
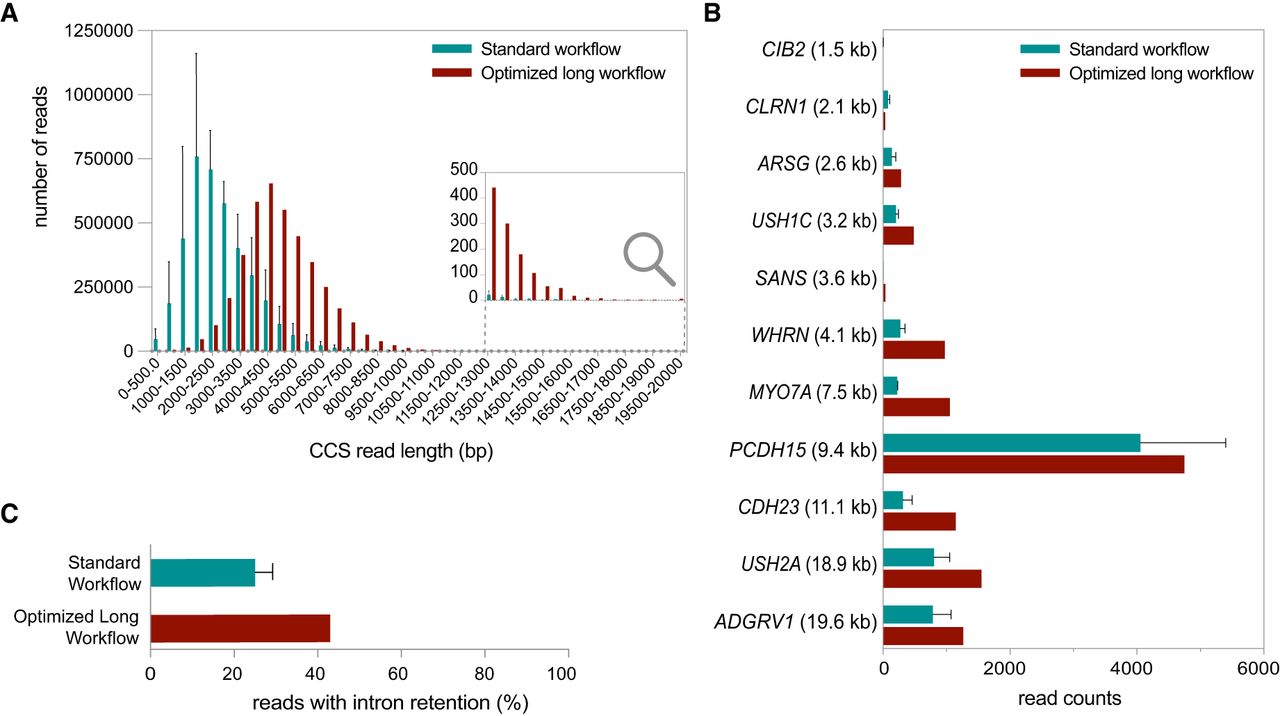
Exploring the Usher syndrome–associated transcript isoform landscape in the human neural retina using PacBio long-read mRNA Iso-Seq. (A) The size distribution of sequenced transcripts derived from the standard workflow (blue) and optimized long workflow (red) data sets. For the standard workflow data set, the mean size distribution across the three sequenced samples is depicted ± standard deviation (SD). (B) Comparison of Usher syndrome–associated transcript coverage between the standard workflow and optimized long workflow data set. The Usher genes are arranged in order from smallest to largest coding sequence, with the coding sequence length of the largest known transcript for each gene provided in brackets. For the standard workflow data set, the mean ± SD transcript length across the three sequenced samples is presented. (C) Quantification of the percentage of reads displaying intron retention in standard workflow samples 1–3 (mean of 3 samples ± SD) versus long workflow sample 4.








