
Abstract
SNP heritability, the proportion of phenotypic variation explained by genotyped SNPs, is an important parameter in understanding the genetic architecture underlying various diseases and traits. Methods that aim to estimate SNP heritability from individual genotype and phenotype data are limited by their ability to scale to Biobank-scale data sets and by the restrictions in access to individual-level data. These limitations have motivated the development of methods that only require summary statistics. Although the availability of publicly accessible summary statistics makes them widely applicable, these methods lack the accuracy of methods that utilize individual genotypes. Here we present a SUMmary-statistics-based Randomized Haseman-Elston regression (SUM-RHE), a method that can estimate the SNP heritability of complex phenotypes with accuracies comparable to approaches that require individual genotypes, while exclusively relying on summary statistics. SUM-RHE employs Genome-Wide Association Study (GWAS) summary statistics and statistics obtained on a reference population, which can be efficiently estimated and readily shared for public use. Our results demonstrate that SUM-RHE obtains estimates of SNP heritability that are substantially more accurate compared with other summary statistic methods and on par with methods that rely on individual-level data.
The exponentially decreasing cost of genotyping and sequencing technologies has led to an increase in the number and size of biobanks (Bycroft et al. 2018; Johnson et al. 2023; Kurki et al. 2023), covering a wide range of populations. With large samples of phenotype and genotype data now available in these biobanks, one of the major analyses often performed is estimating heritability, defined as the phenotypic variance explained by the variance in the genotype (Falconer and Mackay 1996). Heritability estimates in these large data sets have allowed researchers to better delineate the scope of the role genetics play in complex traits, ranging from schizophrenia (Niarchou et al. 2020) to height (Yang et al. 2015), and have assisted investigations into their genetic architectures (Lappalainen et al. 2024). Most heritability estimation methods fit linear mixed models (LMMs) (Yang et al. 2011; Loh et al. 2015a,b) to map the variation in genotypes measured at single-nucleotide polymorphisms (SNPs) to the variation in phenotypes and thereby estimate the SNP heritability, that is, the proportion of phenotypic variance explained by genotyped SNPs. Given the high dimensionality of the genotypes and the large sample sizes of biobanks, fitting or parameter estimation in LMMs is computationally prohibitive. Many methods have been proposed to reduce computational complexity while retaining statistical accuracy (Yang et al. 2011; Zhou and Stephens 2012; Loh et al. 2015a,b; Zhou 2017; Wu and Sankararaman 2018; Pazokitoroudi et al. 2020). These methods, although highly accurate, generally take hours or days to run and require access to individual genotypes and phenotypes.
The rise of large-scale biobanks has also brought increased attention to the issue of genomic privacy owing to a surge in security breaches (Frizzo-Barker et al. 2016; Savatt et al. 2019; Akyüz et al. 2021). Consequently, additional measures have been implemented to safeguard individual information throughout its processing, storage, and sharing (Wan et al. 2022). Gaining access to raw individual-level data is now more challenging, exemplified by the UK Biobank's decision to restrict access to its WGS data to its cloud server (Deflaux et al. 2023). Given these developments, there is a growing preference for summary-statistics-based methods due to their portability and speed, even though they may sacrifice some statistical power compared with methods that use individual-level data (Bulik-Sullivan et al. 2015; Shi et al. 2016; Zhou 2017; Hou et al. 2019; Speed and Balding 2019). Such a loss in statistical power is particularly pronounced in smaller sample sizes and may result in inflated estimates of heritability owing to underestimation of linkage disequilibrium (LD) (Zhou 2017), even if correct reference summary statistics were used.
To address these challenges of heritability estimation in large biobanks, we propose SUMmary-statistics Randomized Haseman–Elston regression (SUM-RHE), by extending our previous work, Randomized Haseman–Elston regression (RHE) (Wu and Sankararaman 2018; Pazokitoroudi et al. 2020), to work exclusively on summary statistics. This adaptation leverages the observation that the trace estimates of the squared genetic relatedness matrix (GRM), which are needed to compute the method-of-moments (MoM) estimator underlying RHE, can be related to population-level parameters. By combining these trace estimates from a reference sample with Genome-Wide Association Study (GWAS) summary statistics from a target sample (consisting of individuals sampled from the same population as the reference sample), we can reconstruct the MoM estimates for the target sample without access to the individual data. In comprehensive simulations across various genetic architectures and scenarios, we show that SUM-RHE estimates are on par with methods that rely on individual-level data, and are substantially more accurate than popular summary statistic-based methods, all while exclusively utilizing summary statistics.
Methods
Background on heritability estimation and LMMs
Early attempts to calculate SNP heritability of complex traits by aggregating SNPs identified as GWAS-significant have revealed the issue of missing heritability, as this estimate of heritability was significantly lower than the narrow-sense heritability estimated in other studies (e.g., twin studies) (Manolio et al. 2009). The seminal work by Yang et al. (2010) reduced this discrepancy by jointly modeling all the SNPs, such that their effect sizes come from a distribution of some fixed variance that quantifies the genetic variation. In this LMM framework, the standardized phenotype vector y is modeled as a linear combination of SNP effect sizes β multiplied by the standardized genotype matrix X of M SNPs and N individuals with uniform noise ϵ:
One approach to estimating the variance components is to find the maximum likelihood estimator (MLE) and its variants, such as restricted maximum likelihood (REML) estimators (Yang et al. 2011; Loh et al. 2015b). These methods often rely on iterative optimizations, which tend to be inefficient, and could lead to biased estimates owing to the normality assumption (Zhou 2017; Wu and Sankararaman 2018). On the other hand, MoM approaches such as the Haseman–Elston regression (HE) (Haseman and Elston 1972; Sham and Purcell 2001), RHE (Wu and Sankararaman 2018; Pazokitoroudi et al. 2020), MQS (Zhou 2017), or LDSC (Bulik-Sullivan et al. 2015), only require solving the normal equations and do not make any assumptions on the underlying distribution D. Here, we briefly discuss the MoM estimator (HE), which sets the foundation for our work.
