
High-throughput characterization of genetic effects on DNA–protein binding and gene transcription
- Cynthia A. Kalita1,
- Christopher D. Brown2,
- Andrew Freiman1,
- Jenna Isherwood1,
- Xiaoquan Wen3,
- Roger Pique-Regi1,4 and
- Francesca Luca1,4
- 1Center for Molecular Medicine and Genetics, Wayne State University, Detroit, Michigan 48202, USA;
- 2Department of Genetics, University of Pennsylvania, Philadelphia, Pennsylvania 19104, USA;
- 3Department of Biostatistics, University of Michigan, Ann Arbor, Michigan 48109, USA;
- 4Department of Obstetrics and Gynecology, Wayne State University, Detroit, Michigan 48202, USA
Abstract
Many variants associated with complex traits are in noncoding regions and contribute to phenotypes by disrupting regulatory sequences. To characterize these variants, we developed a streamlined protocol for a high-throughput reporter assay, Biallelic Targeted STARR-seq (BiT-STARR-seq), that identifies allele-specific expression (ASE) while accounting for PCR duplicates through unique molecular identifiers. We tested 75,501 oligos (43,500 SNPs) and identified 2720 SNPs with significant ASE (FDR < 10%). To validate disruption of binding as one of the mechanisms underlying ASE, we developed a new high-throughput allele-specific binding assay for NFKB1. We identified 2684 SNPs with allele-specific binding (ASB) (FDR < 10%); 256 of these SNPs also had ASE (OR = 1.97, P-value = 0.0006). Of variants associated with complex traits, 1531 resulted in ASE, and 1662 showed ASB. For example, we characterized that the Crohn's disease risk variant for rs3810936 increases NFKB1 binding and results in altered gene expression.
Genome-wide association studies (GWAS) have identified thousands of common genetic variants associated with complex traits, including normal traits and common diseases. Many GWAS hits are in noncoding regions, so the underlying mechanism leading to specific phenotypes is likely through disruption of gene regulatory sequence. Quantitative trait loci (QTLs) for molecular and cellular phenotypes (Dermitzakis 2012), such as gene expression (eQTL) (Brem and Kruglyak 2005; Stranger 2007; Innocenti et al. 2011; Wen et al. 2015; GTEx Consortium 2017), transcription factor binding (Kasowski et al. 2010), and DNase I sensitivity (dsQTL) (Degner et al. 2012) have been crucial in providing strong evidence and a better understanding of how genetic variants in regulatory sequences can affect gene expression levels (Melzer et al. 2008; Gibbs et al. 2010; Albert and Kruglyak 2015; GTEx Consortium 2017). In recent work, we were able to validate 48% of computationally predicted allelic effects on transcription factor binding through traditional reporter assays (Moyerbrailean et al. 2016b). However, traditional reporter assays are limited by the time and the cost of testing variants one at a time.
Massively parallel reporter assays (MPRA) have been developed for the simultaneous measurement of the regulatory function of thousands of constructs at once. For MPRA, a pool of synthesized DNA oligos containing a barcode at the 3′ UTR of a reporter plasmid is transfected into cells, and transcripts are isolated for RNA-seq. Expression driven by the synthesized enhancer region is estimated from the number of RNA reads normalized by the number of corresponding DNA reads (Kwasnieski et al. 2012, 2014; Melnikov et al. 2012; Patwardhan et al. 2012; Sharon et al. 2012). An alternative to MPRA is self-transcribing active regulatory region sequencing (STARR-seq) (Arnold et al. 2013), whose methods involve fragmenting the genome and cloning the fragments 3′ of the reporter gene. The approach is based on the concept that enhancers can function independently of their relative positions, so putative enhancers are placed downstream from a minimal promoter. Active enhancers transcribe themselves, with their strength quantified as the amount of RNA transcripts within the cell. Because they do not use separate barcodes, STARR-seq approaches have streamlined protocols that allow for higher throughput. Recently, high-throughput assays have been used to assess the enhancer function of genomic regions (Arnold et al. 2013; Wang et al. 2017), the allelic effects on gene expression for naturally occurring variation in 104 regulatory regions (Vockley et al. 2015), fine-map variants associated with gene expression in lymphoblastoid cell lines (LCLs) and HepG2 (Tewhey et al. 2016), and fine-map variants associated with red blood cell traits in GWAS (Ulirsch et al. 2016). These and other approaches with higher scalability and efficiency are necessary to validate and understand the validity of computational predictions and statistical associations for likely causal genetic variants.
