
Recent advances in methods to characterize archaic introgression in modern humans
- David Peede1,2,3,
- Mayra M. Bañuelos1,2,
- Jazeps Medina Tretmanis2,
- Miriam Miyagi2,4 and
- Emilia Huerta-Sánchez1,2,5
- 1Department of Ecology, Evolution, and Organismal Biology, Brown University, Providence, Rhode Island 02912, USA;
- 2Center for Computational Molecular Biology, Brown University, Providence, Rhode Island 02912, USA;
- 3Institute at Brown for Environment and Society, Brown University, Providence, Rhode Island 02912, USA;
- 4Studies of Women, Gender, and Sexuality, Harvard University, Cambridge, Massachusetts 02138, USA;
- 5Data Science Institute, Brown University, Providence, Rhode Island 02912, USA
Abstract
The exchange and subsequent incorporation of genetic material between distinct lineages, known as introgression, has emerged as a crucial concept in understanding human evolutionary history. With the advent of high-throughput sequencing technologies and the publication of the draft Neanderthal genome in 2010, Green and colleagues were able to demonstrate the presence of Neanderthal DNA in present-day Eurasians, a signature of past interbreeding events with archaic humans. This integration of genetic material from extinct human relatives, such as Neanderthals and Denisovans, into the genomes of modern humans due to historical gene flow events is known as archaic introgression. As new methods and data sets uncover a more complex intermingling between our ancestors and archaic humans than previously thought, the relevance of archaic introgression has only increased, opening exciting new avenues for studying human evolution. Here, we review recent methodological advances in the study of archaic introgression. We begin by providing an overview of the genealogical and genomic signatures left behind by introgression events before reviewing recent methods for studying archaic introgression by outlining their conceptual approaches, data requirements, and types of inferences they support. Finally, we provide recommendations for which methods are most appropriate given a research question and data set, discuss outstanding challenges, and suggest future lines of research to advance the study of archaic introgression.
Prior to high-throughput sequencing, whether archaic humans (e.g., Neanderthals and Denisovans) contributed to the modern human gene pool was hotly debated (Stringer and Andrews 1988; Wolpoff et al. 1994; Stringer 2022). Early analyses of mitochondrial DNA suggested minimal to no Neanderthal contribution to the genetic diversity of modern human populations (Krings et al. 1997, 1999; Caramelli et al. 2003; Currat and Excoffier 2004; Serre et al. 2004). However, in 2010, the publication of the draft Neanderthal genome revealed that non-African populations harbor 1%–4% Neanderthal ancestry (Green et al. 2010). Later that year, a finger bone from Siberia revealed a new archaic human group, the Denisovans, who also interbred with early modern humans (Reich et al. 2010). In contrast to the global distribution of Neanderthal ancestry, Denisovan ancestry occurs at lower levels in most non-African populations, except for Oceanic populations with 4%–6% Denisovan ancestry (Reich et al. 2010, 2011; Meyer et al. 2012). Following thorough investigations of alternative explanations for this signal (Currat and Excoffier 2011; Eriksson and Manica 2012; Yang et al. 2012; Eriksson and Manica 2014; Lohse and Frantz 2014), it is now commonly accepted that archaic and modern human populations interbred at various points in our evolutionary history, and by studying the extent of archaic introgression across global populations (Green et al. 2010; Reich et al. 2010; Meyer et al. 2012; Prüfer et al. 2014; The 1000 Genomes Project Consortium 2015; Mallick et al. 2016; Prüfer et al. 2017; Bergström et al. 2020; Mafessoni et al. 2020; Byrska-Bishop et al. 2022), researchers began to assemble more refined models of human evolutionary history (Wall et al. 2013; Malaspinas et al. 2016; Sankararaman et al. 2016; Vernot et al. 2016; McColl et al. 2018; Bergström et al. 2020; Skov et al. 2020; Witt et al. 2022; Chevy et al. 2023; Iasi et al. 2024; Liu et al. 2024b; Kerdoncuff et al. 2025).
Building on these findings, researchers began to localize introgressed segments and infer demographic parameters such as archaic population sizes and the timing and number of gene flow events (Sankararaman et al. 2012, 2014; Vernot and Akey 2014, 2015; Moorjani et al. 2016; Browning et al. 2018; Steinrücken et al. 2018; Jacobs et al. 2019; Villanea and Schraiber 2019; Massilani et al. 2020; Carlhoff et al. 2021; Choin et al. 2021; Iasi et al. 2021; Larena et al. 2021; Yuan et al. 2021; Chintalapati et al. 2022; Iasi et al. 2024; Li et al. 2024; Kerdoncuff et al. 2025; Sümer et al. 2025). While the precise number of Neanderthal and Denisovan introgression events is an active area of research, there is a growing consensus that multiple waves of archaic introgression have occurred throughout human evolution (for a more detailed discussion, see Gokcumen 2020; Sankararaman 2020; Ahlquist et al. 2021; Gopalan et al. 2021; Reilly et al. 2022; Ongaro and Huerta-Sanchez 2024; Peyrégne et al. 2024; Tagore and Akey 2025). This work also uncovered genomic regions devoid of any archaic ancestry (“introgression deserts”), which commonly reside in regions of high gene density or low recombination (Sankararaman et al. 2014; Vernot and Akey 2014; Sankararaman et al. 2016; Vernot et al. 2016; Schumer et al. 2018; Steinrücken et al. 2018; Chen et al. 2020; Skov et al. 2020; Kerdoncuff et al. 2025). This nonuniform distribution of archaic ancestry likely resulted from natural selection rapidly purging introgressed variants due to the higher mutational load in archaic populations (Harris and Nielsen 2016; Juric et al. 2016; Peter 2016; Schumer et al. 2018; Veller et al. 2023). Despite this trend, studies have shown that archaic ancestry conferred selective advantages in specific environmental or genetic contexts (Racimo et al. 2015; Dannemann and Racimo 2018). This phenomenon of adaptive introgression highlights archaic introgression as an alternative source of new genetic variation, as opposed to de novo mutations, potentially aiding early human populations in adapting to new environments (Racimo et al. 2015; Edelman and Mallet 2021). Classic examples include high-altitude adaptation in Tibetans facilitated by Denisovan-like introgression at EPAS1 (Huerta-Sánchez et al. 2014; Zhang et al. 2021), as well as loci affecting skin pigmentation (Ding et al. 2014b; Sankararaman et al. 2014; Vernot and Akey 2014; Gittelman et al. 2016; Dannemann and Kelso 2017; Racimo et al. 2017), immune function (Mendez et al. 2012, 2013; Sankararaman et al. 2014; Dannemann et al. 2016; Gittelman et al. 2016; Sams et al. 2016; Enard and Petrov 2018; Zhou et al. 2021; Vespasiani et al. 2022; Yermakovich et al. 2024), and dietary adaptations (Khrameeva et al. 2014; Racimo et al. 2017; Setter et al. 2020).
Studying archaic introgression presents unique challenges, particularly because of the limitations of ancient DNA (aDNA) sequencing. Although extensive genomic data exists for modern populations (The 1000 Genomes Project Consortium 2015; Mallick et al. 2016; Bergström et al. 2020; Byrska-Bishop et al. 2022), high-coverage archaic genomes are limited to three Neanderthals (Prüfer et al. 2014, 2017; Mafessoni et al. 2020) and one Denisovan (Meyer et al. 2012). Complementary low-coverage archaic genomes have refined the chronology of archaic introgression while providing a new lens into the social and population structure of archaic populations (Hajdinjak et al. 2018; Bokelmann et al. 2019; Vernot et al. 2021; Skov et al. 2022; Slimak et al. 2024). However, the characteristics of aDNA (e.g., fragmentation, postmortem damage, and contamination) complicate genotype calling and preclude haplotype phasing (Noonan et al. 2006; Skoglund et al. 2014; Orlando et al. 2021). Moreover, the available archaic samples likely represent only a fraction of the genetic diversity present in the true source populations (Green et al. 2010; Reich et al. 2010; Hajdinjak et al. 2018; Bokelmann et al. 2019; Vernot et al. 2021; Skov et al. 2022; Slimak et al. 2024). The methods reviewed here were developed to constrain the signal of archaic introgression while accounting for these technical and biological complexities.