Heritability estimation from individual genotype data using MoM and randomized MoM
The HE MoM estimator of the parameters can be obtained by minimizing the discrepancy between the sample covariance and the population covariance matrices. The population covariance is given as
The biggest bottleneck in the equation is calculating . An exact calculation of the trace involves forming the matrix , which has a computational complexity of . Given M ≈ 1,000,000 and N ≈ 1,000,000, this is not tractable in modern biobanks. One of the main contributions of RHE-reg (Wu and Sankararaman 2018) and RHE-mc (Pazokitoroudi et al. 2020) is the efficient estimation of by leveraging the fact that the trace of can be approximated by a stochastic trace estimator (Girard 1989; Hutchinson 1989):
Extensive benchmarking of the RHE methods has shown that their performance is on par with other methods that require individual-level data, such as GCTA or BOLT-REML (Wu and Sankararaman 2018; Pazokitoroudi et al. 2020). RHE offers a distinct advantage over these likelihood-based methods, which tend to scale poorly, as well as other MoM approaches in terms of computational and memory efficiency (e.g., HE) or statistical efficiency (LDSC) (Pazokitoroudi et al. 2020). However, RHE is still limited in that it requires access to individual-level genotype and phenotype data, which restricts its applicability in cases in which such data are unavailable or only GWAS summary statistics are available.
Heritability estimation from summary statistics
In this work, we further extend RHE to work exclusively with GWAS summary statistics. Our key observation is the fact that the left-hand side (LHS) of the normal equations (Equation 3) is related to the LD in the population (Bulik-Sullivan 2015; Zhou 2017) and not the phenotype. Thus, if we can summarize the trace estimate for a reference sample drawn from a population, we can use these trace estimates to reconstruct the corresponding trace estimates for a target sample drawn from the same population. Indeed, we find that the expected value of the trace of can be related to the LD scores of the SNPs. Furthermore, the RHS of the normal equations can be computed from GWAS summary statistics obtained on the target population.
The LD score of a variant j is defined as the sum of squared correlation with all the variants,
For large sample sizes (N), we have
Substituting Equation 9 into Equation 8,
Let denote the GWAS effect size estimates for SNP j obtained by linear regression. Given the observed count Nj of the SNP, we have because the genotypes are standardized. The standard error of the GWAS estimate is . Thus, if we define the vector of adjusted z-scores,
Substituting Equations 10 and 11 into Equation 5 gives us
We propose releasing as “trace summaries,” which can then be combined with phenotype-specific GWAS summary statistics z to estimate heritability. The estimator in Equation 14 assumes that the was computed on the same genotypes used to generate the GWAS summary statistics. In settings in which cannot be computed on the same genotypes, we can use computed on a reference genotype data set drawn from a population that is similar to the population that was used to generate GWAS summary statistics (such as The 1000 Genomes Project). This is under the assumption that the LD structures of similar populations will also be related.
Estimating standard errors
To calculate the standard error of our estimator, we perform SNP-level block jackknife resampling, as done in RHE-mc (Pazokitoroudi et al. 2020). When generating the trace summaries with individual genotypes, we report the values estimated from jackknife subsamples. Excluding the same SNPs from the PLINK GWAS summary statistics, we can compute the denominator in Equation 14, , to get the jackknife replicate of :
Following the execution on all SNP blocks, we employ jackknife resampling to obtain SE estimates:
Results
Simulations under varied genetic architectures
We assessed the performance of SUM-RHE against methods that require individual genotypes—RHE (RHE-mc run with a single component), GCTA-GREML, and BOLT-REML—and methods that can work with summary statistics—LDSC and SumHer (Speed and Balding 2019)—on the task of estimating genome-wide heritability. We applied all methods to unrelated White British individuals genotyped on M = 454,207 common SNPs (MAF > 0.01 excluding SNPs in the MHC region) typed on the UK Biobank Axiom array. Because of the computational scalability of GCTA-GREML and BOLT-REML, we tested these and other methods in a small-scale setting in which the number of individuals in the target data set was set to Ntarget = 10,060 (we term this the 10k sample). In addition, we compared all the remaining methods in a large-scale setting in which the number of individuals in the target data set was set to Ntarget = 50,112 (termed the 50k sample). For the summary statistic methods, the GWAS summary statistics were computed on the target data sets. These methods also require population statistics, calculated in the remainder of the N = 291,273 unrelated White British individuals as the reference data set. For the small-scale simulation, the reference set has Nref = 281,213, and for the large-scale simulation, we set Nref = 241,161. On each of the reference sets, we generated SUM-RHE trace summary statistics, LDSC reference LD scores, and LDAK SNP taggings.