In addition to using reporter assays to measure enhancer function on gene expression, there are several methods to directly measure binding affinity of DNA sequences for specific transcription factors. These methods include Spec-seq (Stormo et al. 2015), electrophoretic mobility shift assay-sequencing (EMSA-seq) (Wong et al. 2011), and Binding to Designed Library, Extracting, and sequencing (BUNDLE-seq) (Levo et al. 2015). In these assays, synthesized regions are combined in vitro with a purified transcription factor. The bound DNA-factor complexes are then isolated by polyacrylamide gel electrophoresis (PAGE), where sequencing of the derived libraries allows for quantification of the binding strength of regulatory regions. The benefit to these methods is that it is possible to assay any potential genetic variant of interest. In vivo methods (such as DNase-seq, ChIP-seq), instead, are limited to existing variation within a given sample. Also, in vivo methods cannot look at each transcription factor separately to identify the specific factor directly causing the change in binding, as the binding could be indirect with any number of cofactors. Although BUNDLE-seq compared binding and reporter gene expression, and EMSA has been previously used to ascertain allelic effects, none of the high-throughput EMSA methods have been used to determine allelic effects on binding.
Results
We have developed a new streamlined method called Biallelic Targeted STARR-seq (BiT-STARR-seq) to test for allele-specific effects in regulatory regions (Fig. 1A; Supplemental Fig. S1). We selected different categories of regulatory variants for this study, including eQTLs (Innocenti et al. 2011; Wen et al. 2015), CentiSNPs (Moyerbrailean et al. 2016b), ASB SNPs (Moyerbrailean et al. 2016b), variants associated with complex traits in GWAS (Pickrell 2014), and negative ASB controls (Moyerbrailean et al. 2016b) for a total of 50,609 SNPs (Methods). We designed two oligos targeting each of the alleles for a SNP and containing the regulatory region (200 bp) centered on the SNP (Fig. 1A; Supplemental Fig. S1; Methods). We also included the use of unique molecular identifiers (UMIs), added during cDNA synthesis. With these random UMIs we are in effect tagging identifiable replicates of the self-transcribing construct, which improves the analysis of the data by accounting for PCR duplicates. Our protocol also has the advantage of being highly streamlined. Unlike STARR-seq, our method does not require preparation of DNA regions for use in the assay, such as whole-genome fragmentation (Arnold et al. 2013) or targeting regions (Vanhille et al. 2015), although, similar to STARR-seq, it requires only a single cloning and transformation step. Because the UMIs are inserted after transfection, there are no additional bottleneck issues (due to library complexity) in the cloning and transformation steps.
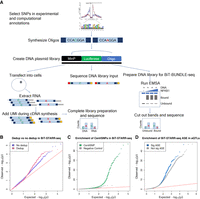
BiT-STARR-seq and BiT-BUNDLE-seq identify regulatory variants in noncoding regions. (A) Experimental outline. Oligos targeting the regulatory regions of interest (and either reference or alternate alleles) are designed to contain, on their ends, 15 bp matching the sequencing primers used for Illumina NGS. The DNA library is used both in the BiT-STARR-seq and BiT-BUNDLE-seq experiments. UMIs are added during cDNA synthesis for the BiT-STARR-seq RNA-seq library and prior to PAGE in the BiT-BUNDLE-seq protocol. (B) QQplot depicting the P-value distributions from QuASAR-MPRA for a single experimental replicate processed without removing duplicates (purple) or after removing duplicates using the UMIs (pink). (C) QQplot depicting the P-value distributions from the ASE test performed using QuASAR-MPRA on all replicates after removing duplicates. CentiSNPs are in green (Moyerbrailean et al. 2016b), and SNPs in the negative control group are in gray. (D) QQplot depicting the P-value distributions for eQTLs from Nédélec et al. (2016). SNPs with significant ASE (FDR < 10%) are in blue, and not significant ASE are in gray.
