
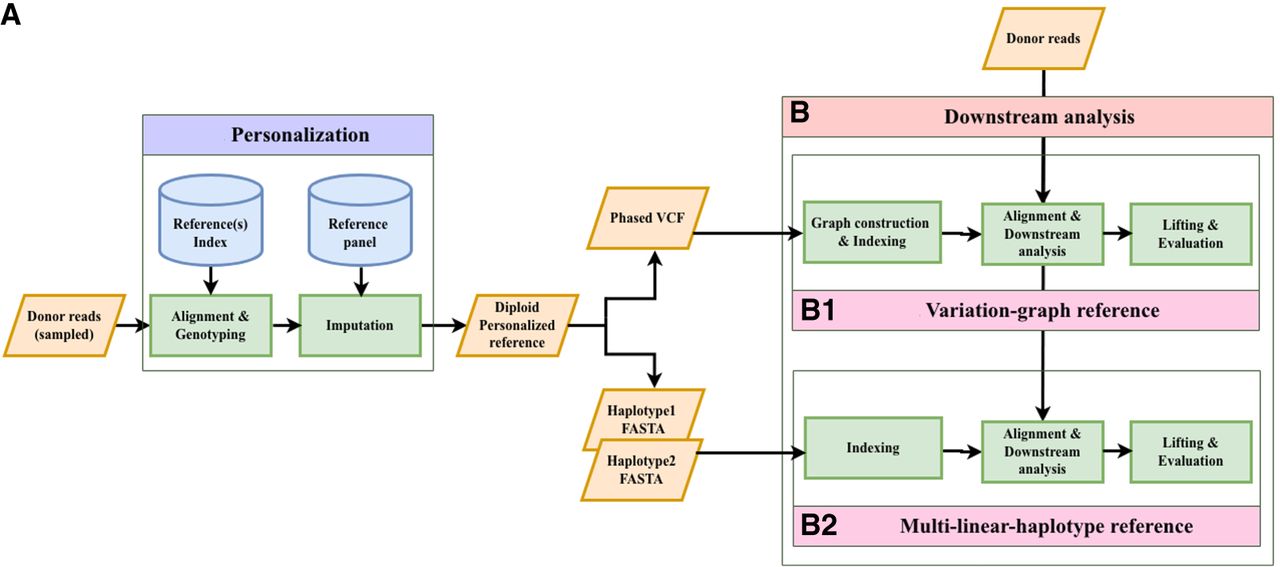
Figure 1.
Impute-first alignment workflow in the context of analyzing a human whole-genome sequencing data set. (A) The workflow up until it creates a personalized diploid reference. This is the “personalization” component. (B) Continues the workflow by aligning the full set of reads to the personalized reference. This is the “downstream” component.