The genealogical and genomic signals of introgression
For introgression to occur, two populations must be sympatric (i.e., inhabiting the same geographic region) at some point in their shared history, creating opportunities for interbreeding (Fig. 1A). Hybridization produces first-generation offspring that inherit a uniform mixture of ancestry from both parental populations; however, introgressed segments become established only after repeated backcrossing over subsequent generations (Fig. 1A). Recombination progressively shortens these segments, resulting in an inverse relationship between segment length and time of gene flow (Chakraborty and Weiss 1988; Pool and Nielsen 2009; Gravel 2012; Liang and Nielsen 2014). Therefore, the distribution of introgressed segment lengths is informative regarding the timing of gene flow events (Pugach et al. 2011; Sankararaman et al. 2012; Moorjani et al. 2016; Ni et al. 2016; Corbett-Detig and Nielsen 2017; Jacobs et al. 2019; Shchur et al. 2020; Iasi et al. 2021; Di Santo et al. 2023; Iasi et al. 2024).
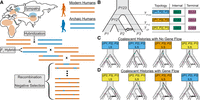
The genomic and genealogical signals of introgression. (A) Schematic of the introgression process, where some modern human populations (vermilion) migrated out of Africa, came into contact with archaic humans (blue) in Eurasia followed by subsequent interbreeding events. Over many generations, archaic segments are broken down due to recombination, purged due to negative selection, and incorporated into the genomes of present-day modern humans. (B) Instantaneous Unidirectional Admixture (IUA) model for studying introgression from a donor population (P3) into a hypothesized recipient population (P2) where P1 represents a control population assumed to have no genetic contributions from P3. In this model, the ancestral relationships are traced for a single lineage per population resulting in eight unique coalescent histories with only three possible topologies, that is, branching orders among lineages. Coalescent histories where P1 and P2 coalesce first, P1 and P3 coalesce first, and P2 and P3 coalesce first are depicted in sky blue, orange, and yellow; respectively. Under the IUA model, a site pattern is defined by the configuration of ancestral (A) and derived alleles (B) at a given site for the ordered set {P1, P2, P3, O}, where O represents an outgroup population used to polarized ancestral states in practice. Each topology will result in one unique site pattern resulting from a mutation occurring on the internal branch (green stars), while all topologies can generate three additional site patterns resulting from a mutation occurring on one of the three terminal branches (pink stars). (C) In the absence of gene flow, there are four unique coalescent histories under the IUA model, one with a history of lineage sorting (LS) between P1 and P2, and three equally probable histories of incomplete lineage sorting (ILS). (D) In the presence of gene flow, there are four additional coalescent histories, where the P2 lineage traces its ancestry through P3’s side of the tree, one with a history of LS between P2 and P3, and three equally probable histories of ILS.
Introgressed segments contain both new archaic-derived mutations and reintroduced ancestral alleles, generating characteristic patterns of allele sharing (Green et al. 2010; Reich et al. 2010; Durand et al. 2011; Peede et al. 2022; Dagilis and Matute 2023; Lopez Fang et al. 2024). Non-African populations share more alleles with Neanderthals and Denisovans than African populations do (Green et al. 2010; Durand et al. 2011; Yang et al. 2012; Lohse and Frantz 2014), which suggests that archaic gene flow into non-African populations was generally more extensive. Nonetheless, recent studies have identified instances of gene flow between Neanderthals and African populations (Kuhlwilm et al. 2016; Wall et al. 2019; Chen et al. 2020; Hubisz et al. 2020; Peyrégne et al. 2022; Harris et al. 2023; Li et al. 2024). To date, all known Neanderthal and Denisovan remains have been excavated outside Africa, providing complementary evidence that gene flow from these archaic groups into African populations was likely limited in extent (Green et al. 2010; Meyer et al. 2012; Prüfer et al. 2014, 2017; Hajdinjak et al. 2018; Slon et al. 2018; Mafessoni et al. 2020; Skov et al. 2022; Slimak et al. 2024; Tsutaya et al. 2025).
These allele sharing asymmetries, together with segment length and linkage information, form the conceptual foundation of archaic introgression inference. As detailed below, the distinctions among methods lie in how the genomic signals of introgression are constrained and leveraged.
Site patterns and f-statistics
Coalescent theory has been invaluable for investigating the patterns of genetic variation that arise from introgression. The Instantaneous Unidirectional Admixture (IUA) model (Green et al. 2010; Durand et al. 2011), conceptually akin to earlier multispecies coalescent models with gene flow (Jin et al. 2006; Than et al. 2007; Kubatko 2009; Meng and Kubatko 2009), is a classic framework for modeling introgression (Fig. 1B). The IUA model tracks a lineage from three populations: an African control (P1), a non-African recipient (P2), and an archaic donor (P3), with a single introgression event from P3 into P2 at time TGF, after P1 and P2 split from their most recent common ancestral population P12. In practice, an outgroup population (O) is included that is sufficiently diverged so that the ingroup populations (i.e., P1, P2, P3) always share a most recent common ancestor before coalescing with it. This outgroup serves to polarize ancestral states, as the true ancestral states are rarely known. Each locus in the genome is represented by a genealogical tree categorized into eight distinct coalescent histories (Fig. 1C–D; Hudson 1983; Tajima 1983; Pamilo and Nei 1988).
Without introgression, there are four possible coalescent histories: one lineage sorting (LS), where P1 and P2 lineages coalesce in their most recent common ancestral population P12, and three incomplete lineage sorting (ILS), where P1 and P2 fail to coalesce in P12 (Fig. 1C). Introgression introduces four additional coalescent histories, where P2 traces its ancestry through the P3 side of the population tree, including one additional LS between P2 and P3 and three coalescent histories of ILS (Fig. 1D). In the absence of gene flow, all coalescent histories of ILS are equally probable, where P1 and P2 are equidistant from P3. However, introgression disrupts this expected symmetry, as it introduces more coalescent histories where P2 and P3 coalesce more recently than P1 and P3 (Meng and Kubatko 2009; Durand et al. 2011; Liu et al. 2014a; Hibbins and Hahn 2019).
Although genealogical trees are unobservable, mutations on different branches generate identifiable site patterns used to study introgression (Green et al. 2010; Durand et al. 2011). By polarizing alleles with an outgroup (O), a site pattern is defined by the configuration of ancestral (A) and derived (B) alleles at a given biallelic site for the ordered set {P1, P2, P3, O}. Six site patterns are informative: three indicating derived allele sharing (ABBA, BABA, BBAA) from mutations on internal branches, and three indicating ancestral allele sharing (BAAA, ABAA, AABA) from mutations on terminal branches (Fig. 1B–D). Site pattern-based methods are computationally efficient and require only one genome per population, or allele frequencies, to determine the likelihood of observing the derived allele.