We generated seven replicates of the DNA library, which were highly and significantly correlated (Spearman's ρ = [0.97, 0.98], P-value <0.01) (Supplemental Fig. S2). The DNA library was then transfected in LCLs (nine biological replicates), and we were able to recover a total of 43,500 testable SNPs (for RNA counts filter, see Methods). Read counts for the nine biological replicates were highly correlated (Spearman's ρ = [0.35, 0.72], P-value <0.01) (Supplemental Fig. S3). To identify SNPs with allele-specific effects, we applied QuASAR-MPRA (Kalita et al. 2018). For each SNP, the reference and alternate allele counts were compared to the DNA proportion in the plasmid library. We identified a total of 2720 SNPs with ASE from the combined replicates (FDR < 10%) (Supplemental Table S1). To investigate the importance of UMIs in this experimental approach, we reanalyzed our data without removing duplicates. For the combined replicates, inflation (genomic inflation test) (Methods) is greatly increased (from 1.10 to 1.73). If only a single RNA library replicate is considered, the number of detected ASE is about fourfold reduced (Fig. 1B).
SNPs with ASE are significantly enriched for variants predicted to impact transcription factor binding (CentiSNPs) (Fisher's exact test OR = 2.49, P-value = 4.55 × 10−6) (Fig. 1C; Supplemental Fig. S4; Supplemental Tables S2, S5; Moyerbrailean et al. 2016b). Additionally, SNPs with ASE are enriched for low P-values in an eQTL mapping study performed in immune cells (Fig. 1D; Supplemental Table S4; Nédélec et al. 2016), thus confirming that our synthetic oligos can reproduce allele-specific regulatory effects observed in a native (non-episomal) cellular context.
Motif, regulatory region size, and chromatin context effects
The CentiSNP annotation is informative of the specific transcription factor motif being disrupted by a SNP. By leveraging this information, we were able to analyze allelic effects for specific transcription factor motifs (Fig. 2A; Supplemental Table S6). Additionally, by combining the ASE results with the direction of the motif, we can characterize whether the motif is active in both directions or only in one direction. This would suggest that some TF binding motifs tend to function specifically in one direction. We found that when both alleles are covered in both directions, the allelic effects on gene expression tend to agree in direction and magnitude. If we categorize these directional allelic effects per motif, we do not observe major differences with the notable exception of CTCF (Fig. 2B). Specifically, we find that SNPs in footprints for CTCF are significantly enriched (Fisher's exact test OR = 1.57, Bonferroni P = 0.02) for ASE when the direction of transcription of the reporter gene is opposite to that of the motif strand (Fig. 2C).
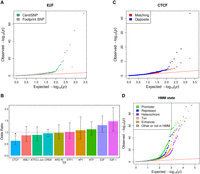
ASE for individual transcription factors. (A) QQplot depicting the ASE P-value distributions from QuASAR-MPRA, for SNPs overlapping with E2F footprint annotations. SNPs predicted to alter binding (CentiSNPs) are represented in green, and SNPs that are in E2F but predicted to have no effect on binding are in gray. (B) Enrichment for ASE in individual transcription factor binding sites calculated when motif strand matched the BiT-STARR-seq oligo transcription direction. Odds ratio (y-axis) for each transcription factor tested (x-axis) is shown in the bar plot; error bars are the 95% CI from the Fisher's exact test. Odds ratios below the dotted line represent enrichment for opposite direction oligo/motif configuration. Stars are shown above significant results (Bonferroni adjusted P-value <0.05). (C) QQplot depicting the ASE P-value distributions from QuASAR-MPRA, overlapping with CTCF footprint annotations. The SNPs where the motif strand matches the BiT-STARR-seq oligo direction relative to the TSS are in red, and blue shows where the motif strand is the opposite of the BiT-STARR-seq direction. (D) QQplot depicting the ASE P-value distributions from QuASAR-MPRA, overlapping with chromatin state annotations.
Although oligos were designed to have the variant centered in the middle of the synthesized region, this does not necessarily mean that the SNP is centered in a DNase window (Supplemental Fig. S1). Although position within the window does not affect the ASE signal, the main effect seems to depend on the presence/absence of the tested site within the DNase window (Supplemental Fig. S5) and, in a lesser degree, it depends on the peak size (Supplemental Fig. S6). SNPs were originally selected based on the CentiSNP annotation, but when we considered chromatin states (Broad ChromHMM state), we detect enrichment for promoter state among SNPs with ASE (Fig. 2D).