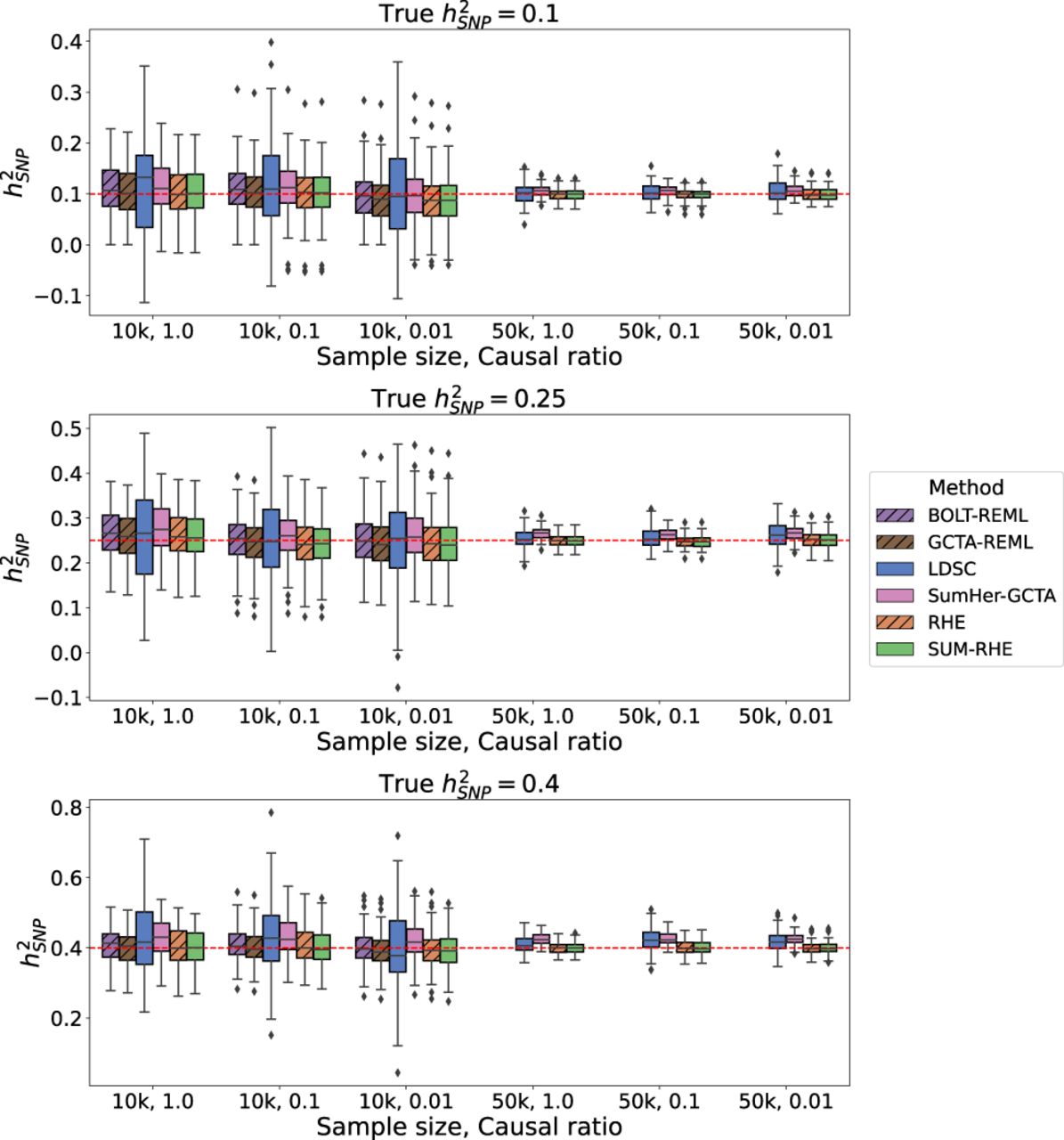
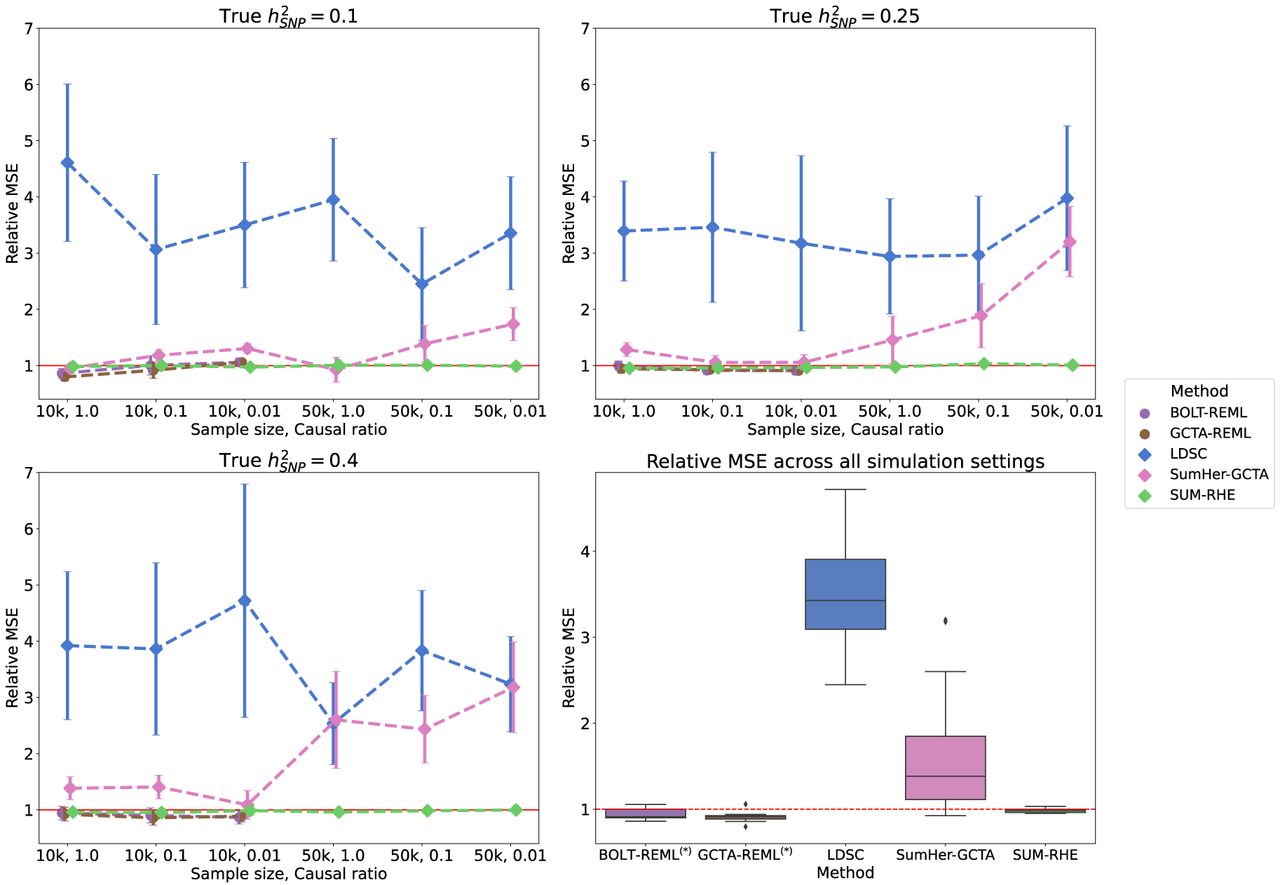
We then simulated phenotypes corresponding to nine different genetic architectures: and causal ratio P = 1.0, 0.1, 0.01 (where the causal ratio represents the proportion of variants with non-zero effects), each with 100 replicates. Table 1 summarizes the inputs for each method: For the calculation of LDSC LD scores, we used the entire Nref reference sample with a window size of 2 Mb. SUM-RHE trace summaries were calculated by aggregating the trace estimates of 25 runs on the reference set with B = 100 (equivalent to stochastic trace estimation with random vectors) (for more information, see Supplemental Fig. S2) and 1000 jackknife blocks, yielding a single trace summary statistic with 1000 jackknife estimates of . SumHer was run assuming the GCTA model to calculate the SNP taggings (consistent with the genetic architecture assumed in our simulations). RHE was run with B = 100 and 1000 jackknife blocks as well. BOLT-REML/GCTA-GREML was run with default parameter settings. GWAS summary statistics for each simulated phenotype were generated using PLINK 2.0. Figure 1 summarizes the heritability estimates on the target data. Across the 18 different settings (genetic architectures and sample sizes) we tested, we found that the accuracy of SUM-RHE was comparable to RHE (Fig. 1) with the mean-squared error of SUM-RHE close to one relative to RHE, despite relying only on the summary statistics (Fig. 2; for the MSE of each method, see Supplemental Fig. S1).