The most widely used site pattern-based method, Patterson’s D, detects introgression by comparing genome-wide counts of ABBA and BABA, which are expected to be equal in the absence of gene flow (Green et al. 2010; Durand et al. 2011). Instead of using site patterns as proxies for genealogical tree frequencies, the related statistic f4(P1, P2; P3, O) leverages correlations in allele frequencies to test for deviations from tree-like evolution by quantifying the shared genetic drift between clades (P1, P2) and (P3, O) (Reich et al. 2009; Patterson et al. 2012; Peter 2016). In the absence of gene flow, drift is independent between these two clades, and f4(P1, P2; P3, O) is expected to be equal to zero. A significant nonzero value indicates that the drift separating P1 from P3 is partially shared with P2 and O. By including another archaic individual presumed to have no genetic contribution to P2, the proportion of introgressed ancestry from P3 can be quantified using the quotient of two f4 values on permuted tips, that is, f4-ratio (Reich et al. 2009; Patterson et al. 2012; Peter 2016).
Introgression can also reintroduce ancestral variation previously lost in the recipient population (Peede et al. 2022; Dagilis and Matute 2023; Lopez Fang et al. 2024). To leverage this signal, Danc compares the genome-wide counts of BAAA and ABAA to detect introgression through ancestral allele sharing (Peede et al. 2022; Lopez Fang et al. 2024). In the absence of gene flow, the expected terminal branch lengths to P1 and P2 are equal, but with introgression, the terminal branch to P1 is longer than P2, generating excess BAAA site patterns. D+ combines the signal captured from Danc and Patterson’s D by including derived and ancestral allele sharing site patterns in a composite summary statistic, enabling both genome-wide and localized introgression inferences (Peede et al. 2022; Lopez Fang et al. 2024). Likewise, other approaches have been developed to detect locally introgressed regions using site patterns: df (Pfeifer and Kapan 2019) considers all derived-sharing patterns, whereas fd (Martin et al. 2014) accounts for the directionality of gene flow by dynamically switching the donor population label between P2 and P3 based on which harbors the derived allele at a higher frequency—also see fdM (Malinsky et al. 2015) for a symmetrically bounded variant of fd.
In addition to detecting the presence of introgression, site pattern-based methods can estimate the proportion of the recipient’s genome derived from the donor population. For example, fG normalizes the ABBA–BABA excess by the same difference when splitting P3 into two demes P3a and P3b (Durand et al. 2011). Similarly, see fhom (Martin et al. 2014), fanc (Peede et al. 2022), f+ (Peede et al. 2022), and Dp (Hamlin et al. 2020) for additional methods to quantify introgression. For site pattern-based methods and f-statistics, statistical significance is determined through block-jackknifing or bootstrapping with sufficiently large blocks to account for linkage disequilibrium (LD; Green et al. 2010; Durand et al. 2011; Patterson et al. 2012). Importantly, significant values are suggestive of introgression, as alternative demographic scenarios (e.g., ancestral population structure) can mimic these signals (Green et al. 2010; Durand et al. 2011; Peter 2016).
ARG-based methods
The ancestral recombination graph (ARG) represents the complete history of coalescence, recombination, and mutation events for a set of sampled sequences (Griffiths 1991; Griffiths and Marjoram 1996, 1997). As a summary of marginal genealogies across the genome, the ARG captures the evolutionary history of samples, including introgression events (Hubisz and Siepel 2020; Fan et al. 2025). ARG reconstruction is a rapidly evolving area of research, and we direct the reader to several recent reviews that provide overviews of inference approaches, highlighting the trade-offs between accuracy and scalability, along with differences in data requirements and encoding strategies (Brandt et al. 2024; Lewanski et al. 2024; Wong et al. 2024; Nielsen et al. 2025).
Consider a hypothetical ARG (represented as a sequence of local trees) involving a single African, Eurasian, and Neanderthal individual (Fig. 2A). Without introgression, coalescence events more recent than the modern human–Neanderthal split time occur only among modern human lineages. In contrast, gene flow generates local trees where Eurasian and Neanderthal lineages coalesce more recently than their split time, providing a key signal for detecting introgression from the ARG. Quantifying introgression thus involves estimating the proportion of the genome covered by local trees that are consistent with introgression. In practice, this signal is complicated by uncertainty in inferred split times and coalescence events, further compounded by mutation rate heterogeneity (Hubisz and Siepel 2020) and ARG inference approach (e.g., posterior sampling vs. point estimates).
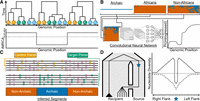
Recent approaches for studying introgression. (A) A hypothetical ancestral recombination graph (ARG) represented as a sequence of three local trees for two African chromosomes in orange (A1/A2), two Eurasian chromosomes in green (E1/E2), and two Neanderthal chromosomes in sky blue (N1/N2). One way to identify introgressed segments from the ARG is to look for local trees where lineages from the recipient and donor populations share a more recent common ancestor than expected, given their known split times. The plot shows the time to the most recent common ancestor (tMRCA) for Eurasian (EUR) and Neanderthal (NEA) chromosomes across the genome (gray line), with the black dotted line indicating their split time. Local trees with a tMRCA younger than this split time (e.g., the middle tree) can be interpreted as evidence of introgression. (B) Reference-based approaches leveraging convolutional neural networks (CNNs) applied to haplotype matrices. The top row depicts an archaic haplotype (blue) alongside haplotype matrices for African and non-African populations, with haplotypes sorted according to their similarity to the archaic haplotype. The combined haplotype matrix (bottom row) is processed by a CNN trained on simulated data, which outputs the probability of introgression in the non-African population for each position (gray line). (C) Reference-free methods do not rely on an archaic reference genome to infer introgressed segments. Instead, they use a control panel with negligible introgressed ancestry (e.g., Africans) and a target panel hypothesized to have received introgression (e.g., non-Africans). The genome is partitioned into windows (gray dashed lines). Within each window, these methods compare the local density of shared mutations (pink) to private mutations; orange and green for the control and target panels, respectively. Segments classified as “Archaic” exhibit a high density of private mutations in the target panel and a low density of shared mutations between the control and target panels. (D) A population tree (left) depicts gene flow from a source to a recipient population, with the black dashed line denoting their split time. A beneficial mutation (blue star) originates in the source population and is introgressed into the recipient population. In the recipient population, lineages carrying the beneficial mutation coalesce rapidly with the source lineage, forming a star-like topology, whereas the black triangle represents a clade of lineages that did not inherit the beneficial allele. The right panel depicts patterns of nucleotide diversity (y-axis) in the recipient population centered on the beneficial mutation (x-axis), with the black dotted line showing the genome-wide average. Under adaptive introgression (solid gray line), a narrow region of reduced diversity flanked by elevated diversity forms a volcano pattern, contrasting with a classical selective sweep (dashed gray line), where the beneficial mutation arises within the recipient population, creates a broader valley of reduced diversity.
ARGweaver (Table 1; Rasmussen et al. 2014) is a Bayesian method that samples from the posterior distribution of possible ARGs, providing uncertainty estimates for coalescence event times and ARG topology. From this posterior sample, introgressed segments correspond to regions where modern human haplotypes coalesce with archaic lineages consistently more recently than expected (Hubisz and Siepel 2020). ARGweaver-D (Table 1; Hubisz et al. 2020), builds upon this framework by incorporating a user-specified demographic model to track migrating lineages between populations. Identifying introgressed regions involves scanning local trees whose branches follow the migration band above a posterior probability threshold, reflecting the frequency of introgression in the sampled ARGs. Applying ARGweaver-D to modern and archaic genomes, Hubisz et al. (2020) estimated that 3%–7% of the Neanderthal genome originated from an introgression event with early modern humans 200–300 kya. They also inferred that 1% of the Denisovan genome is derived from an unsequenced, highly diverged hominin, with ∼15% of these “super-archaic” regions inherited by modern humans through Denisovan introgression. Unlike other ARG inference methods that require experimentally phased archaic genomes, ARGweaver and ARGweaver-D uniquely support analyses with unphased genotypes by integrating over possible phasings during their sampling procedure (Rasmussen et al. 2014; Hubisz and Siepel 2020; Hubisz et al. 2020). Additionally, these methods account for the archaic individual’s sampling age, enabling the correction of biases in leaf branch lengths and allele age estimates (Hubisz and Siepel 2020; Hubisz et al. 2020). However, their computational demands limit their scalability to ∼50 diploid genomes (Rasmussen et al. 2014; Hubisz and Siepel 2020; Hubisz et al. 2020).