Allele-specific binding for NFKB1
To understand the effect of a regulatory variant on complex traits, it is necessary to first dissect the molecular function that is impacted by the nucleotide change. The CentiSNP prediction provides specific hypotheses for allelic effects on transcription factor binding that can be directly tested through experimentation. Further matching ASB to ASE identified in BiT-STARR-seq would provide a complete molecular mechanism, from predicted binding effects, to experimentally validated binding effects, to validated effects on expression. Because of the enrichment of CentiSNPs among SNPs with ASE in BiT-STARR-seq, we performed BiT-BUNDLE-seq to validate their effect on transcription factor binding. This is a new and efficient extension of high-throughput reporter assays, because it uses the same input DNA library. We performed BiT-BUNDLE-seq with purified NFKB1 (at three different concentrations), which is an important regulator of the immune response in LCLs and other immune cells (Li and Verma 2002; Beinke and Ley 2004; Smale 2010). Previous studies have successfully identified ASB from ChIP-seq for all NF-κB subunits in LCLs (Martone et al. 2003; Lim et al. 2007; Heinz et al. 2010; Kasowski et al. 2010; Zhao et al. 2014; Jin et al. 2013) and NFKB1 footprints are induced in response to infection (Pacis et al. 2015). Additionally, NF-κB complex was found to be 50-fold enriched for reQTLs from response to Listeria and Salmonella (Nédélec et al. 2016).
We first analyzed NFKB1 binding between the bound and unbound libraries and identified 9361 significantly (logFC > 1 and FDR < 1%) overrepresented regions in the bound library (Supplemental Tables S7–S10). As expected, these regions were enriched (OR = 11.70–13.75, P-value = 7.95 × 10−27 to 1.23 × 10−15) for NF-κB complex footprints (Fig. 3A; Supplemental Fig. S7), with a higher portion of these regions in the middle concentration of NFKB1 compared with the low or high concentrations (Fig. 3B). We hypothesize that this is because the low concentration does not capture all of the NFKB1 binding, whereas the high concentration likely results in nonspecific binding. We then used ΔAST (Moyerbrailean et al. 2016a) to identify ASB in the bound library (compared with the unbound library) and combined the replicates using Stouffer's method (Methods; Fig. 3C). We successfully identified 386 SNPs at low concentration, 797 SNPs at middle concentration, and 894 SNPs at high concentration with significant ASB at FDR < 10% (Fig. 3D; Supplemental Fig. S8), for a total of 2684 SNPs when aggregating all experiments (Supplemental Tables S3, S11). These spanned our designed regulatory categories, with the greatest number covering CentiSNPs (Supplemental Table S12). When we considered these ASB SNPs in combination with the ASE results from the BiT-STARR-seq (Supplemental Fig. S9), we found that SNPs with ASE are enriched for NFKB1 ASB (Fisher's exact test, OR = 2.04, P-value = 1.51 × 10−16) (Fig. 3D). For ASB variants not showing ASE, we found that there is enrichment for these being in either the CREB1 or AML1 motifs (Fig. 3D; Supplemental Fig. S10; for Fisher's test, see Supplemental Table S13), which are factors known to antagonize NF-κB complex binding (Ollivier et al. 1996; Parry and Mackman 1997; Nakagawa et al. 2009, 2011).This confirms our hypothesis that disruption of NFKB1 binding is one of the mechanisms underlying allele-specific expression in our data set.
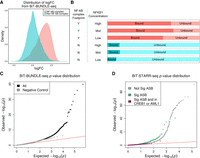
Allele-specific binding for NFKB1. (A) Density plot of the logFC (from DESeq2) between bound and unbound DNA fractions from the BiT-BUNDLE-seq experiment. Regions in red are those containing a SNP in a NF-κB complex footprint; regions in blue are those containing a SNP in footprints for other transcription factors. (B) Bar plot representing the number of independent enhancer regions in bound (dark color, DESeq2 logFC > 1 and FDR < 1%) and unbound (light color) DNA. NFKB1 concentration and presence of a NF-κB complex footprint are indicated in the two columns on the left of the panel. (C) QQplot depicting the P-value distributions from testing for ASB signal specific to the bound DNA fraction using ΔAST (black) and SNPs in the negative control group (gray). (D) QQplot depicting the ASE p-value distribution from QuASAR-MPRA for SNPs with significant (FDR < 10%) ASB (green), SNPs with significant (FDR < 10%) ASB and are also in CREB1 or AML1 footprints (maroon), or not significant ASB (gray) in the BiT-BUNDLE-seq experiment.
