of cDNA libraries, observing a given cDNA qualifies as a rare event, as the abundance of most individual messages is of the order of a few percents or less.
Random Fluctuation vs. Significant Change in Tag Number: When to Infer Differential Expression
Let us randomly pick N = 1000 clones from a cDNA library and generate the corresponding sequence tags; a given message (e.g., interleukin-2) will
be picked x (e.g., two) times, withx in a typical (0–10) range. If we now redo this experiment, that is, again pick 1000 clones and generate the tags, the same
message will now be picked y (e.g., 3) times. If the experiments have been duplicated correctly and the clones selected at random, we expectx and y to be close, albeit often different because of random fluctuations. In the Methods section, we show that the expected probability
of observing y occurrences of a clone already observed x times is given by the simple formula: Equation can be used to compute a confidence interval [ymin, ymax]ε within which we expect to find y with a given probability, noted 1–2ε, where 2ε is the significance level. For ε small (e.g., 2.5% or less), y values falling outside the [ymin, ymax]ε interval correspond top(y | x) << 1, therefore pointing out very unlikely random fluctuations between the two experiments. The confidence intervals for
the usual 1% and 5% significance levels are given in Table 1.
Equation can be used to compute a confidence interval [ymin, ymax]ε within which we expect to find y with a given probability, noted 1–2ε, where 2ε is the significance level. For ε small (e.g., 2.5% or less), y values falling outside the [ymin, ymax]ε interval correspond top(y | x) << 1, therefore pointing out very unlikely random fluctuations between the two experiments. The confidence intervals for
the usual 1% and 5% significance levels are given in Table 1.
Confidence Intervals in Function of the Value ofx
The same confidence intervals listed in Table 1 can in fact be used to analyze the results of sampling N clones from two different libraries. Provided all experimental factors are well replicated, significant discrepancies between x (from one library) andy (from the other) will now characterize differentially expressed genes, for example, the relative abundance of which is unlikely to be the same in the two libraries. Simply reading Table 1, we see that variations in counts such as 7 → 0, or 2 → 12 are significant (P < 0.01) evidence of regulated gene expression, whereas variations such as 3 → 0 or 8 → 16 are not (P > 0.05). However, we do not advocate the use of rigid significance thresholds to analyze digital transcript profiles, as discussed below.
Influence of the Sampling Size
Surprisingly at first, p(y | x) in Equation does not involve the sampling size N, that is, the total number of picked clones. The fluctuation probabilities, and confidence intervals, depend only on the values of the observed counts. To understand why, we must remember that Equation governs the results of strictly duplicated experiments. Given N clones are sampled, the most likely tags to be picked up are, intuitively, those corresponding to cDNA, the abundance of which is of the order of 1/N, or larger (according to Equation , the probability of finding a given cDNA with 1/N abundance while picking upN clones is 0.63, see also Equation ). Choosing a sampling size therefore corresponds to targeting a given subset of genes, the level of expression of which allows their tags to occur at reasonable frequencies.
As expected, more reliable inferences can be made on clones corresponding to larger absolute frequencies (i.e., the ones more often picked up). For example (see Table 1), a variation in counts from 1–3 (threefold increase) is not indicative of a significant (P < 0.05) increase, whereas a variation from 4–12 is significant at P < 0.05, and a variation from 7–21 is significant at P < 0.01. For a gene expressed at a given rate, increasing the sampling size N leads to higher tag counts, and allows more stringent statistical inference to be made, for the same proportional variation.
Most often in practice one wishes to compare digital Northerns or gene profiles that have been computed from the random picking
of different numbers of clones, N
1 and N
2. The mathematical problem is now to establish the probability for a given cDNA (e.g., interleukin-2) to be picked up x times when the sampling size was N
1 and y times when the sampling size was N
2. Equation then becomes (see Methods): Whereas Equation applied to the analysis of fluctuation in counts in strictly identical experiments, Equation now applies
to the analysis of counts in experiments only differing by the total number of clones randomly picked up. In practice, Equation
will be used to analyze experiments performed on two different libraries, using different sampling sizes. As for Equation
, smallp(y | x) are expected to characterize the genes exhibiting regulated expression, the relative abundance of which is unlikely to be
the same in the two libraries.