Comparison of SNP heritability estimates across methods. SUM-RHE heritability estimates are comparable to those from RHE or BOLT-REML/GCTA-GREML and are significantly more accurate than those of LDSC and SumHer. Because of computational limitations, BOLT-REML/GCTA-GREML was not run on the N = 50k simulations. Dashed hatches denote individual-level data methods.
Mean squared error (MSE) of heritability estimates of each method relative to RHE. The dot and error bar denote the relative MSE and the 95% CI calculated based on bootstrap resampling (using 10,000 bootstrap samples), respectively. Although the MSE of SUM-RHE is within ±5% of the MSE of RHE, the MSE of LDSC ranges from 245% to 472%, whereas the MSE of SumHer-GCTA ranges from 92% to 320%. (Diamond) BOLT-REML and GCTA-GREML have relative MSE in the range of 80% and 106% for the 10k samples and were not benchmarked on the 50k samples.
Inputs for the different methods evaluated
| Method | BOLT/GCTA-GREML, RHE | SUM-RHE | LDSC | SumHer |
|---|---|---|---|---|
| Inputs | Individual genotype | Ref. trace | Ref. LD scores | Ref. SNP tag |
| Individual phenotype | GWAS summary | GWAS summary | GWAS summary |
[i] LDSC and SUM-RHE rely only on the summary statistics, whereas GCTA-GREML, BOLT-REML, and RHE require individual data for target genotypes and phenotypes.
SUM-RHE has substantially improved accuracy over other summary-statistic-based methods: LDSC exhibits MSE ranging from 244% to 478% relative to that of SUM-RHE (mean: 356%), whereas SumHer-GCTA has MSE ranging from 94% to 331% relative to that of SUM-RHE (mean: 167%). SumHer-GCTA has lower MSE than SUM-RHE for low heritability (h2 = 0.1) and high polygenicity (causal ratio, P = 1.0). The improvement in MSE is particularly pronounced with smaller sample sizes (N = 10,060).
We also tested the calibration of SUM-RHE by simulating phenotypes with and testing the hypothesis of with a rejection threshold of α = 0.05 for both N = 10,060 and N = 50,112 to find that SUM-RHE is well calibrated (Table 2).
Calibration of the methods
| Method | Sample | BOLT-REML | GCTA-GREML | LDSC | SumHer-GCTA | SUM-RHE | RHE |
|---|---|---|---|---|---|---|---|
| Bias | 10k | 0.0247 | 0.0219 | 0.0084 | 0.0095 | 0.0058 | 0.0047 |
| 50k | — | — | 0.0019 | 0.0005 | −0.0002 | −0.0002 | |
| SE | 10k | 0.0020 | 0.0020 | 0.0101 | 0.0031 | 0.0045 | 0.0045 |
| 50k | — | — | 0.0019 | 0.0006 | 0.0010 | 0.0010 | |
| FPR | 10k | 0.15 | 0.14 | 0.04 | 0.06 | 0.06 | 0.05 |
| 50k | — | — | 0.03 | 0.05 | 0.06 | 0.06 |
[i] We report the bias, SE, and the false-positive rate (FPR) of each method in the setting in which . Because of computational limitations, GCTA-GREML and BOLT-REML were only run on 10k samples.