Overlap with signals from GWAS
We used ASB and ASE in combination with transcription factor binding motifs to assign mechanistic function to putatively causal SNPs linked to complex traits. We found 2054 CentiSNPs with ASB (P-value <0.05) and 1769 CentiSNPs with ASE (P-value <0.05) associated to a complex trait in the GWAS catalog (Supplemental Tables S14, S15) or from fgwas (Moyerbrailean et al. 2016b). Considering all SNPs tested, there are 173 SNPs that have both ASB and ASE (FDR < 10%), and 164 of them (95%) are also associated with a complex trait. We were able to dissect the molecular mechanism for rs3810936, a variant associated with risk for Crohn's disease in multiple populations (Fig. 4A,B; Yamazaki et al. 2005; Franke et al. 2010; Baskaran et al. 2014; Lee et al. 2015). This variant is a CentiSNP for the factor HMX3 (also known as NKX5-1), and we find ASB for NFKB1 (P-value = 0.006) in the BiT-BUNDLE-seq assay and ASE (P-value = 0.034) in both directions in the BiT-STARR-seq. This SNP is a synonymous variant in gene TNFSF15 (also known as TL1A), which encodes for a cytokine that belongs to the tumor necrosis factor (TNF) ligand family.
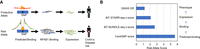
Overlap with GWAS. (A) Integration of prediction, BiT-BUNDLE-seq, BiT-STARR-seq, and GWAS results for Crohn's disease risk variant rs3810936. Triangles represent transcription factors. (B) A comparison of allelic effects from computational prediction to phenotype for rs3810936. Predicted log odds score is the reference prior log odds–alternate log odds from the CentiSNP annotation. BiT-BUNDLE-seq Z-score is the Z-score from the metaanalysis of ASB from all three concentrations of NFKB1. BiT-STARR-seq Z-score is the Z-score from metaanalysis of ASE for nine experimental replicates. GWAS OR is the odds ratio from rs3810936 alternate allele with Crohn's disease (Yamazaki et al. 2005; Franke et al. 2010; Baskaran et al. 2014; Lee et al. 2015). All scores are signed relative to the risk allele, which is the alternate allele.
Increased TL1A expression has been reported in inflamed Crohn's disease tissue, compared with noninflamed areas, and in ulcerative colitis patient serum (Bamias et al. 2003, 2010; Prehn et al. 2004). TL1A gives costimulatory signals to activated lymphocytes through binding to TNFRSF25 (also known as DR3) (Migone et al. 2002), which induces the secretion of interferon gamma (IFNG) (Prehn et al. 2004; Papadakis et al. 2005). This gene modulates Th-1 and Th-17 (Bamias et al. 2003; Takedatsu et al. 2008), creating an immunological state that leads to the mucosal inflammation of Crohn's disease. Stimulation of the TL1A pathway, in monocytes and T cells from patients carrying the disease-associated TL1A SNPs, showed higher levels of TL1A expression, therefore aberrant TL1A expression may be a factor driving IBD development (Kakuta et al. 2009; Michelsen et al. 2009). In addition, this gene has been found to be down-regulated in response to dexamethasone (Moyerbrailean et al. 2016a), a corticosteroid used to treat many inflammatory and autoimmune conditions. Although this variant is not found in ChIP-seq from ENCODE, ENCODE studies used RELA (also known as p65) for NF-κB subunit, where our study used NFKB1 (also known as p50). We therefore identify a novel variant that disrupts binding of NFKB1, where the alternate allele (C) has increased binding. This leads to an increase in gene expression for the alternate allele, which is also the risk allele for Crohn's disease (OR = 1.21, P-value = 1 × 10−15).