Overview of ancestral recombination graph inference methods for studying introgression
Alternative methods scale to thousands of genomes by inferring a single “reasonable” ARG, often represented as a sequence of local trees without explicit recombination edges, but at the cost of principled uncertainty estimation and require phased samples. For example, SARGE (Table 1; Schaefer et al. 2021) utilizes a parsimony-based approach that prioritizes scalability over the fine-scale resolution of marginal genealogies, while remaining suitable for studying introgression. Schaefer et al. (2021) used SARGE to identify local trees where non-African and archaic haplotypes formed a clade, excluding trees that span short intervals—likely due to ILS. For the resulting trees, they computed the time to the most recent common ancestor (tMRCA) between non-African and archaic haplotypes, and then scored local trees based on the probability of ILS given the tMRCA and tree span, producing a final set of introgressed regions (Schaefer et al. 2021).
Unlike the previous methods, tsinfer/tsdate (Table 1; Kelleher et al. 2019; Wohns et al. 2022) do not simultaneously infer the ARG for modern and archaic samples. Instead, dated genealogies are first reconstructed from modern human genomes, and subsequently, phased archaic genomes with age estimates are incorporated. Ancestral relationships are then inferred between modern human ancestral nodes and “proxy ancestors” associated with each archaic sample, a construction that prevents any of the samples from being directly descended from another (Kelleher et al. 2019; Wohns et al. 2022). The use of proxy ancestors eliminates the need to compare the local tMRCA against an assumed modern human-archaic population split time, instead enabling the identification of introgressed material by determining whether a modern human lineage descends from an archaic proxy ancestor.
Reference-based methods
One strategy for identifying introgressed segments is to scan a modern human genome and label regions with a strong affinity to a sequenced archaic individual as introgressed. Because these approaches rely on an archaic “reference” genome as the putative source, they are referred to as reference-based methods.
IBDmix (Table 2; Chen et al. 2020) is an identity-by-descent (IBD) approach, requiring only a target population and archaic source genome. For each individual, it computes a running similarity score summarizing the likelihood of IBD between the query and archaic genotypes. When the score becomes negative, IBDmix selects alleles that maximize similarity within that region, labeling them introgressed, and then resumes scanning from that point. Li et al. (2024) used IBDmix to identify Neanderthal segments in African and non-African genomes, and by analyzing these segments, they were able to disentangle the directionality of gene flow, identifying regions in the Neanderthal genome derived from introgression with modern humans (Li et al. 2024). diCal-ADMIX (Table 2; Steinrücken et al. 2018) identifies introgressed segments in target haplotypes using a hidden Markov model (HMM), requiring phased genomes except for the archaic genome, which can be pseudo-haploid. The HMM is based on the sequentially Markovian coalescent conditional sampling distribution (Paul and Song 2010; Paul et al. 2011; Steinrücken et al. 2013) parameterized by a user-defined demographic model of the control (African), target (non-African), and source (archaic) populations. Haplotypes from control and source form “trunk” populations, with target haplotypes iteratively absorbed by these trunks. The hidden state space corresponds to the potential trunk haplotypes and the timing of absorption, whereas the transition and emission probabilities are based on a previously defined model for structured populations with migration and recombination (Steinrücken et al. 2013). After decoding, the probability that a target haplotype is introgressed is computed, resulting in a set of introgressed tracts per target haplotype (Steinrücken et al. 2018).
Overview of methods for characterizing local patterns of introgression
ArchaicSeeker2.0 (Table 2; Yuan et al. 2021) also uses an HMM, but allows inference of multiple introgression events from multiple archaic sources. Given input genomes for Neanderthal, Denisovan, and African populations, ArchaicSeeker2.0 first identifies candidate introgressed sequences in query genomes. These candidate sequences are then matched to a set of tree topologies corresponding to introgression, ILS, or false positives. The parameters for introgression events are then inferred based on sequences that match a tree topology consistent with introgression. Applying ArchaicSeeker2.0 to modern and archaic human genomes, Yuan et al. (2021) inferred two waves of Neanderthal- and Denisovan-like introgression events across Eurasia and Oceania and revealed how additional gene flow events among modern human populations have shaped the global distribution of introgressed ancestry.
The growing availability of sequenced ancient modern human genomes presents an opportunity to explore the temporal and spatial dynamics of archaic introgression, although technical limitations (e.g., sequencing artifacts, contamination, and low sequencing coverage) complicate such inferences. To overcome this, admixfrog (Table 2; Peter 2020) combines a genotype likelihood model, explicitly accounting for contamination and sequencing errors, with an HMM to infer introgressed ancestry in a target individual as a mixture of multiple high-quality source panels. By integrating these two models, admixfrog can simultaneously infer multiple ancestry states (from different archaic sources), genotype likelihoods, sequencing error rates, and contamination rates, even for genomes with coverage as low as 0.03× (Peter 2020). Notably, admixfrog has been used to infer instances of gene flow between Neanderthals and Denisovans (Peter 2020).
Departing from HMMs, Sankararaman et al. (2014) developed a Conditional Random Field (CRF) for identifying Neanderthal segments in non-African populations, later extending it to infer both Neanderthal and Denisovan segments (Table 2; Sankararaman et al. 2016). Unlike HMMs, CRFs model the conditional probability of hidden states given a set of features computed from the observed data, allowing multiple emission functions that relate observed features to hidden states (i.e., introgressed or not). As discriminative models, CRFs require training data, for example, from simulations, to learn their parameters (Sankararaman et al. 2014, 2016). Sankararaman et al. (2016) used a CRF to infer archaic segments per haplotype in a target panel by comparing them to an archaic source individual and a control panel lacking introgressed ancestry. Their implementation uses two emission functions: one compares patterns of derived allele sharing between the target haplotype, archaic source, and control panel, and the other compares haplotype distances between the target haplotype and the archaic source versus the minimum distance to the control panel (Sankararaman et al. 2016). To identify Neanderthal segments, Africans and Denisovans serve as the control panel, whereas Africans and Neanderthals are used to detect Denisovan segments (Sankararaman et al. 2016). Sankararaman et al.’s (2016) CRF rarely misclassified modern human ancestry as archaic, but misclassification between Neanderthal and Denisovan ancestry was more frequent and comparable to the correct classification probabilities, underscoring the difficulty of attributing archaic sources to introgressed segments.
Recently, deep learning methods have gained popularity in evolutionary biology owing to advances in simulation software for generating synthetic training data (Baumdicker et al. 2022; Haller and Messer 2023), user-friendly ecosystems for implementing machine learning architectures (Chen et al. 2019; Zeng et al. 2021; Sanchez et al. 2023; Wang et al. 2023), and specialized computing hardware. Convolutional Neural Networks (CNNs), originally developed for computer vision tasks, have been widely adopted for population genetic inferences because of the similarities between image data and SNP matrices (Fig. 2B; Flagel et al. 2019). One application of CNNs in introgression inference is IntroUNET (Table 2; Ray et al. 2024), which takes matrices with rows corresponding to sampled haplotypes and columns corresponding to the derived allele count as input. Because 2D convolutions are dependent on row ordering, haplotypes are sorted to minimize the genetic distance between adjacent rows (Ray et al. 2024). Using SNP matrices constructed from putative source and recipient populations and large-scale simulations based on their shared demographic history for training, IntroUNET estimates the likelihood of introgression per SNP per haplotype or individual if genotypes are unphased. When the source population is unknown or unsequenced, IntroUNET can be trained using a control population assumed to lack introgressed ancestry, which can be used to identify segments derived from super-archaic introgression (Ray et al. 2024).