Simulations with a mixture model
We further test the robustness of our method by simulating phenotypes with a combination of large- and small-effect SNPs. We selected the first π = 0.05 of the SNPs to account for γ = 0.25 of the total SNP heritability, whereas the rest of the SNPs accounted for the remainder. The causal SNPs were then selected at random with fixed probability α, such that the effect sizes for the large-effect SNPs were sampled from a different distribution than for the small-effect SNPs. Specifically, the effect sizes were sampled from two distributions:
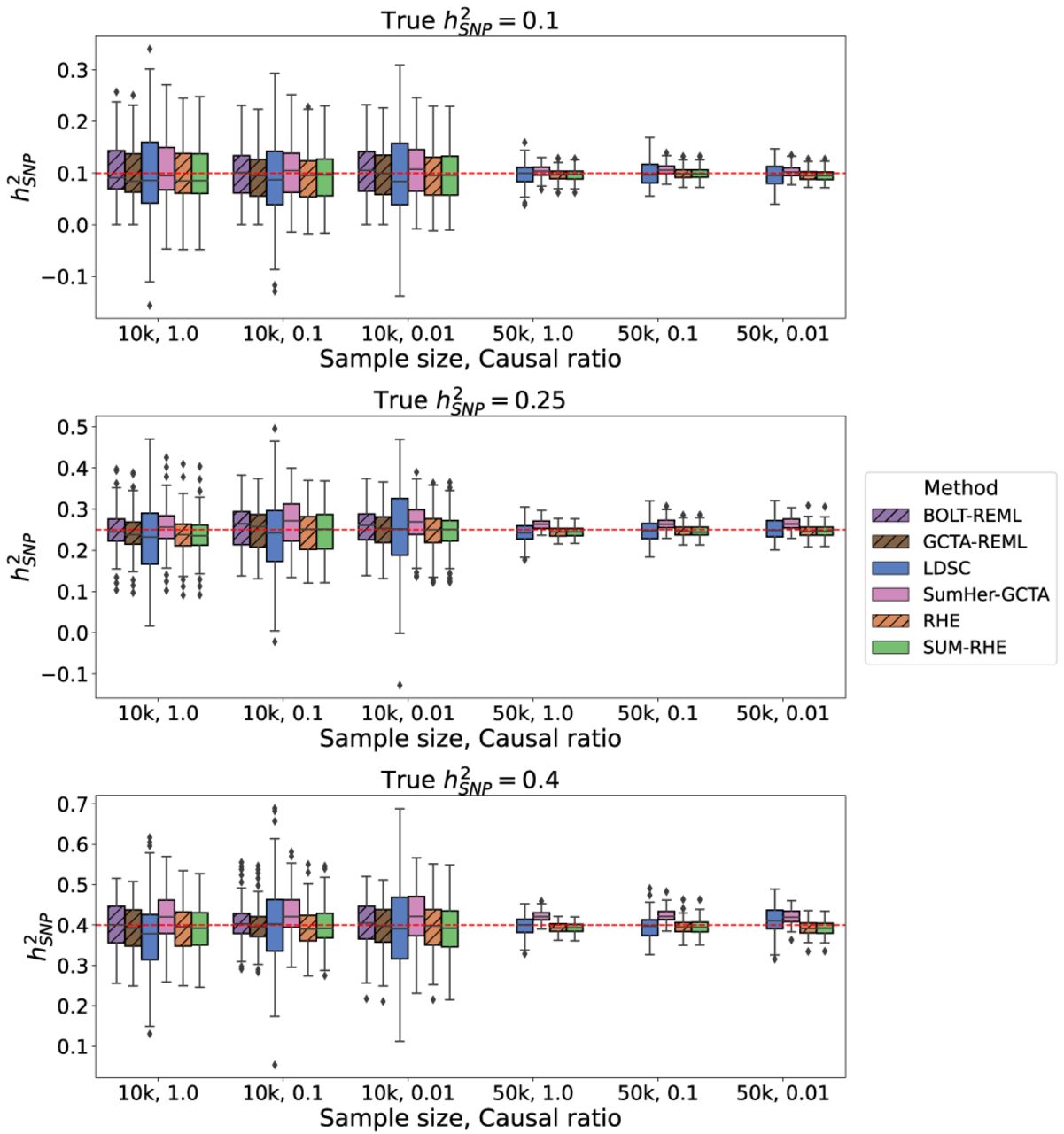
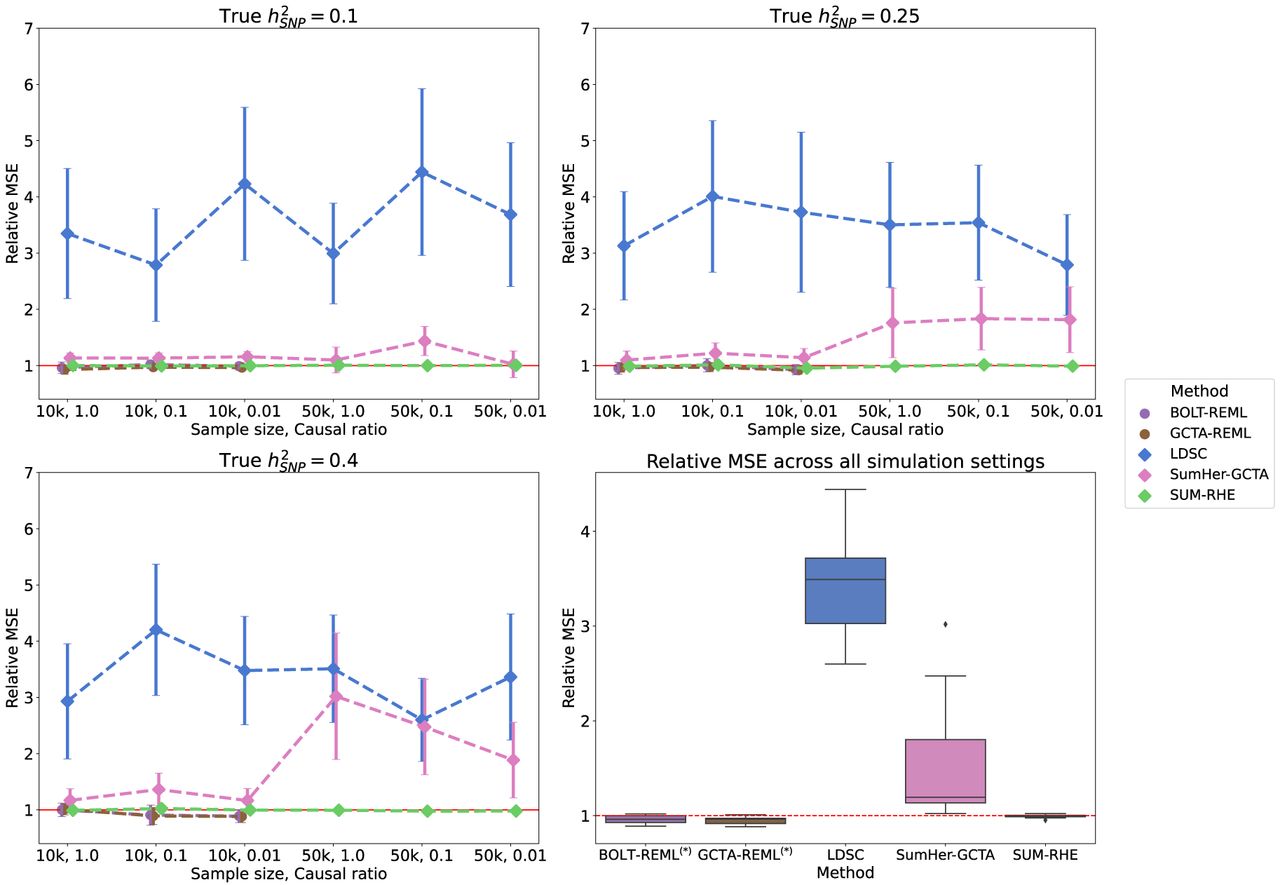
Figure 3 shows the boxplots of estimates from LDSC, SumHer-GCTA, SUM-RHE, and RHE, whereas Figure 4 plots the SE and MSE of the three summary-statistics methods (LDSC, SumHer-GCTA, SUM-RHE) relative to that of RHE. We observe that both LDSC and SumHer-GCTA show larger MSEs than SUM-RHE, similar to our previous simulations. LDSC has a MSE in the range of 266% to 444% relative to that of SUM-RHE (mean: 348%), and SumHer has a MSE in 102% to 304% (mean: 151%). These results indicate that SUM-RHE is robust under the mixture model simulations and attains accuracy comparable to individual-level methods across the scenarios we tested.
Comparison of SNP heritability estimates across methods on simulations with mixtures of large and small genetic effects.
Comparison of MSE and SE of the summary-statistics-based methods against RHE on simulations with mixtures of large and small genetic effects. Here we report the relative MSE of the five methods on the mixture-of-effect simulations. Their performances are similar to those in the previous simulations (Fig. 2). SUM-RHE has an MSE within ±5% relative to RHE.
Runtime measurements