Discussion
The recent adaptation of MPRA to investigate ASE allows for validation of regulatory variants in transcription factor binding sites, which have been shown to be functionally relevant to fine-map eQTLs (Tewhey et al. 2016) and GWAS signals (Ulirsch et al. 2016). However, the use of functional genomics to select relevant regions prior to experimental validation can reduce the number of sites it is necessary to validate. We developed a high-throughput reporter assay that synthesizes these selected regions (similar to MPRA), clones them in 3′ of the reporter gene (similar to STARR-seq), and includes the addition of a UMI during cDNA synthesis (new to our protocol). This is the most streamlined protocol to date and allows for removal of PCR duplicates, which reduces noise in the data for greater power to detect ASE.
Our results show that using existing annotations to prioritize regulatory variants for high-throughput reporter assays is an effective strategy. The CentiSNP annotation, in particular, contains information that can be used to analyze ASB/ASE for individual transcription factor motifs and investigate potential molecular mechanisms of action. We found that direction is an important factor in the case of CTCF, most likely due to how CTCF functions as an insulator between the enhancer and the promoter when they are in anti-parallel directions. Previous studies have shown that CTCF, a well-characterized insulator, has binding sites at the anchors of chromatin loops. These are arranged in forward–reverse orientations (Guo et al. 2012, 2015; Monahan et al. 2012; Alt et al. 2013; Rao et al. 2014; Vietri Rudan et al. 2015), where the relative positions and orientations of the binding sites are important for the mechanism of action (Guo et al. 2015). In our case, the interaction could be mediated either by the basal transcriptional machinery at the TSS and/or an additional weak CTCF binding site (M01259) that is present in the promoter and could help to establish a DNA loop. However, there may be alternative explanations for this result because reporter assays may not reflect the native regulatory landscape in human cells (Huerfano et al. 2013; Muerdter et al. 2017).
Generally, caution should be used in interpreting reporter assay gene expression differences across cell types, because transfection may perturb the cell state. However, it is important to highlight that any trans-acting effects (e.g., promoter strength, type 1 interferon response activation) should affect both alleles similarly and therefore should not induce false positives in the allele-specific signal.
We used our library of oligos also in a BiT-BUNDLE-seq assay for identification of ASB for NFKB1. This is a novel approach to combine ASB and ASE identification in high-throughput assays using the same sequences. Our results show that this integration is a useful approach to validate the molecular mechanism for specific transcription factors. Allelic effects on transcription factor binding and gene expression are not always concordant. Some of this discordance is due to lack of power to detect ASB/ASE overlap, as well as other technical considerations. For example, in BiT-BUNDLE-seq, only one single TF (NFKB1) is available for binding, whereas in BiT-STARR-seq, other cofactors are present in the cell to affect binding. Additionally, there can be discordance in direction of effect, where, for example, an allele can lead to increased binding of a factor with repressing activity on gene expression (e.g., variants in CREB1/AML1 binding sites). These regulatory events are likely to be captured in the BiT-STARR-seq assay, which is performed in LCLs where CREB1, AML1, and NFKB1 are active. These results highlight that multiple types of assays are necessary to capture the detailed molecular mechanism of gene regulation. Additionally, integration with GWAS can identify and further characterize the molecular mechanisms linking causal genetic variants with complex traits.
Methods
BiT-STARR-seq
Supplemental Tables S2–S4 report the annotations we have considered with their sources, and Supplemental Tables S16 and S12 include the library composition. Each regulatory region was designed to have two oligos: one for each of the alleles. DNA inserts 230 bp long, corresponding to 200 bp of regulatory sequence, were synthesized by Agilent to contain the regulatory region and the SNP of interest within the first 150 bp (Supplemental Fig. S1). We performed a first round of PCR to generate double-stranded oligos and complete the sequencing primers, followed by a subsequent round of PCR to amplify the material. Plasmid pGL4.23 (Promega) was linearized using CloneAmp HiFi PCR Premix (Clontech) primers [STARR_F_SH and STARR_R_SH]. Inserts were cloned into the linear plasmid using standard In-Fusion (Clontech) cloning protocol. Clones (Supplemental Methods, BiT-STARR-seq plasmid) were transformed into XL10-Gold Ultracompetent Cells (Agilent) in a total of seven reactions. DNA was extracted using EndoFree maxiprep kit (Qiagen).