Reference-free methods
The methods discussed so far primarily rely on available archaic “reference” genomes to infer introgressed segments. However, because of the limited number of high-coverage archaic genomes, a proportion of the genetic variation present in the donor populations is likely to be unrepresented, especially true for unsampled archaic source populations (Durvasula and Sankararaman 2020). Fortunately, archaic introgression leaves detectable genomic signatures that enable inference without requiring an archaic genome; these approaches are known as reference-free methods (Fig. 2C). For instance, the S* statistic (Plagnol and Wall 2006) provides a measure of tightly linked SNPs in the target population that are absent in a closely related control population, which is assumed to lack introgressed ancestry. Typically, African populations serve as the control, although alternatives (e.g., European populations for inferring Denisovan segments) may be more appropriate depending on the context (Zhang et al. 2021).
SPrime (Table 2; Browning et al. 2018) is a popular extension of S* that accounts for how low levels of introgressed ancestry in the control population and heterogeneity in mutation and recombination rates affect S* scores. SPrime iteratively finds alleles in a query genotype that maximize an S*-like score, classifies these putative archaic alleles as forming an introgressed segment, and removes them for the next iteration until the segment’s score falls below a user-specified threshold. Notably, this method was used to provide the first line of evidence for two distinct pulses of Denisovan introgression into modern humans (Browning et al. 2018).
Also relying on S*, sstar (Table 2; Huang et al. 2022), partitions the genome into windows, computes S* scores per window, and then filters these scores for significance. If no genomes for the putative source population exist, sstar requires a demographic model of the control, target, and source populations to simulate and determine the S* threshold for classifying introgressed segments. If genomic data are available, sstar uses the sequence similarity between the query and source sequences as the final discriminator. Huang et al.’s (2022) simulation study indicates that sstar is robust to a number of complex introgression scenarios (e.g., introgression from multiple sources and unsampled sources) and maintains power to identify introgressed segments given limited sample sizes.
ArchIE (Table 2; Durvasula and Sankararaman 2019) implements a logistic regression model trained on simulated data, to classify genomic windows in a focal haplotype as archaic or not. To do so, ArchIE uses a suite of summary statistics that capture different aspects of introgression signals: the individual site frequency spectrum (SFS), the first four moments of the pairwise difference distribution for the target population, the number of private SNPs in a focal haplotype, the minimum pairwise differences between a focal haplotype and control population, and S* scores (Plagnol and Wall 2006; Chen et al. 2007; Hammer et al. 2011). By incorporating population- and individual-level summary statistics, ArchIE can more accurately identify introgressed windows than S* or SPrime alone (Durvasula and Sankararaman 2019). Although limited to haplotype data and requiring prior knowledge of the joint demographic history for the control, target, and source populations, ArchIE has been used to identify introgressed segments in West African genomes, which are believed to have been inherited from an unsampled archaic population (Durvasula and Sankararaman 2020). hmmix (Table 2; Skov et al. 2018; Macià et al. 2025) takes an approach conceptually similar to S* to classify introgressed segments based on the local density of variants absent in the control population. Using an HMM where the observations correspond to the number of private derived alleles in the query haplotype (or unphased diploid genotype) per window, hmmix first finds the optimal set of model parameters before inferring a decoded sequence of ancestry predictions (i.e., archaic or not) across the query genome. The only prior knowledge required are initial estimates of the model’s parameters, as the optimal set is learned, making inference applicable to Neanderthal, Denisovan, or even super-archaic introgression (Teixeira et al. 2021). DAIseg (Table 2; Planche et al. 2025) further enhances inferences of introgressed segments and their most likely donor by extending the hmmix framework to an arbitrary number of control populations and archaic hidden states. Notably, this more flexible reference-free approach is particularly useful for simultaneously identifying Neanderthal and Denisovan introgressed tracts without the need for additional post hoc filtering steps (Planche et al. 2025).
Methods to detect adaptive introgression
Although most archaic ancestry found in modern humans is assumed to be neutral, adaptively introgressed material provides fitness advantages to the recipient population (Racimo et al. 2015; Edelman and Mallet 2021). Such segments will rise in frequency, reducing the opportunity for recombination to break them apart, and thus tend to be longer than predicted by neutrality (Shchur et al. 2020). Genealogically, adaptively introgressed regions exhibit a high density of recent coalescent events among lineages carrying the beneficial introgressed allele, producing star-like topologies (Fig. 2D; Coop and Griffiths 2004; Kim and Nielsen 2004; Hejase et al. 2020). Accordingly, these introgressed alleles often appear in strong LD and at high frequencies in the recipient population but remain rare or absent in populations that did not experience the same selective advantage. However, similar patterns can arise from alternative scenarios, such as post-introgression bottlenecks (Kerdoncuff et al. 2025) or heterosis masking recessive deleterious mutations, which subsequently inflate the frequency of introgressed ancestry when donor populations carry higher mutational loads (Ingvarsson and Whitlock 2000; Kim et al. 2018; Zhang et al. 2020).
Researchers have historically identified adaptively introgressed regions using outlier-based approaches (Racimo et al. 2015; Edelman and Mallet 2021), conducting genome-wide scans for positive selection and introgression, and then intersecting outlier regions to identify candidates. However, the genomic signature of adaptive introgression differs from that of classical selective sweeps, leaving a narrower valley of reduced genetic diversity flanked by regions harboring alleles at intermediate frequencies in the recipient population (Fig. 2D; Santiago and Caballero 2005; Setter et al. 2020). Furthermore, methods designed to detect positive selection are typically optimized for specific scenarios, making their selection nontrivial and influencing downstream power (for a recent review of methods, see: Hejase et al. 2020). Therefore, methods that explicitly leverage the unique genomic signatures of adaptive introgression are desirable to avoid potential false inferences from intersecting multiple genomic scans.
To address these challenges, Racimo et al. (2016) introduced the U- and Q95-statistics, window-based summaries designed to detect adaptive introgression. The key idea behind these statistics is that regions shaped by archaic adaptive introgression are expected to harbor many sites where the archaic allele has risen to high frequency in the target population, while remaining rare or absent in a control population presumed to lack archaic genetic contributions. UA,B,C(w, x, y) counts sites where the archaic allele (in C) is rare (<w) in the control population A, common (>x) in the target population B, and at frequency y in the archaic individual C. The main drawback of U-statistics is that researchers must define a threshold for what constitutes a “high” archaic allele frequency in the target population. As an alternative, Q95A,B,C(w, y) computes the 95th percentile of the archaic allele frequency distribution in the target population B, conditioned on the alleles being rare (<w) in the control population A and present at frequency y in the archaic individual C. To distinguish Neanderthal from Denisovan adaptive introgression, Racimo et al. (2016) also developed the UA,B,C,D(w, x, y, z) and Q95A,B,C,D(w, y, z) statistics, requiring specific allele frequencies in both archaic individuals C (=y) and D (=z). Although these summary statistics still rely on outlier-based genome-wide scans, multiple studies have demonstrated that they are highly effective at identifying regions of adaptive introgression while minimizing confounding effects from demographic processes and heterosis (Racimo et al. 2016; Zhang et al. 2020; Gower et al. 2021; Zhang et al. 2023; Romieu et al. 2025).