We compared the runtime of SUM-RHE to other methods (Table 3). The heritability estimation step for all the summary statistic methods is computationally efficient irrespective of sample size. The generation of the reference statistics will depend on the size of the reference data set but is typically a one-time computation that is relatively efficient even for data sets with hundreds of thousands of individuals with access to a compute cluster.
Runtime estimates of the six methods
| Step | Sample | BOLT-REML | GCTA-GREML | RHE | SUM-RHE | LDSC | SumHer |
|---|---|---|---|---|---|---|---|
| Reference statistic estimation | 281k | — | — | — | 14,286.4 | 3120.8 | 697.3 |
| GWAS summary | 10k | — | — | — | 7.0 | 7.0 | 7.0 |
| Heritability estimation | 10k | 589.6 | 847.3 | 590.6 | 1.6 | 4.0 | 2.9 |
| Reference statistic estimation | 241k | — | — | — | 14,686.0 | 2699.9 | 1180.7 |
| GWAS summary | 50k | — | — | — | 17.9 | 17.9 | 17.9 |
| Heritability estimation | 50k | — | — | 3032.6 | 1.3 | 4.0 | 1.6 |
[i] We ran each method on 10 replicates to measure wall clock time. For methods or tools that allow multithreading (BOLT/GCTA-GREML, SumHer, PLINK 2.0), we used six threads, run on the UCLA Hoffman2 computing nodes. SUM-RHE trace summaries were estimated by running the original RHE-mc codes (which does not support multithreading). PLINK 2.0 was used for calculating the GWAS summary statistics. All measurements are in seconds.
Application to traits in the UK Biobank
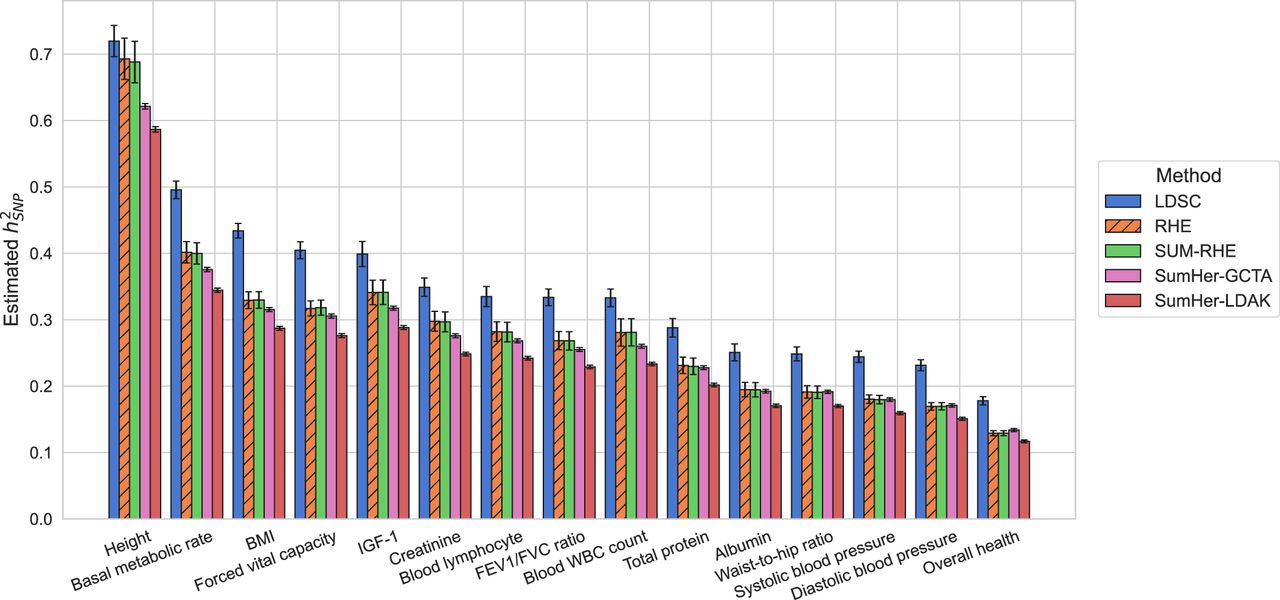
Finally, we applied three of the summary statistic methods as well as one of the scalable individual genotype-based method (RHE) to real UK Biobank phenotypes measured on N = 291,273 unrelated White British individuals paired with genotypes assayed on 454,207 common array SNPs (we ran SumHer with both GCTA and LDAK SNP taggings for real phenotypes). Here we plot the 15 quantitative traits with the highest z-scores of SUM-RHE heritability estimates, from overall health (z = 34.3) to albumin (z = 17.9), ordered by the heritability estimates. For the summary-statistics-based methods (LDSC, SUM-RHE, SumHer-LDAK/GCTA), we use in-sample statistics.