The DNA library was transfected into LCLs (GM18507) using standard nucleofection protocol, program DS150. We performed nine biological replicates of the transfection from seven independent cell cultures. After transfection, cells were incubated at 37°C and 5% CO2 in RPMI1640 with 15% FBS and 1% Gentamycin for 24 h. Cell pellets were then lysed using RLT lysis buffer (Qiagen) and cryopreserved at −80°C. For RNA libraries, total RNA was isolated from the thawed lysates using RNeasy Plus Mini Kit (Qiagen). RNA-seq libraries from the polyadenylated RNA were prepared using a custom protocol described in the Supplemental Methods (library preparation). We prepared seven replicates of the DNA library using a modified version of the PCR protocol as previously described (Buenrostro et al. 2013; Supplemental Methods, library preparation).
BiT-BUNDLE-seq
We developed BiT-BUNDLE-seq, by modifying the design of the BUNDLE-seq protocol (Levo et al. 2015). Specifically, input DNA sequences were extracted from the BiT-STARR-seq DNA plasmid library. We used N-terminal GST-tagged, recombinant human NFKB1 from EMD Millipore. Experiments were performed in triplicates for each NFKB1 concentration. Libraries extracted from the bound and unbound DNA bands after PAGE were quantified and loaded on the Illumina NextSeq 500 for sequencing. The full-length protocol can be found in Supplemental Methods (BiT-STARR-seq protocol).
Data processing
Reads were mapped using the HISAT2 aligner (Kim et al. 2015), using the “genome_snp” GRCh37 index (ftp://ftp.ccb.jhu.edu/pub/infphilo/hisat2/data/grch37_snp.tar.gz) so as to avoid reference bias. Realigning the reads to GRCh38 should not affect the conclusions as any problematic region of the genome is excluded from any analysis (Supplemental Methods, oligo selection and design). We then ran UMItools (Smith et al. 2017) using standard flags to remove duplicates. To identify SNPs with allele-specific effects, we applied QuASAR-MPRA (Kalita et al. 2018), in which for each SNP the reference and alternate allele counts were compared to the DNA proportion. QuASAR-MPRA results from each replicate were then combined using the fixed effects method and corrected for multiple tests (Benjamini and Hochberg 1995).
Each replicate for the bound and unbound libraries from BiT-BUNDLE-seq were run through QuASAR-MPRA using the calculated reference proportion (combined unbound and bound DNA). These were then compared using ΔAST (Moyerbrailean et al. 2016a) to identify ASB in the bound fraction that is differential relative to the unbound fraction. The replicates were combined using Stouffer's method (Stouffer et al. 1949) to identify ASB for each NFKB1 concentration and combined again to identify the total ASB. Libraries were additionally analyzed with DESeq2 (Love et al. 2014) to discriminate between bound and unbound constructs.
Data access
The sequencing data from this study have been submitted to the NCBI Sequence Read Archive (SRA; https://www.ncbi.nlm.nih.gov/sra) under accession number SRP154945.
Acknowledgments
Funding to support this research was provided by the National Institutes of Health (NIH, National Institute of General Medical Sciences) R01GM109215 (R.P.-R., F.L.), American Heart Association (AHA) 14SDG20450118 (F.L.), NIH (National Heart, Lung, and Blood Institute) R01HL133218 (C.D.B.), and AHA 17PRE33460295 (C.A.K.). We thank Wayne State University HPC Grid for computational resources, members of the Luca/Pique group for helpful comments and discussions, and Luis Barreiro for making the re-QTL data available. In addition, we thank the anonymous reviewers for their comments and suggestions.
Footnotes
-
[Supplemental material is available for this article.]
-
Article published online before print. Article, supplemental material, and publication date are at http://www.genome.org/cgi/doi/10.1101/gr.237354.118.
-
Freely available online through the Genome Research Open Access option.
- Received March 26, 2018.
- Accepted September 20, 2018.
This article, published in Genome Research, is available under a Creative Commons License (Attribution 4.0 International), as described at http://creativecommons.org/licenses/by/4.0/.