As an alternative to summary statistics, VolcanoFinder (Table 3; Setter et al. 2020) uses a coalescent-based model of adaptive introgression, requiring only genetic data from the recipient population. Leveraging the distinctive volcano-shaped pattern of genetic diversity left by adaptive introgression (Fig. 2D), VolcanoFinder implements a composite likelihood ratio test to assess whether the local SFS in the recipient population is consistent with adaptive introgression. Notably, this method is especially effective when the donor and recipient populations are highly divergent, making it particularly useful for detecting introgression from unsampled archaic populations lacking genomic data (Setter et al. 2020).
Overview of methods for studying adaptive introgression
Building on the growing application of deep learning models for population genetic inferences, genomatnn (Table 3; Gower et al. 2021) uses a CNN trained on simulated data to detect adaptive introgression by classifying local genotype matrices as adaptively introgressed or not. genomatnn takes a 2D SNP matrix as input (haplotypes x sites), representing the presence or absence of the derived allele at a given site per haplotype (or per unphased diploid genotype). Haplotypes in the matrix are sorted based on similarity to a genome from the donor population and consequently require an archaic genome as input. Although its power to detect adaptive introgression is sensitive to the demographic parameters used for training, namely the timing and strength of selection, genomatnn has successfully recovered previously proposed candidates of both Neanderthal and Denisovan adaptive introgression, in addition to identifying novel candidates (Gower et al. 2021).
Another machine learning method to detect adaptive introgression, MaLAdapt (Table 3; Zhang et al. 2023) uses an Extra-Trees classifier (Geurts et al. 2006) trained on simulated data to classify genomic windows based on summary statistics calculated across donor, recipient, and control populations. The advantage of this ensemble learning technique is that, although the simulated data do not precisely match the empirical data, the relationships between them—as encoded by summary statistics—are similar, and this approach has proved effective for studying introgression in nonhuman systems (Schrider et al. 2018). However, MaLAdapt assumes that the demographic model used for the simulations is representative of the demographic model underlying the empirical data. Despite MaLAdapt recovering previously proposed candidates of adaptive introgression, Zhang et al. (2023) did not find evidence of adaptive introgression in HLA genes (Abi-Rached et al. 2011; Ding et al. 2014a), aligning with recent evidence that these were likely false positives resulting from heterosis (Zhang et al. 2020).
Practical considerations
The proliferation of methods for studying archaic introgression makes it challenging to decide which method is best suited for a given analysis. As no systematic benchmarking study has yet compared the power and precision of these methods, it is premature to broadly recommend one method over another. Instead, based on the methods discussed in this review, we provide a set of recommendations for studying archaic introgression to highlight potential use cases, depending on the genomic scale of interest (i.e., characterizing global patterns of introgression, identifying introgressed regions along the genome, or pinpointing adaptively introgressed regions) and data available (Figs. 3–5). Additionally, to help researchers sift through the wide array of resources available to them, we provide easy-to-access references for all methods reviewed, including the key data requirements, targets and resolution of inference, links to documentation, and links to publicly available resources, that is, published protocols, tutorials, and data sets (Tables 1–3). In the following subsections, we discuss practical considerations that researchers must navigate when studying archaic introgression, highlight outstanding challenges, and provide recommendations for future research directions.
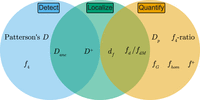
Recommendations for detecting and quantifying patterns of introgression using site pattern-based methods and f-statistics. Venn diagram summarizing site pattern-based methods and f-statistics used to detect and quantify introgression. Methods to detect introgression on a genome-wide scale are shown in the sky blue circle, those for quantifying introgression on a genome-wide scale are shown in the orange circle, and methods designed to localize signals of introgression in nonoverlapping genomic windows are shown in the green circle.
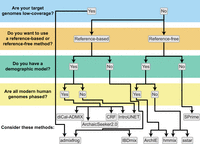
Recommendations for identifying introgressed segments along the genome. Decision tree to determine which inference methods are appropriate for characterizing local patterns of introgression based on data availability.
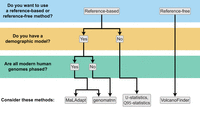
Recommendations for detecting adaptive introgression. Decision tree to determine which inference methods are appropriate for detecting adaptive introgression based on data availability.
Genome availability and quality
All methods for studying archaic introgression are inherently constrained by the number and quality of publicly available archaic genomes. To date, three high-coverage Neanderthal genomes (Prüfer et al. 2014, 2017; Mafessoni et al. 2020) and one high-coverage Denisovan genome (Meyer et al. 2012) are publicly available; however, they likely do not fully capture the amount of genetic variation present in the Neanderthal and Denisovan populations that interbred with the ancestors of present-day humans. In the case of studying Denisovan introgression, this limitation is exacerbated by the finding that the only high-coverage sequenced Denisovan individual is distantly related to the introgressing Denisovan populations that interbred with modern humans (Skoglund and Jakobsson 2011; Jacobs et al. 2019; Ongaro and Huerta-Sanchez 2024; Peyrégne et al. 2024).
Although the progression of publicly available high-coverage archaic genomes has been slow, the recent growth in the number of published ancient modern human genomes (Mallick et al. 2024) provides an opportunity to study how archaic ancestry has changed across time and space. The majority of these data have been sequenced using capture-enrichment methods or are low-coverage, restricting researchers to primarily analyzing pseudo-haploid genotypes. Although this poses little concern for site pattern-based methods and f-statistics, this data type tends to be limited to methods aimed at characterizing global patterns of introgression. One increasingly popular alternative involves imputing and/or phasing ancient genomes using present-day genomes as a reference panel, which has been shown to be accurate on a genome-wide level (Hui et al. 2020; Ausmees et al. 2022; Ausmees and Nettelblad 2023; Sousa da Mota et al. 2023; Çubukcu and Kılınç 2024; Escobar-Rodríguez and Veeramah 2024; Garrido Marques et al. 2024; Medina-Tretmanis et al. 2024; Kumar et al. 2025) and particularly accurate in introgressed regions of the genome (Capodiferro et al. 2025). However, the accuracy of imputing ancient genomes is influenced by multiple factors, including the age of the sample (Sousa da Mota et al. 2023; Escobar-Rodríguez and Veeramah 2024), aDNA sequencing approach (Hui et al. 2020; Sousa da Mota et al. 2023; Çubukcu and Kılınç 2024; Garrido Marques et al. 2024), overall sequencing coverage (Hui et al. 2020; Ausmees et al. 2022; Ausmees and Nettelblad 2023; Sousa da Mota et al. 2023; Çubukcu and Kılınç 2024; Escobar-Rodríguez and Veeramah 2024), the genetic ancestry composition and size of the reference panel (Hui et al. 2020; Ausmees et al. 2022; Sousa da Mota et al. 2023; Çubukcu and Kılınç 2024; Escobar-Rodríguez and Veeramah 2024; Kumar et al. 2025), the minor allele frequency spectrum of the reference panel (Hui et al. 2020; Ausmees et al. 2022; Ausmees and Nettelblad 2023; Sousa da Mota et al. 2023; Çubukcu and Kılınç 2024; Escobar-Rodríguez and Veeramah 2024), the choice of imputation software (Ausmees and Nettelblad 2023; Escobar-Rodríguez and Veeramah 2024; Garrido Marques et al. 2024; Kumar et al. 2025), and postimputation quality control steps (Hui et al. 2020; Sousa da Mota et al. 2023; Çubukcu and Kılınç 2024; Escobar-Rodríguez and Veeramah 2024). Although imputing ancient genomes has proven effective for studying archaic introgression, inferred introgressed segments are often shorter than their true lengths (Capodiferro et al. 2025). Developing strategies to correct this bias should be a focus of future work, as doing so will improve the accuracy for inferring the timing of introgression and, in turn, our understanding of the distribution of archaic ancestry across time and space.