Whereas Equation applied to the analysis of fluctuation in counts in strictly identical experiments, Equation now applies
to the analysis of counts in experiments only differing by the total number of clones randomly picked up. In practice, Equation
will be used to analyze experiments performed on two different libraries, using different sampling sizes. As for Equation
, smallp(y | x) are expected to characterize the genes exhibiting regulated expression, the relative abundance of which is unlikely to be
the same in the two libraries.
Comparison with Fisher’s (2 × 2) Exact Test
The (2 × 2) contingency tables arising from treatment versus control experiments are traditionally analyzed with Fisher’s
exact test (Siegel 1956; Agresti 1996). Differential EST count data can be presented in a tabulated form so as to suggest the use of this test, as follows:
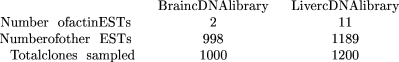
The statistical significance according to Fisher’s exact test for such a result is 4.6% (two-tail P-value, i.e., the probability for such a table to occur in the hypothesis that actin EST frequencies are independent of the cDNA libraries). In comparison, theP-value computed from the cumulative form (Equation 9, see Methods) of Equation (i.e., for the relative frequency of actin ESTs to be the same in both libraries, given that at least 11 cognate ESTs are observed in the liver library after two were observed in the brain library) is 1.6%. Fisher’s (2 × 2) exact test is always more conservative than our test (e.g., Fisher’s P-value of 1.6% requires a 2 → 13 EST count transition in the above setting). Besides being too conservative, there is a more fundamental difficulty in using this test to analyze EST count data. The sampling scheme assumed by Fisher’s exact test in principle requires the total number of data values in the contingency table to be fixed, as well as both the row marginal total and the column marginal totals. In our prospective experimental situation, only the column marginals (i.e., the numbers of clones sampled from each library) are fixed. The extension of Fisher’s exact test to cases where only one set of marginal totals is fixed (Tocher 1950) is still controversial. In the context of the above EST counting results, there is an additional problem with the lack of homogeneity in the definition of the “other EST” category. This category represents different subsets of transcripts for different libraries.
The use of Fisher’s (2 × 2) exact test is more natural for a different type of EST data analysis: the study of library-dependent
alternative transcripts of the same gene (i.e., splice or polyadenylation variants) (D. Gautheret, O. Poirot, F. Lopez, S.
Audic, and J.-M. Claverie, in prep.). Here, the results for an hypothetical gene G1 may look as follows:
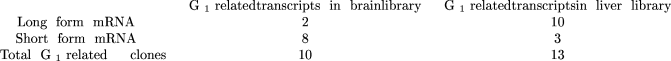
where the alternative categories are unambiguously defined and refer to the same objects. For example, the above results constitute good evidence that G1 is expressed in different forms in those tissues (Fisher’s exact test two-tailP-value = 1.2%).
False Leads in the Selection of Candidate Genes
A crucial measure of the power of statistical significance tests is their rate of false alarm, that is, how often random fluctuations are expected to be mistaken for significant differences in the results. When analyzing the transcript profiles from two different libraries, a false alarm would cause a gene to be deemed differentially transcribed, whereas in fact it is not. The rate of false alarm is therefore a direct estimate of the fraction of false leads, when searching for differentially expressed genes on the basis of differences in tag counts. The rates of false alarm associated with theP < 0.01 and P < 0.05 confidence intervals listed in Table 1 have been computed by Monte-Carlo simulation on the basis of two experimental sequence tag distributions (Table2; Fig. 1). The rate of false alarms associated with the use of Equation (in fact, its cumulative form Equation 9, see Methods) is very small for genes represented by small tag counts and slowly increases for higher tag counts, without ever exceeding the selected significance level. Such good behavior validates the use of the confidence intervals (Table 1) computed from Equation and Equation 9 to assess the statistical significance of variations in digital Northern data. The curves labeled “window” characterize the very similar behavior of a slightly less conservative derivation of the same test (see Methods, Equation ). For comparison, Figure 1 also presents the behavior of another test, based on an inappropriate application of Ricker’s confidence intervals (Ricker 1937) (see Methods).