As expected, SUM-RHE has estimates that agree well with RHE estimates (Fig. 5). SUM-RHE estimates tend to lie in between those from LDSC and SumHer (with both GCTA and LDAK SNP taggings), consistent with our previous work (Pazokitoroudi et al. 2020).
Discussion
Here we propose a summary-statistics-based heritability estimation method, SUM-RHE, that has performance comparable to that of individual genotype-based methods. SUM-RHE is accurate, fast, and highly portable. It uses a trace summary statistic calculated by aggregating stochastic trace estimates and PLINK GWAS statistics. In the era of large biobanks, SUM-RHE will be a useful tool in estimating heritability while maintaining the privacy of the patients.
We conclude with a discussion of limitations and directions for future work. First, heritability estimates from SUM-RHE are accurate under the assumption that the summary statistics are free of confounding owing to population stratification and cryptic relatedness. In a setting in which the summary statistics are affected by confounders, LDSC could potentially be more robust (as confounding would affect the intercept of LDSC whereas the slope would provide a robust estimator of heritability). Second, our preliminary experiments suggest that SUM-RHE retains its accuracy even when reference trace estimates are computed using a smaller number of random vectors on a smaller number of individuals (as low as Nref = 30k and B = 1000) (see Supplemental Fig. S2). These results suggest that the computation of trace summaries can be even more efficient. Third, SUM-RHE is not applicable to the setting of MAF and LD-dependent architectures, nor does it estimate partitioned or local heritability. These applications will require computation and release of partitioned trace summaries. We view this as a promising direction for future work.
Software availability
SUM-RHE source code is available at GitHub (https://github.com/sriramlab/SUMRHE) and as Supplemental Code. Access to the UK Biobank data (genotype and phenotypes measured at baseline) requires an approved application. Details on the application and approval process can be found at https://www.ukbiobank.ac.uk/enable-your-research/apply-for-access.
Competing interest statement
The authors declare no competing interests.
Acknowledgments
This research was conducted using the UK Biobank Resource under application 33127. We thank the participants of UK Biobank for making this work possible. This work was supported by the National Institutes of Health (GM125055, HG006399) and the National Science Foundation (CAREER-1943497).
Author contributions: S.S. conceived and supervised the project. M.J., A.P., and S.S. developed the methods. M.J. and S.S. wrote the manuscript. M.J. and Z.L. wrote the software code and performed the analyses. All authors read, reviewed, and approved the final manuscript.
Notes
[4] Supplementary material [Supplemental material is available for this article.]
[5] Article published online before print. Article, supplemental material, and publication date are at https://www.genome.org/cgi/doi/10.1101/gr.279207.124.
[6] Freely available online through the Genome Research Open Access option.
References
- ↵Akyüz K, Chassang G, Goisauf M, Kozera L, Mezinska S, Tzortzatou O, Mayrhofer MT. 2021. Biobanking and risk assessment: a comprehensive typology of risks for an adaptive risk governance. Life Sci Soc Policy 17: 10. 10.1186/s40504-021-00117-7
- ↵Bulik-Sullivan B. 2015. Relationship between LD score and Haseman-Elston regression. bioRxiv 10.1101/018283
- ↵Bulik-Sullivan BK, Loh PR, Finucane HK, Ripke S, Yang J, of the Psychiatric Genomics Consortium SWG, Patterson N, Daly MJ, Price AL, Neale BM. 2015. LD score regression distinguishes confounding from polygenicity in genome-wide association studies. Nat Genet 47: 291–295. 10.1038/ng.3211
- ↵Bycroft C, Freeman C, Petkova D, Band G, Elliott LT, Sharp K, Motyer A, Vukcevic D, Delaneau O, O'Connell J, 2018. The UK Biobank resource with deep phenotyping and genomic data. Nature 562: 203–209. 10.1038/s41586-018-0579-z
- ↵Deflaux N, Selvaraj MS, Condon HR, Mayo K, Haidermota S, Basford MA, Lunt C, Philippakis AA, Roden DM, Denny JC, 2023. Demonstrating paths for unlocking the value of cloud genomics through cross cohort analysis. Nat Commun 14: 5419. 10.1038/s41467-023-41185-x
- ↵Falconer DS, Mackay TFC. 1996. Introduction to quantitative genetics, 4th ed. Longmans Green, Harlow, Essex, UK.