Disambiguating the most likely donor
A central challenge in archaic introgression research is identifying the most likely donor of the inferred introgressed ancestry. Most non-African populations harbor Neanderthal ancestry and some populations from Asia and Oceania also harbor Denisovan ancestry in varying proportions, necessitating the development of strategies to distinguish between these archaic sources. On a genome-wide scale, this differentiation is relatively straightforward using site pattern-based methods or f-statistics. For example, Qin and Stoneking (2015) leveraged the fact that the Han Chinese and Oceanic populations harbor similar amounts of Neanderthal ancestry to infer Denisovan ancestry proportions in Oceanic populations using an f4-ratio approach. In the numerator, an excess of shared drift between an Oceanic population X and Neanderthal, f4 (Yoruba, Neanderthal; Han, X), is attributable to Denisovan introgression and normalized by the total shared drift between the Neanderthal and the Denisovan in the denominator, f4 (Yoruba, Neanderthal; Han, Denisovan), one can constrain the Denisovan ancestry proportion for X.
Disambiguating between potential donors for local introgressed regions is more challenging, although Sankararaman et al.’s (2016) CRF, ARGweaver-D (Hubisz et al. 2020), admixfrog (Peter 2020), ArchaicSeeker2.0 (Yuan et al. 2021), and DAIseg (Planche et al. 2025) are notable exceptions that explicitly account for this complexity. Reference-based methods inherently identify the donor based on the archaic genome used but face two key limitations: they depend on the availability and quality of archaic genomes and typically require additional postprocessing steps unless they jointly infer segments from multiple archaic sources. For example, to generate their final callset of introgressed Neanderthal segments, Chen et al. (2020) used IBDmix to infer introgressed Denisovan segments and subsequently masked any introgressed segment that fell within the intersection of these two archaic segment sets.
On the other hand, although reference-free approaches do not require an archaic genome for inference, their use is necessary for an additional post hoc step to annotate the most probable archaic source for each segment. Although this task is conceptually straightforward, the field lacks a standardized, principled population genetics approach to do so. Common strategies include counting the number of derived alleles shared between a candidate segment and archaic genomes or computing a so-called match rate, the proportion of alleles within the segment that match those in the archaic genome. Researchers must then define thresholds to classify segments as Neanderthal, Denisovan, or ambiguous. Although these thresholds can be defined rigorously (e.g., using simulations), the lack of standardization across studies has resulted in a patchwork of strategies for annotating putative introgressed segments.
Future studies should develop more principled approaches for annotating inferred introgressed tracts. A straightforward post hoc solution involves computing sequence divergence, the average number of pairwise differences normalized by the total number of callable positions, which has a direct coalescent interpretation related to the tMRCA between an introgressed segment and archaic genome (Peyrégne et al. 2022). This approach would eliminate arbitrary thresholds by comparing tMRCAs to inferred modern-archaic human split times and using the segment length to distinguish introgression from ILS. Alternatively, taking inspiration from Vernot et al. (2016), a hybrid two-step approach that integrates the strengths of both reference-free and reference-based methods presents a promising path forward. In this framework, a reference-free method first generates a proposal set of unlabeled introgressed segments, which is then passed to a reference-based probabilistic model to identify false positives and assign the most likely archaic donor.
Reconciling assumptions
Archaic introgression is often modeled as an instantaneous pulse of gene flow. Yet, growing evidence suggests multiple waves of Neanderthal (Sankararaman et al. 2014; Vernot and Akey 2014; Kim and Lohmueller 2015; Vernot and Akey 2015; Prüfer et al. 2017; Villanea and Schraiber 2019; Iasi et al. 2024; Li et al. 2024) and Denisovan (Reich et al. 2010, 2011; Meyer et al. 2012; Sankararaman et al. 2016; Vernot et al. 2016; Browning et al. 2018; Jacobs et al. 2019; Choin et al. 2021; Larena et al. 2021) introgression, gene flow between Neanderthals and Denisovans (Prüfer et al. 2014; Slon et al. 2018; Peter 2020; Villanea et al. 2025), and enigmatic gene flow from unsampled super-archaic populations (Hubisz et al. 2020; Mafessoni et al. 2020; Rogers et al. 2020). This evidence points to a more complex history of gene flow that must be addressed to avoid biased interpretations of introgression patterns. This unaccounted for complexity may be of particular concern for machine learning methods that rely on training data from large-scale simulations under prespecified demographic histories, as demographic mis-specification appears to be a major confounder (Durvasula and Sankararaman 2019; Gower et al. 2021; Ray et al. 2024; Cobb and Smith 2025; Hackl and Huang 2025). Encouragingly, there are machine learning techniques (e.g., domain adaptation; Mo and Siepel 2023; Cobb and Smith 2025) that could provide a potential solution for addressing the mismatch between the synthetic training data generated under a demographic model and the real data where the true demographic history is unknown. In contrast, natural selection and demographic processes (e.g., migration between control and recipient populations, bottlenecks, expansions, and population structure) can generate spurious signals that mimic introgression or dampen genuine signals (Durand et al. 2011; Peter 2016; Martin and Amos 2021; Smith and Hahn 2024; Kerdoncuff et al. 2025; Tournebize and Chikhi 2025). For example, Tournebize and Chikhi (2025) recently demonstrated that both allele frequency- and LD-based methods can produce spurious signals of archaic introgression under models of complex population structure that lack archaic gene flow events. These provocative findings emphasize the importance of carefully scrutinizing results for possible confounding factors and exploring alternative models to ensure that any evidence of archaic introgression is the most parsimonious explanation.
Similarly, African populations are commonly used as a control panel, presumed to lack archaic ancestry from Neanderthals and Denisovans, to identify which variants in non-African populations are likely of an archaic origin. However, mounting evidence of gene flow events between African populations and archaic humans challenges this assumption (Hammer et al. 2011; Kuhlwilm et al. 2016; Wall et al. 2019; Chen et al. 2020; Durvasula and Sankararaman 2020; Hubisz et al. 2020; Peyrégne et al. 2022; Harris et al. 2023; Ragsdale et al. 2023; Li et al. 2024). This calls for the further development of methods that do not rely on control panels to make inferences about archaic introgression. IBDmix exemplifies this approach, and has been used to detect Neanderthal ancestry across African populations (Chen et al. 2020; Harris et al. 2023; Li et al. 2024). IBDmix infers introgressed segments at the individual level for a single archaic source, with its power increasing alongside the sample size of the target panel. ARGweaver-D, in contrast, circumvents this reliance on a control panel by instead requiring a predefined demographic model, enabling inferences of introgressed segments at the haplotype level for an arbitrary number of potential archaic sources but its computational demands limit scalability (Hubisz et al. 2020). Future methods should draw inspiration from both IBDmix and ARGweaver-D to develop new inference frameworks for identifying introgressed segments at the haplotype level, which can accommodate multiple archaic sources, remain robust to sample size variation, and are computationally scalable.
Conclusion
Over the past 15 years, there has been a steady increase in the number of studies describing the extent and evolutionary impact of archaic introgression across populations worldwide. The continued effort to extend existing approaches and develop new methods will not only improve the resolution of our understanding of the complex demographic history of our species but also deepen our understanding and appreciation of the role archaic introgression has played in shaping both genetic and phenotypic variation throughout human evolution.
