
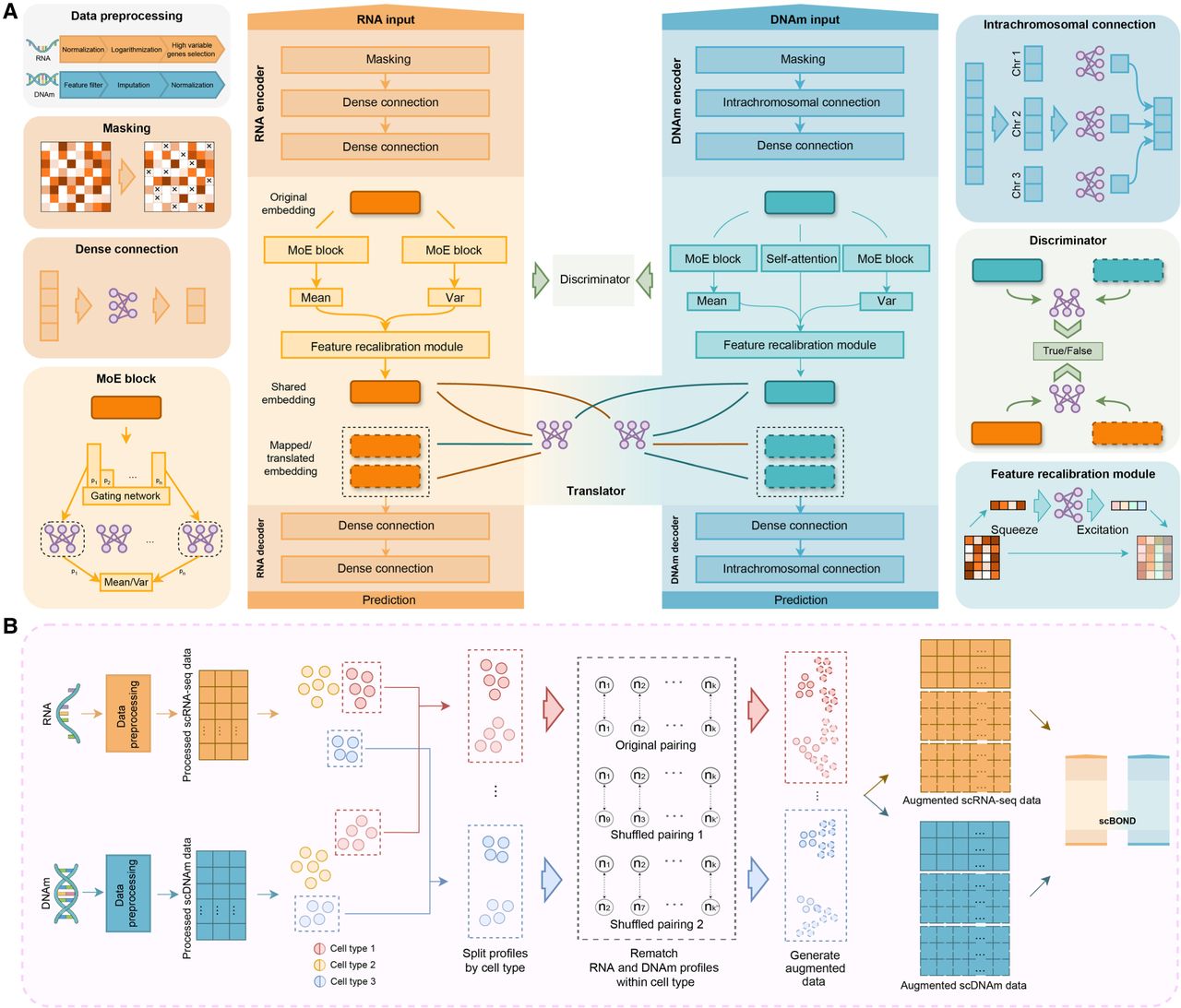
Overview of the scBOND framework and its variant scBOND-Aug. (A) The model features a dual-stream VAE design, with modality-specific encoders and decoders for translation. RNA and DNAm inputs undergo separate preprocessing steps, followed by masking and dense feature extraction. The RNA and DNAm translators perform the translation of each modality. A discriminator is employed to differentiate between real and translated embeddings. (B) The augmentation strategy of scBOND-Aug. scRNA-seq and scDNAm profiles are first preprocessed and then grouped by annotated cell type. Within each group, original cross-modal pairings are disrupted by randomly shuffling scDNAm profiles to generate biologically coherent synthetic pairs. These augmented data are then used to expand the training set for improved generalization under limited sample scenarios.