- ↵Frizzo-Barker J, Chow-White PA, Charters A, Ha D. 2016. Genomic big data and privacy: challenges and opportunities for precision medicine. Comput Support Coop Work 25: 115–136. 10.1007/s10606-016-9248-7
- ↵Girard A. 1989. A fast ‘Monte-Carlo cross-validation’ procedure for large least squares problems with noisy data. Numer Math 56: 1–23. 10.1007/BF01395775
- ↵Haseman J, Elston R. 1972. The investigation of linkage between a quantitative trait and a marker locus. Behav Genet 2: 3–19. 10.1007/BF01066731
- ↵Hou K, Burch KS, Majumdar A, Shi H, Mancuso N, Wu Y, Sankararaman S, Pasaniuc B. 2019. Accurate estimation of SNP-heritability from biobank-scale data irrespective of genetic architecture. Nat Genet 51: 1244–1251. 10.1038/s41588-019-0465-0
- ↵Hutchinson MF. 1989. A stochastic estimator of the trace of the influence matrix for Laplacian smoothing splines. Commun Stat -Simul Comput 18: 1059–1076. 10.1080/03610918908812806
- ↵Johnson R, Ding Y, Bhattacharya A, Knyazev S, Chiu A, Lajonchere C, Geschwind DH, Pasaniuc B. 2023. The UCLA ATLAS community health initiative: promoting precision health research in a diverse biobank. Cell Genom 3: 100243. 10.1016/j.xgen.2022.100243
- ↵Kurki MI, Karjalainen J, Palta P, Sipilä TP, Kristiansson K, Donner KM, Reeve MP, Laivuori H, Aavikko M, Kaunisto MA, 2023. FinnGen provides genetic insights from a well-phenotyped isolated population. Nature 613: 508–518. 10.1038/s41586-022-05473-8
- ↵Lappalainen T, Li YI, Ramachandran S, Gusev A. 2024. Genetic and molecular architecture of complex traits. Cell 187: 1059–1075. 10.1016/j.cell.2024.01.023
- ↵Liberty E, Zucker SW. 2009. The Mailman algorithm: a note on matrix–vector multiplication. Inf Process Lett 109: 179–182. 10.1016/j.ipl.2008.09.028
- ↵Loh PR, Bhatia G, Gusev A, Finucane HK, Bulik-Sullivan BK, Pollack SJ, Schizophrenia Working Group of the Psychiatric Genomics Consortium, de Candia TR, Lee SH, Wray NR, 2015a. Contrasting genetic architectures of schizophrenia and other complex diseases using fast variance-components analysis. Nat Genet 47: 1385–1392. 10.1038/ng.3431
- ↵Loh PR, Tucker G, Bulik-Sullivan BK, Vilhjálmsson BJ, Finucane HK, Salem RM, Chasman DI, Ridker PM, Neale BM, Berger B, 2015b. Efficient Bayesian mixed-model analysis increases association power in large cohorts. Nat Genet 47: 284–290. 10.1038/ng.3190
- ↵Manolio TA, Collins FS, Cox NJ, Goldstein DB, Hindorff LA, Hunter DJ, McCarthy MI, Ramos EM, Cardon LR, Chakravarti A, 2009. Finding the missing heritability of complex diseases. Nature 461: 747–753. 10.1038/nature08494
- ↵Niarchou M, Byrne EM, Trzaskowski M, Sidorenko J, Kemper KE, McGrath JJ, O'Donovan MC, Owen MJ, Wray NR. 2020. Genome-wide association study of dietary intake in the UK Biobank study and its associations with schizophrenia and other traits. Transl Psychiatry 10: 51. 10.1038/s41398-020-0688-y
- ↵Pazokitoroudi A, Wu Y, Burch KS, Hou K, Zhou A, Pasaniuc B, Sankararaman S. 2020. Efficient variance components analysis across millions of genomes. Nat Commun 11: 4020. 10.1038/s41467-020-17576-9
- ↵Savatt J, Pisieczko CJ, Zhang Y, Lee MT, Faucett WA, Williams JL. 2019. Biobanks in the era of genomic data. Curr Genet Med Rep 7: 153–161. 10.1007/s40142-019-00171-w
- ↵Sham PC, Purcell S. 2001. Equivalence between Haseman-Elston and variance-components linkage analyses for sib pairs. Am J Hum Genet 68: 1527–1532. 10.1086/320593
- ↵Shi H, Kichaev G, Pasaniuc B. 2016. Contrasting the genetic architecture of 30 complex traits from summary association data. Am J Hum Genet 99: 139–153. 10.1016/j.ajhg.2016.05.013
- ↵Speed D, Balding DJ. 2019. SumHer better estimates the SNP heritability of complex traits from summary statistics. Nat Genet 51: 277–284. 10.1038/s41588-018-0279-5
- ↵Wan Z, Hazel JW, Clayton EW, Vorobeychik Y, Kantarcioglu M, Malin BA. 2022. Sociotechnical safeguards for genomic data privacy. Nat Rev Genet 23: 429–445. 10.1038/s41576-022-00455-y
- ↵Wu Y, Sankararaman S. 2018. A scalable estimator of SNP heritability for biobank-scale data. Bioinformatics 34: i187–i194. 10.1093/bioinformatics/bty253
- ↵Yang J, Benyamin B, McEvoy BP, Gordon S, Henders AK, Nyholt DR, Madden PA, Heath AC, Martin NG, Montgomery GW, 2010. Common SNPs explain a large proportion of the heritability for human height. Nat Genet 42: 565–569. 10.1038/ng.608
- ↵Yang J, Lee SH, Goddard ME, Visscher PM. 2011. GCTA: a tool for genome-wide complex trait analysis. Am J Hum Genet 88: 76–82. 10.1016/j.ajhg.2010.11.011
- ↵Yang J, Bakshi A, Zhu Z, Hemani G, Vinkhuyzen AA, Lee SH, Robinson MR, Perry JR, Nolte IM, van Vliet-Ostaptchouk JV, 2015. Genetic variance estimation with imputed variants finds negligible missing heritability for human height and body mass index. Nat Genet 47: 1114–1120. 10.1038/ng.3390
- ↵Zhou X. 2017. A unified framework for variance component estimation with summary statistics in genome-wide association studies. Ann Appl Stat 11: 2027. 10.1214/17-AOAS1052
- ↵Zhou X, Stephens M. 2012. Genome-wide efficient mixed-model analysis for association studies. Nat Genet 44: 821–824. 10.1038/ng.2310