Although most studies on archaic introgression have focused on European or Asian populations, studying the landscape of archaic ancestry in recently admixed populations remains an ongoing challenge (Villanea and Witt 2022; Witt et al. 2023; Villanea et al. 2025). For instance, individuals from the Americas may have genetic ancestry that can be traced to populations commonly labeled as Indigenous American, European, or African due to the history of European colonization and the transatlantic slave trade (Medina-Muñoz et al. 2023). Consequently, there is a need for methods that can distinguish introgressed segments originating from different genetic backgrounds. One potential avenue to address these complexities is to develop methods that jointly infer both local ancestry and introgressed tracts. Because introgressed tracts would be sequestered within the particular genetic background from which they originated, local ancestry calls should provide greater resolution for identifying introgressed tracts, as recombination events coincide with the boundaries of introgressed tracts and induce transitions between genetic backgrounds.
Clear areas for progress also exist in loosening the data requirements for archaic introgression inference by developing methods that explicitly accommodate the challenges inherent to low-coverage aDNA sequencing. Because archaic variants on the same introgressed segment are expected to be in strong LD (Chakraborty and Weiss 1988; Wall 2000), and many of these variants are represented in modern human reference panels, imputation offers a promising avenue for studying archaic introgression in such contexts (Capodiferro et al. 2025). Nonetheless, imputation alone cannot fully capture the underlying complexities of aDNA sequencing, as indeed, both empirical and simulation-based benchmarking have shown that imputation accuracy is sensitive to the overall sequencing quality and coverage of the aDNA data (Hui et al. 2020; Ausmees et al. 2022; Ausmees and Nettelblad 2023; Sousa da Mota et al. 2023; Çubukcu and Kılınç 2024; Escobar-Rodríguez and Veeramah 2024; Garrido Marques et al. 2024). A future direction for overcoming these technical limitations is to integrate methods that explicitly account for the aforementioned sequencing complexities (e.g., admixfrog’s genotype likelihood model; Peter 2020) into an aDNA imputation framework, thereby modeling both genotype uncertainty and the underlying characteristics of aDNA that generate this uncertainty. Alternatively, other strategies could bypass imputation entirely. For example, Colate (Speidel et al. 2021) and Twigstats (Speidel et al. 2025) infer demographic and population history parameters from low-coverage ancient genomes by leveraging mutation age estimates obtained from Relate’s (Speidel et al. 2019) genome-wide genealogies reconstructed from modern human data. Future work could draw on these approaches to harness the potential of inferred ARGs for studying archaic introgression in low-coverage ancient individuals not included in the reconstructed genealogies.
These exciting avenues for future work will only encourage the development and further exploration of possible methods for investigating the nature of archaic introgression. We hope that by keeping both practitioners and developers abreast of this ever-expanding toolkit, the field will continue to deepen our understanding of our shared and tangled evolutionary history.
Data sets
All links to methods reported in Tables 1–3 were last accessed on January 7, 2026:
-
ARGweaver: https://github.com/mdrasmus/argweaver,
-
ARGweaver-D: https://github.com/CshlSiepelLab/argweaver-d-analysis,
-
tsinfer: https://tskit.dev/tsinfer/docs/stable,
-
tsdate: https://tskit.dev/tsdate/docs/stable,
-
diCal-ADMIX: https://diCal-ADMIX.sourceforge.net,
-
ArchaicSeeker2.0: https://github.com/Shuhua-Group/ArchaicSeeker2.0,
-
admixfrog: https://github.com/BenjaminPeter/admixfrog,
-
Sankararaman et al.’s (2016) CRF: https://drive.google.com/file/d/1Kz9jDP1tm8291tUZr0Zk2ahvglRnTJ0d,
-
IntroUNET: https://github.com/SchriderLab/introNets,
-
ArchIE: https://github.com/sriramlab/ArchIE,
-
hmmix: https://github.com/LauritsSkov/Introgression-detection,
-
DAIseg: https://github.com/LeoPlanche/DAIseg,
-
VolcanoFinder: https://degiorgiogroup.fau.edu/vf.html,
-
genomatnn: https://github.com/grahamgower/genomatnn,
-
MaLAdapt: https://github.com/xzhang-popgen/maladapt.
All links to publicly available data sets referenced in Tables 1–3 were last accessed on January 7, 2026:
-
Introgression maps from Hubisz et al. (2020): http://compgen.cshl.edu/ARGweaver/introgressionHub/files,
-
Inferred genealogies from Wohns et al. (2022): https://zenodo.org/records/5512994,
-
Neanderthal introgression maps from Li et al. (2024): https://zenodo.org/records/5512994,
-
Neanderthal introgression maps from Steinrücken et al. (2018): https://drive.google.com/drive/folders/0B_RxlKHkUXRDflZDd0xWTEVNWVF2OFppUmNka3ZWN19pbU5qVjBVV2lGVVBuQTJkWE5KTDg?resourcekey=0-LAWuR89grC372Hd572CGag&usp=drive_link,
-
Introgression maps from Yuan et al. (2021): https://github.com/Shuhua-Group/ArchaicSeeker2.0/tree/master/IntrogressedSeg,
-
Neanderthal introgression maps from Iasi et al. (2024): https://doi.org/10.5061/dryad.zw3r228gg,
-
Introgression maps from Sankararaman et al. (2016): https://drive.google.com/drive/folders/1DyhMw0E1mXQUDNeGQbQrcQbHe0uTyK2h,
-
Introgression maps from Browning et al. (2018): https://doi.org/10.17632/y7hyt83vxr.1,
-
Introgression maps from Durvasula and Sankararaman (2020): https://github.com/sriramlab/afr_archaic_maps,
-
Introgression maps from Skov et al. (2018): https://doi.org/10.1371/journal.pgen.1007641.s012,
-
Introgression maps from Planche et al. (2025): https://github.com/LeoPlanche/DAIseg/blob/main/src/IntrogressionMap,
-
Example workflow from Setter et al. (2020): https://doi.org/10.5061/dryad.7h44j0zr7,
-
Pretrained models from Gower et al. (2021): https://github.com/grahamgower/genomatnn/tree/main/pre-trained,
-
Adaptive introgression maps from Gower et al. (2021): https://github.com/grahamgower/genomatnn/tree/main/predictions,
-
Adaptive introgression maps from Zhang et al. (2023): https://github.com/xzhang-popgen/maladapt/tree/main/empirical_scores.
Competing interest statement
The authors declare no competing interests.
Acknowledgments
We thank the members of the Ramachandran and Huerta-Sánchez lab for their insightful comments and discussions. D.P. and E.H.-S. were supported by National Institutes of Health (NIH) grant no. R35GM128946 (to E.H.-S.). D.P. is also a trainee supported by the Brown University Predoctoral Training Program in Biological Data Science (NIH T32 GM128596) and the Blavatnik Family Foundation Graduate Fellowship. M.M.B. was supported by the Howard Hughes Medical Institute Gilliam Fellowship. J.M.T. was supported by the Young Investigator’s grant from the Human Frontier Science Program (to E.H.-S.). M.M. was supported by National Science Foundation grant no. PRFB-2305910 (to M.M.). E.H.-S. was also supported by the Alfred P. Sloan Award.
Footnotes
-
Article published online before print. Article and publication date are at https://www.genome.org/cgi/doi/10.1101/gr.278993.124.
-
Freely available online through the Genome Research Open Access option.
This article, published in Genome Research, is available under a Creative Commons License (Attribution-NonCommercial 4.0 International), as described at http://creativecommons.org/licenses/by-nc/4.0/.
References
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵








