
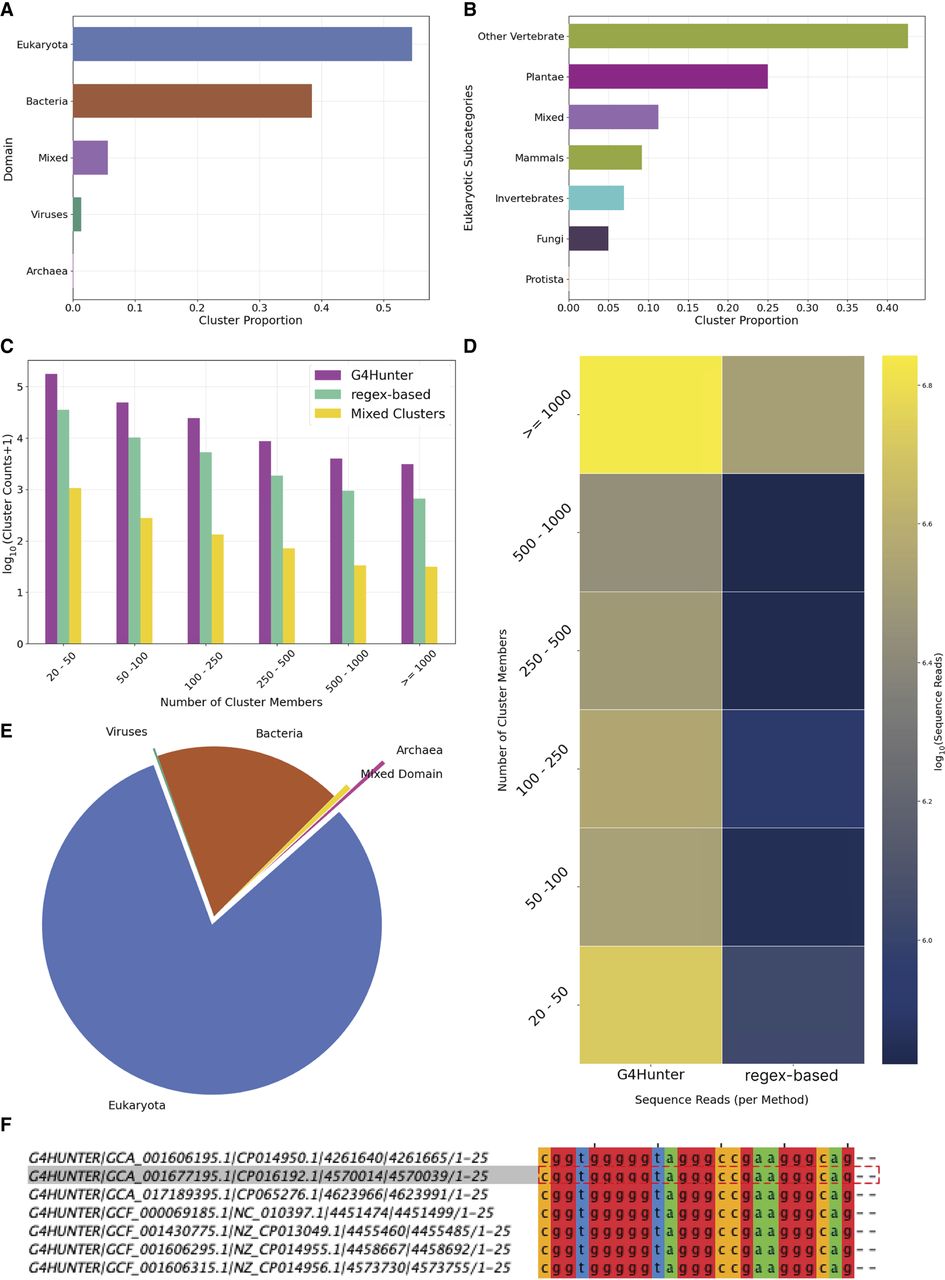
Clustering analysis of G4 sequences. (A) Proportion of total G4 clusters identified in each of the three domains of life and viruses, as well as those clusters that were found in at least two of these (mixed). (B) Proportion of clusters observed in each of the kingdoms of life. (C) Number of clusters based on the number of G4 sequences being members. Results are shown for the regex algorithm and the G4 Hunter algorithm. (D) Number of cluster members. Sequence reads were defined as the total number of G4s detected within the indicated cluster. (E) Origin of G4 clusters as a proportion of total sequences. (F) Example of G4 cluster showing the loci of the G4 sequences, and the associated sequence alignment.