Publicly Available Distributions of Sequence Tags

Rate of false alarm computed according to the confidence intervals listed in Table 1. (Top) Monte-Carlo simulation of the random sampling of 840 tags distributed according to the data from Velculescu et al. (1995; see Table 2). (Bottom) Monte-Carlo simulation of the random sampling of 982 ESTs distributed according to the data fromOkubo et al. (1992; see Table 2). The frequency of false alarm was computed for two significance levels (2ε = 5%, leftand 2ε = 1%, right) and plotted in function of the tag class size (from 1–64 for Velculescu et al., from 1–22 for Okubo et al.). In all cases, the rate of false alarm increases up to a plateau for larger class sizes. The test (cumulative form of Equation) derived from the flat p(λ) prior shows perfect behavior with a maximal rate of false alarm always less than the significance levels (broken lines). The test (cumulative form of Equation ) derived from the window p(λ) prior exhibits a slightly higher rate of false alarms. Both versions of the test exhibit conservative behaviors for class size <5, with a false alarm rate even less than expected. In contrast, Ricker’s confidence intervals (Equation 12) are grossly inadequate and lead to false alarm rates up to four times the significance level. Graphs are computed from the analysis of 1000 repetitions of each experiment.
DISCUSSION
An appropriate statistical test is now at our disposal to begin analyzing digital gene expression profiles in a more quantitative way. For example, the test can be used to determine how many genes appear regulated at various confidence levels using the data from a typical experiment (e.g., sampling a thousand clones). We analyzed the data gathered by Okubo et al. (1995) on the human promyelocytic leukemia cell line HL60 induced by dimethylsulfoxide (DMSO) or tetradecanoylphorbolacetate (TPA). Table 3 shows the 21 EST classes the occurrences of which exhibit significant variations at the 1% level. Most of the corresponding genes make biological sense in term of differentiation along the granulocyte or monocyte pathways.
List of ESTs Exhibiting Significant (P < 0.01) Differences in Abundance in the HL60 Cell Line Induced by DMSO or TPA
This example serves to discuss a subtle point in the interpretation of the P values computed from Equation , 2, and 9. Rigorously, these equations apply to the case where a given gene (e.g., lipocortin) would have been selected for scrutiny before looking at the differences in cognate tag counts between libraries. When comparing two libraries without specifying in advance the transcripts we want to follow, and then focusing a posteriori on any of those exhibiting significant variations, the average number of expected false positiveN false isN false = PN species, whereN species is the number of different transcript species encountered and p is a given significance level. For instance, in the experiment analyzed in Table 3,N species is of the order of 600 (Okubo et al. 1995). It is therefore possible that up to four (600 × 7 × 10−3) out of the 21 transcript species listed in Table 3 are not truly differentially expressed.
Therefore, when two libraries are compared without prior gene selection, the use of a predetermined significance threshold is not advisable. The P values computed from Equation , 2, and 9 should simply be used to rank all observed variations by order of decreasing statistical significance (analogous to how “similarity hits” are listed after database searches). The end-users can then make their own choice about the number of candidate target genes to be retained from the top of the list, bearing in mind the corresponding number of expected false positives.
Although the present interpretation of a digital Northern focuses on the genes exhibiting the most spectacular differential expressions, there is already ample evidence that small changes can cause drastic effects. Disease states caused by haploinsufficiency and trisomy suggest that 2 → 1 or 2 → 3 proportional changes in expression level may be of biological significance. Table 1 shows that there is no theoretical limit to the detection of such small variations from the comparison of digital expression patterns. Simply, the sampling size has to be increased enough for the required numbers of cDNA tags to reach a significance threshold (for instance 40 → 60, for a confidence level of 95%).
Analog hybridization-based methods (Fodor et al. 1991; Lennon and Lehrach 1991; Gress et al. 1992; Southern et al. 1992; Guo et al. 1994;Matson et al. 1995; Nguyen et al. 1995; Schena et al. 1995; Zhao et al. 1995) are traditionally opposed to digital tag-counting methods (Okubo et al. 1992; Matsubara and Okubo 1994; Lee et al. 1995; Okubo et al. 1995; Velculescu et al. 1995) for the analysis of differential gene expression. Both types of methods are sensitive to the quality of the original messenger RNA preparation and/or cDNA libraries. Analog methods promise higher throughput, lower cost, and have the capacity of studying transcripts on a much wider scale of abundance. They are therefore expected to supersede digital methods. On the down side, however, hybridization signals are not easily reproducible, and can be affected by many unknown properties such as the cDNA library complexity, as well as clone and sequence specific features (e.g., insert size, nucleotide composition, presence of repeats, secondary structure, triple helix interaction, etc.). Therefore, the hybridization-based methods require an estimation of the dispersion of the signal associated with each clone (i.e., enough repetitions of each experiment), and multiple standardization and calibration procedures to allow the meaningful comparison of hybridization patterns obtained from various sources (tissues, cell types, etc.) or from different membranes or chips. This is far from routine and has yet to be worked out. In contrast, and thanks to the unique properties of the Poisson distribution, digital methods have the capacity of providing a quantitative assessment of differential expression without the repetition or the standardization of individual tag-counting experiments. The statistical analysis presented here provides an objective method to analyze digital transcript profile data, and adapts it to fit (1) the number of leads one wants to be followed; (2) the fraction of false clues to be tolerated; and (3) the level of modulation in gene expression considered of biological interest.
A program is available on our web site (http://igs-server.cnrs-mrs.fr) to compute the confidence intervals corresponding to arbitrary significance levels and sampling sizeN 1 and N 2.
METHODS
Let us denote p(x) the probability to observex sequence tags of the same gene (i.e., from the 3′ end of the same transcript) when N cDNA clones are picked randomly. For each transcript representing a small (i.e., less than 5%) fraction of the library and
N ⩾ 1000, p(x) will closely follow the Poisson distribution: where λ is the actual (albeit unknown) number of transcript of this type per N clones in the library. If we duplicate this experiment (i.e., once again randomly pick N clones of the same library and generate sequence tags), we will now observey occurrences of the same transcript. What is the probability of the various y values? An approximate solution consists in using x as the maximum likelihood estimate for λ and compute the probability for y occurrences given a Poisson distribution of mean λ = x:
where λ is the actual (albeit unknown) number of transcript of this type per N clones in the library. If we duplicate this experiment (i.e., once again randomly pick N clones of the same library and generate sequence tags), we will now observey occurrences of the same transcript. What is the probability of the various y values? An approximate solution consists in using x as the maximum likelihood estimate for λ and compute the probability for y occurrences given a Poisson distribution of mean λ = x:
 Equation is not symmetrical in x and y.This is an obvious flaw as the probability should not depend on which of the x or y values were observed first.p(y | x) = p(x | y) should hold provided that an equal number N of clones is sampled in both experiments. Equation is not the correct formula, because we have not yet taken into account
the fluctuation ofx around the unknown mean λ. To account for the fact that the actual value of λ is unknown, we have to integrate Equation over
all possible λ values:
Equation is not symmetrical in x and y.This is an obvious flaw as the probability should not depend on which of the x or y values were observed first.p(y | x) = p(x | y) should hold provided that an equal number N of clones is sampled in both experiments. Equation is not the correct formula, because we have not yet taken into account
the fluctuation ofx around the unknown mean λ. To account for the fact that the actual value of λ is unknown, we have to integrate Equation over
all possible λ values: p(d = λ | x) in Equation is the probability that the actual abundance of a given transcript is λ given that x occurrences of a cognate tag have been observed in one experiment. The second term in the integral is the probability of
drawing y occurrences given a Poisson distribution of mean λ:
p(d = λ | x) in Equation is the probability that the actual abundance of a given transcript is λ given that x occurrences of a cognate tag have been observed in one experiment. The second term in the integral is the probability of
drawing y occurrences given a Poisson distribution of mean λ: Using Bayes’ theoremp(d = λ | x) can be written as
Using Bayes’ theoremp(d = λ | x) can be written as To evaluate Equation , we need to define the prior distribution p(d = λ). The least constrained hypothesis (i.e., with the least information content), is to attribute an equal a priori probability
to all λ values in the [0, ∞] range. Incorporating such a flat prior in Equation leads to
To evaluate Equation , we need to define the prior distribution p(d = λ). The least constrained hypothesis (i.e., with the least information content), is to attribute an equal a priori probability
to all λ values in the [0, ∞] range. Incorporating such a flat prior in Equation leads to From the definition of the Γ function for integer arguments we observe that
From the definition of the Γ function for integer arguments we observe that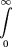 and finally obtain the expression given in Results:
and finally obtain the expression given in Results: This equation can be used in a wide variety of experimental situations. Equation defines the probability of observing xand y occurrences of the same rare event in duplicated experiments, regardless of the detailed probability distribution of those
events among the set of possible outcomes. In particular, in the context of transcription profiles,p(y | x) can be evaluated regardless of the distribution of each transcript (provided it is rare) within a cDNA library.
This equation can be used in a wide variety of experimental situations. Equation defines the probability of observing xand y occurrences of the same rare event in duplicated experiments, regardless of the detailed probability distribution of those
events among the set of possible outcomes. In particular, in the context of transcription profiles,p(y | x) can be evaluated regardless of the distribution of each transcript (provided it is rare) within a cDNA library.
To compute the confidence intervals listed in Table 1, we made use of the cumulative distributions: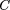
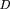 These equations allow the computation of an interval [y
min, y
max]εsuch asC(y y
min | x) ε andD(y ⩾ y
max | x) ε. Given that an event is observed x times in one experiment, the number y of occurrences of this event in a duplicate experiment is expected to fall within the interval [y
min, y
max]εwith a probability of 1–2ε. Equation 9, a and b, can therefore serve as a significance test when comparing, for instance,
the results of sampling N clones from two different libraries. For 2ε small (e.g., 5% or less), y values falling outside the [y
min, y
max]εinterval correspond top(y | x) << 1, and point out significant differences between the two experiments. They should include differentially expressed genes,
for example, for which λ is different in the two libraries.
These equations allow the computation of an interval [y
min, y
max]εsuch asC(y y
min | x) ε andD(y ⩾ y
max | x) ε. Given that an event is observed x times in one experiment, the number y of occurrences of this event in a duplicate experiment is expected to fall within the interval [y
min, y
max]εwith a probability of 1–2ε. Equation 9, a and b, can therefore serve as a significance test when comparing, for instance,
the results of sampling N clones from two different libraries. For 2ε small (e.g., 5% or less), y values falling outside the [y
min, y
max]εinterval correspond top(y | x) << 1, and point out significant differences between the two experiments. They should include differentially expressed genes,
for example, for which λ is different in the two libraries.
Generalization to Different Sampling Sizes
When different numbers of clones N
1 andN
2 are sequenced from the same library, Equation becomes where the two abundance values λ1 and λ2 are forced in the same ratio as N
1 andN
2. Using the same bayesian argument as before (Equation ) leads to
where the two abundance values λ1 and λ2 are forced in the same ratio as N
1 andN
2. Using the same bayesian argument as before (Equation ) leads to the last integral is simply
the last integral is simply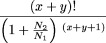 leading to the formula presented in the Results section:
leading to the formula presented in the Results section:
Ricker’s Confidence Interval
The confidence interval computed from Equation (and its cumulative form, Equation 9, a and b) is different from one introduced previously by Ricker (1937) although, at first, the two may appear to be related.
Given x occurrences of a sequence tag, Ricker’s formula defines a confidence interval [λmin, λmax]x for λ (again the actual number of transcripts of this type per N clones in the library) such as and
and where α is typically 5% or 1%. Ricker’s confidence intervals for various values of x are given in Table 1. Those intervals are close to those computed from Equation , but delineate the range of likely λ values, not y (the number of occurrences of the same event in a duplicated experiment). It is possible for xand y to fall outside each other’s Ricker’s confidence interval [λmin, λmax], while still being nonsignificant fluctuations around the same λ value. The confidence intervals computed from Equation
12, a and b, are therefore too narrow to properly define significant discrepancies between x andy. The false alarm rate associated with the use of Ricker’s confidence intervals is too high (Fig. 1).
where α is typically 5% or 1%. Ricker’s confidence intervals for various values of x are given in Table 1. Those intervals are close to those computed from Equation , but delineate the range of likely λ values, not y (the number of occurrences of the same event in a duplicated experiment). It is possible for xand y to fall outside each other’s Ricker’s confidence interval [λmin, λmax], while still being nonsignificant fluctuations around the same λ value. The confidence intervals computed from Equation
12, a and b, are therefore too narrow to properly define significant discrepancies between x andy. The false alarm rate associated with the use of Ricker’s confidence intervals is too high (Fig. 1).
However, an interesting use of Equation 12, a and b, is the estimation of the range of possible frequencies [λmin, λmax]x = 0 for cDNAs not yet encountered after picking N clones. For example, the 95% confidence interval is given by: That is, the abundance of a cDNA not picked up among one thousand clones is unlikely (5% chance) to be larger than 3.7/1000.
That is, the abundance of a cDNA not picked up among one thousand clones is unlikely (5% chance) to be larger than 3.7/1000.
Influence of the Prior Distribution
In the bayesian context, it is prudent to assess the influence of the prior hypothesis used to derive Equation and Equation
. The flatp(λ) prior allowing equiprobable λ values in the [0 , ∞] range might appear too broad and unrealistic. Nevertheless, it is
the most intuitively neutral distribution one can use. The quick convergence of the Poisson distribution rends the contribution
of extreme λ values negligible as soon as | λ − x | or | λ − y | increase. To verify this point, more reasonable distributions forp(λ) can be constructed by confining the accessible λ values within a window [λmin, λmax]x centered around the already observed value x. Such a window can for instance be Ricker’s confidence intervals as defined in the previous section (Equation 12, a and b).
We then confine the only permitted values of λ to be in this interval, with an equal probability; therefore, where H denotes the Heaviside function, the value of which is 1 for positive argument and 0 otherwise. Equation then becomes
where H denotes the Heaviside function, the value of which is 1 for positive argument and 0 otherwise. Equation then becomes with
with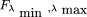 When λmin → 0 and λmax → ∞, we recover the initial Equation . We note in passing that the other limit, λmin = λmax = x, corresponds to the most stringent “Dirac prior”:
When λmin → 0 and λmax → ∞, we recover the initial Equation . We note in passing that the other limit, λmin = λmax = x, corresponds to the most stringent “Dirac prior”: forcing λ = x and turningp(y | x) into the simple Poisson distribution (Equation ).
forcing λ = x and turningp(y | x) into the simple Poisson distribution (Equation ).
The confidence intervals for the usual 1% and 5% significance levels are given in Table 1 for both the flat and the window priorp(d = λ). There is little difference, with the test derived from using a flat prior being a bit more conservative, as expected. On the down side, Figure 1 shows that the test derived from the window p(λ) prior gives rise to a higher rate of false alarm.
Acknowledgments
We thank Drs. J. Weissenbach, D. Gautheret, R. Ewing, and C. Abergel for critically reading the manuscript. This work was sponsored by a collaborative research grant from Incyte Pharmaceuticals, Inc.
The publication costs of this article were defrayed in part by payment of page charges. This article must therefore be hereby marked “advertisement” in accordance with 18 USC section 1734 solely to indicate this fact.
Footnotes
-
↵1 Corresponding author.
-
E-MAIL jmc{at}igs.cnrs-mrs.fr; FAX 334 91 16 45 49.
-
- Received March 12, 1997.
- Accepted August 22, 1997.
- Cold Spring Harbor Laboratory Press








