
Artificial intelligence and machine learning in cell-free-DNA-based diagnostics
- W.H. Adrian Tsui1,2,3,
- Spencer C. Ding1,2,3,
- Peiyong Jiang1,2,3,4 and
- Y.M. Dennis Lo1,2,3,4
- 1Center for Novostics, Hong Kong Science Park, Pak Shek Kok, New Territories, Hong Kong SAR, China;
- 2Li Ka Shing Institute of Health Sciences, The Chinese University of Hong Kong, Shatin, New Territories, Hong Kong SAR, China;
- 3Department of Chemical Pathology, The Chinese University of Hong Kong, Shatin, New Territories, Hong Kong SAR, China;
- 4State Key Laboratory of Translational Oncology, The Chinese University of Hong Kong, Shatin, New Territories, Hong Kong SAR, China
Abstract
The discovery of circulating fetal and tumor cell-free DNA (cfDNA) molecules in plasma has opened up tremendous opportunities in noninvasive diagnostics such as the detection of fetal chromosomal aneuploidies and cancers and in posttransplantation monitoring. The advent of high-throughput sequencing technologies makes it possible to scrutinize the characteristics of cfDNA molecules, opening up the fields of cfDNA genetics, epigenetics, transcriptomics, and fragmentomics, providing a plethora of biomarkers. Machine learning (ML) and/or artificial intelligence (AI) technologies that are known for their ability to integrate high-dimensional features have recently been applied to the field of liquid biopsy. In this review, we highlight various AI and ML approaches in cfDNA-based diagnostics. We first introduce the biology of cell-free DNA and basic concepts of ML and AI technologies. We then discuss selected examples of ML- or AI-based applications in noninvasive prenatal testing and cancer liquid biopsy. These applications include the deduction of fetal DNA fraction, plasma DNA tissue mapping, and cancer detection and localization. Finally, we offer perspectives on the future direction of using ML and AI technologies to leverage cfDNA fragmentation patterns in terms of methylomic and transcriptional investigations.
The biology of cell-free DNA
Cell-free DNA (cfDNA) represents fragmented DNA molecules in the bloodstream, urine, saliva, or other bodily fluids but not encapsulated within cells. Many studies focus on circulating plasma DNA, unveiling a number of important biological features such as its tissues of origin and characteristic fragmentation patterns (Lo et al. 2021). Early interest in cfDNA was driven by the identification of circulating tumor DNA (ctDNA) in the plasma of cancer patients (Stroun et al. 1989; Nawroz et al. 1996), offering a means of noninvasive cancer detection and design of targeted therapy (Kwapisz 2017). A parallel development is the discovery of fetal DNA in the maternal plasma (Lo et al. 1997), opening up possibilities in noninvasive prenatal testing (NIPT), especially in the prenatal screening of fetal chromosomal aneuploidies (Chiu et al. 2008, 2011). Subsequently, the identification of donor-derived DNA in the plasma of organ transplant recipients (Lo et al. 1998a) has sparked interest in noninvasive approaches for monitoring organ rejection (De Vlaminck et al. 2014; Schütz et al. 2017; Keller and Agbor-Enoh 2021; Khush et al. 2021; Bu et al. 2022; Cheng et al. 2022; Keller et al. 2024).
Several mechanisms for cfDNA release have been proposed, such as apoptosis, necrosis, and NETosis, or active cellular secretion (Grabuschnig et al. 2020; Han and Lo 2021), but their relative involvement in the shedding of cfDNA into plasma remains unclear. On the other hand, exciting progress has been made on cfDNA fragmentation processes, and a number of fragmentomics markers have been developed (Han et al. 2020; Lo et al. 2021). It is known that human plasma DNA shows a modal length of ∼166 bp, reflecting the length of DNA associated with a nucleosome plus linker. Fetal- and tumor-derived cfDNA molecules exhibit a shorter modal size of ∼143 bp (Lo et al. 2010; Chandrananda et al. 2015), opening up possibilities for size-based enrichment of fetal and tumoral signals. Fragments <143 bp exhibit a 10 bp size periodicity (Lo et al. 2010; Mouliere et al. 2018), which provides a mechanistic link between cfDNA fragmentation and nuclease-mediated cleavages acting on the exposed groove of the nucleosome-bound DNA double helix (Noll 1974). Indeed, many studies suggest that a proportion of cfDNA molecules circulate in the bloodstream as cell-free nucleosomes (Sadeh et al. 2021; Fedyuk et al. 2023). Interestingly, the levels of these circulating nucleosomes and their posttranslational histone modifications differ in the plasma of individuals with cancer compared with those without, as well as across different cancer types (Sadeh et al. 2021; Fedyuk et al. 2023).
There is evidence that the fragmentation patterns at the ends of cfDNA fragments are nonrandom. In particular, the distributions of nucleotides at cfDNA ends are not uniform across all possible permutations (Serpas et al. 2019). Currently, these patterns in end motifs are believed to be partly caused by the action of nucleases, such as deoxyribonuclease 1 (DNASE1), deoxyribonuclease 1L3 (DNASE1L3), and DNA fragmentation factor subunit beta (DFFB) (Han and Lo 2021). It is known that nucleases like DFFB and DNASE1L3 play important roles in apoptotic DNA fragmentation (Widlak and Garrard 2009; Mizuta et al. 2013; Keyel 2017). Some nucleases, like DNASE1L3 and DNASE1, show tissue-specific patterns of expression (Keyel 2017). Furthermore, secreted DNASE1L3 and DNASE1 are believed to be major contributors to serum DNase activity (Napirei et al. 2009), which may be important for the clearance of serum DNA/chromatin complexes (Sisirak et al. 2016). Indeed, loss of function in Dnase1l3 or Dnase1 is associated with systemic lupus erythematosus (SLE) in humans and mice (Napirei et al. 2000; Al-Mayouf et al. 2011).
Using genetically modified mice in which one or more nuclease genes had been knocked out, the action of individual nucleases could be studied (Serpas et al. 2019; Han et al. 2020; Chen et al. 2022a). Mice with homozygous Dnase1 deletion exhibited no obvious alteration in overall fragment length distribution. However, when the Dnase1l3 gene was knocked out, there was an increase in the proportions of di- and trinucleosomal plasma DNA molecules (Serpas et al. 2019). Additionally, the relative frequencies of specific four-base motifs at the 5′ ends of plasma DNA fragments were significantly perturbed in Dnase1l3 knockout mice, in which the six most decreased end motifs all began with “CC” (Serpas et al. 2019). Therefore, DNASE1L3 likely contributes to the generation of fragments with CC-ends in plasma. Extending this work, Han and colleagues (2020) demonstrated the distinct roles of DNASE1, DNASE1L3, and DFFB on cfDNA cleavage by studying cfDNA fragmentation in plasma samples undergoing in vitro incubation in the presence of heparin or EDTA, showing that DNASE1 and DFFB preferentially generate T-end and A-end fragments, respectively. Apart from patterns in nucleotide composition, nuclease activity has also been shown to be associated with the recently discovered single-stranded overhangs on dsDNA, known as jagged ends (Jiang et al. 2020b; Ding et al. 2022).
The involvement of various DNA nucleases in cfDNA fragmentation could retrospectively explain, in part, the observation that the ends of cfDNA fragments preferentially occurred at certain genomic coordinates, referred to as “preferred ends” (Chan et al. 2016; Jiang et al. 2018). Differential patterns of preferred ends were described between the maternal and fetal genomes (Chan et al. 2016), as well as between the tumor and nontumor genomes (Jiang et al. 2018). This unevenness of genome-wide fragmentation patterns has also been parameterized in the “window protection score” for nucleosome footprinting (Snyder et al. 2016; Straver et al. 2016). Together, these studies highlight that patterns of cfDNA fragmentation are intimately linked to chromatin architecture, such as nucleosome arrays, sites of other DNA-binding proteins (e.g., CCCTC-binding factor [CTCF]), and open chromatin regions that are associated with transcriptional activity.
As cfDNA molecules exhibiting these characteristic fragmentation patterns can be shed from different tissues into the circulation, it is diagnostically useful to dissect the tissues of origin of cfDNA. In this regard, many studies have demonstrated that methylation analysis of plasma cfDNA allows tissue-of-origin tracing of cfDNA in plasma (Luo et al. 2021; Oberhofer et al. 2022). These studies reveal that cfDNA is derived from a variety of tissues and cell types in which the major contributor is hematopoietic cells, whereas other solid tissues such as the liver also have appreciable contributions (Sun et al. 2015; Moss et al. 2018). Furthermore, tissue-of-origin analyses can serve to pinpoint the site of pathology (Sun et al. 2015; Kang et al. 2017; Moss et al. 2018) and determine the tissue origin of cancers of unknown primary (Conway et al. 2024). Recently, the compilation of a high-resolution human methylome atlas consisting of 39 cell types sorted from 205 healthy tissue samples (Loyfer et al. 2023) has provided a valuable resource for developing tissue-specific methylation biomarkers for future tissue-of-origin studies.
Taken together, many methylomic and fragmentomic features of cfDNA molecules have recently come into the spotlight, promising to expand our knowledge of cfDNA biology and their clinical applications. Advancements in analytical and bioinformatic tools based on artificial intelligence (AI) and machine learning (ML) can exploit these features holistically to augment the performance of cfDNA-based diagnostics (Fig. 1). In this review, we particularly elaborate on AI and ML technologies that are applied in cfDNA-based diagnostics, such as noninvasive prenatal testing and cancer detection.
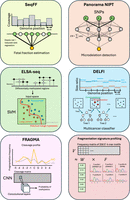
ML algorithms exploit cfDNA features for applications in NIPT, cancer liquid biopsies, and emerging areas of cfDNA biology. (Upper left) SeqFF uses elastic net to process local coverage in 50 kb genome-wide bins for fetal fraction estimation. (Upper right) Natera uses DNN to process linkage information between SNPs for microdeletion detection. (Middle left) SVM was used to detect lung cancer using the methylation status of selected differentially methylated regions (DMRs). (Middle right) The DELFI algorithm feeds local size and coverage profiles into a gradient boosting model to achieve multicancer detection. (Lower left) In one implementation of FRAGMA, a CNN is used to analyze the cleavage around a differentially methylated CpG site to determine CpG methylation status. (Lower right) NMF deconvolution of the frequencies of 256 5′ 4-mer end motifs yields “founder” profiles of potential biological significance.
Introduction of AI and ML
AI and ML are now commonly used interchangeably to refer to computer-based models that identify meaningful patterns in a bulk of information to build classification and prediction models based on training data. However, the meaning of AI and ML has shifted over time, and so, it is notoriously difficult to define these two terms (Hoffmann 2022). Historically, AI was proposed by Alan Turing as the capacity for a machine to “think” in such a way that a human cannot, in blinded conversation, distinguish between the machine and a real human (Turing 1950; Muggleton 2014; Wooldridge 2021). According to Turing, the behavior of such a machine would most likely be learned from data that were provided externally (Turing 1950). This process is now called machine learning (ML), for which many algorithms have been developed to perform different functions (Table 1). Many authors thus define ML as a subdiscipline of AI (Alloghani et al. 2020; Mueller and Massaron 2021; Hoffmann 2022).
A list of common supervised and unsupervised ML/AI algorithms
The theoretical basis for AI was proposed in the 1940s–1950s (McCulloch and Pitts 1943; Rosenblatt 1958), which involved modeling the activity of a small number of neurons. However, these simple models were far from being able to simulate the more complex behavior needed for tasks above just arithmetic, let alone truly intelligent behavior (Wooldridge 2021). The explosive increase of computational power in the twenty-first century enabled deep learning, which uses “deep” neural networks (DNNs), to be applied widely (Hoffmann 2022). Because of the analogies to neuronal mechanics in the brain, deep learning is now commonly referred to as AI-based technologies. In contrast, ML is now more generally used to describe other types of classifiers (such as support vector machines [SVMs]) or regressors. We shall henceforth use “ML” as a general term covering both classical ML and deep learning and shall use “AI” to refer specifically to deep learning.
ML can be primarily divided into three types according to the desired outcomes: classification, clustering, and regression. Both classification and regression are considered “supervised” learning, for which the model parameters are established based on samples with known class labels (Alloghani et al. 2020). Classification models return categorical variables as the final output (e.g., a pregnancy involving a normal or trisomic fetus), whereas regression models return continuous variables (e.g., fetal DNA fraction in maternal plasma). On the other hand, unsupervised learning is when the analysis is performed without relevant labels, such as in clustering algorithms that organize data into subgroups. Both classical and AI-based supervised and unsupervised learning (Table 1) have been applied in a wide range of studies, including fragmentomic-based cancer detection (Cristiano et al. 2019; Jiang et al. 2020a), cfDNA tissue-of-origin deconvolution (Li et al. 2023b), and direct methylation analysis in single-molecule real-time (SMRT) sequencing (Tse et al. 2021).
An essential component in ML is to find the best model parameters that achieve the desired performance of classification or regression through iterative optimization (Sun et al. 2020; Greener et al. 2022). The difference between predictions from the model and the actual values is parameterized by a loss function, so that a lower value of the loss function indicates better model performance (Ciampiconi et al. 2023). Hence, the main goal of optimization algorithms such as gradient descent is to iteratively adjust the model parameters to minimize the loss function. Gradient descent calculates the gradient of the loss function and iteratively updates the parameters in the opposite direction of the gradient, thus finding a local minimum. The design of the loss function directly affects the model function (Efron and Hastie 2016; Ciampiconi et al. 2023): For example, LASSO regression adds an L1-penalty term to the loss function, which has the effect of pruning less informative features from the model, and so essentially performs feature selection alongside the main regression task.
Deep learning
Recently, deep learning–based AI technologies have been introduced into genomic data analysis. Deep learning is based on DNNs, which are constructed from multiple layers of interconnected neurons. Fundamentally, each “neuron” is a function that takes in multiple weighted inputs and a bias to compute an output, which is then sent to the next neuronal layer (McCulloch and Pitts 1943; Rosenblatt 1958). The bias in a neuron is defined as a constant that is added to the product of input features and weights. This bias can tune the response of the neuron (such as its activation threshold) to various input conditions, making the neural network more robust and capable of handling complex patterns. The resulting network is able to perform complex tasks because many simple operations are carried out in a massively parallel manner (Bishop 1995). Compared with the commonly used ML algorithms mentioned above, the number of optimizable parameters—weights and biases—in a DNN is often much larger than the number of input features. For example, if a DNN takes 10 initial inputs, two hidden layers of five and four neurons each, and an output layer of three neurons, the number of weights is (10 × 5) + (5 × 4) + (4 × 3) = 82; the number of biases is 5 + 4 + 3 = 12; and so, the total number of parameters in such a DNN is 82 + 12 = 94. In comparison, the number of parameters in a logistic regression (in this case, the coefficients) is equal to the number of input features: A logistic regression model with 10 features would have 10 parameters under training. More optimizable parameters in DNNs usually lead to better performance than the aforementioned classical ML algorithms, given that a sufficient number of training samples is used to train the model. A widely used rule of thumb is that the number of training data points should be 10 times the number of weights (Abu-Mostafa et al. 2012), but some authors have suggested a more conservative minimum ratio of 50 (Alwosheel et al. 2018). Thus, it is crucial that the training data set is sufficiently large to prevent data sparsity, and so DNNs cannot be appropriately applied to situations in which the number of training samples is lacking.
An example of AI-based approaches is direct methylation analysis using SMRT sequencing (Tse et al. 2021). 5-Methylcytosine (5mC) is the most common base modification, which plays important roles in genomic imprinting, X-Chromosome inactivation, and carcinogenesis (Smith and Meissner 2013). 5mC is classically detected using bisulfite sequencing (BS-seq), but BS-seq is destructive and reduces sequence complexity. BS-seq itself also cannot distinguish 5mC from 5-hydroxymethylcytosine (5hmC), which requires multiple enzymatic and chemical reactions to differentiate them, such as oxidation by 10–11 translocation enzymes (Hahn et al. 2015). On the other hand, “third-generation” sequencing such as SMRT or nanopore sequencing reads DNA directly. In SMRT sequencing, a DNA polymerase incorporates fluorescent nucleotides into the newly synthesized strand, and the kinetics of nucleotide incorporation (inter-pulse duration [IPD], and pulse width [PW]) are affected by base modifications. However, the difference in kinetics between C and 5mC is extremely subtle in SMRT sequencing, leading to challenges in methylation calling, and thus, many attempts have failed to achieve meaningful or practical accuracy for a decade (Clark et al. 2013). Tse and colleagues (2021) have developed an AI-based approach named the holistic kinetic (HK) model (Fig. 2), which takes into account the incorporation of kinetics and sequence context for every nucleotide within a measurement window, boosting the accuracy up to 90% from <5%. The kinetic signals are organized into a two-dimensional (2D) matrix depending on the sequence context, analogous to an image. A CNN is then applied to the 2D matrix to compute a probabilistic score for the methylation status of a CpG site. Even when trained on just 300,000 data points, the HK model achieves an area under the receiver operating characteristic (ROC) curve (AUC) of 0.95 in differentiating methylated and unmethylated cytosines. The HK model has proved to be a valuable technology in the methylation analysis of long cfDNA (>500 bp), which generally carries more CpG and SNPs than short fragments, and so intrinsically phases these informative loci to augment the power of disease detection (Yu et al. 2021, 2023a). Notably, Choy and colleagues (2022) use the HK model to determine the tissue of origin of individual long cfDNA molecules for the detection of HCC (AUC = 0.91). In addition, various deep learning algorithms have also been applied in nanopore sequencing for basecalling and detection of base modifications in a variety of biological contexts (Boža et al. 2017; Rang et al. 2018; Wick et al. 2019; Grumaz et al. 2020; Neumann et al. 2022; Yu et al. 2023b; Chan et al. 2024).
An example of AI-based technology for direct methylation analysis and its clinical applications on the basis of the holistic kinetic (HK) model. (Left) The principle of single-molecule real-time (SMRT) sequencing. Circular DNA templates are incorporated with nucleotides labeled with different fluorophores by a DNA polymerase located in a zero-mode waveguide (ZMW). During DNA polymerization, the kinetics of nucleotide incorporation, including inter-pulse duration (IPD) and pulse width (PW), are affected by base modifications. (Middle) The HK model, an AI-based method that employs a convolutional neural network (CNN). This model is trained using combined kinetic signals and sequence context from a large amount of measurement windows and is applied to the prediction of cytosine methylation status. The methylation probability for the CpG sites, ranging from zero to one, is computed using a sigmoid function at the output layer. (Right) Selected clinical applications of the HK model: (1) deducing the placenta-derived cfDNA by the methylation pattern of long cfDNA molecules, opening up possibilities of developing generic approaches for monogenetic diseases, and (2) detecting patients with cancers and determining the tumor origin of cancer (e.g., hepatocellular carcinoma [HCC]) according to methylation patterns of long cfDNA determined by the HK model.
The transformer has driven a recent revolution in deep learning (Vaswani et al. 2017; Lin et al. 2022). Transformers use a technique called multihead attention (Vaswani et al. 2017; de Santana Correia and Colombini 2022). First, the sequential data are broken down into “tokens,” which is the smallest unit of data that can be converted into a meaningful numerical representation for the model. Essentially, for each token, its relationships with other tokens are computed by a series of operations, and this is performed massively in parallel to capture different aspects of the relationships between tokens. These massively parallel operations of multihead attention in transformers are more computationally efficient and scalable than recurrent neural networks (RNNs), which perform operations sequentially, with each step depending on the output of the previous step.
The rise of transformers has led to exciting possibilities on the interface between AI and biology, for which protein structure prediction is a landmark example. In 2020, AlphaFold was able to predict the 3D structure of most proteins from the primary sequence to near-experimental accuracy using a DNN trained on 29,427 peptides (Senior et al. 2019, 2020). Just a year later, AlphaFold2 was launched, using a transformer architecture trained on 107 peptides to obtain accuracy competitive with experimental techniques such as X-ray crystallography (Jumper et al. 2021). AlphaFold3 extends its predictive power to protein–ligand, protein–nucleic acid, and antibody–antigen interactions (Abramson et al. 2024), demonstrating the generalizability of the transformer-based model. The success of AlphaFold has sparked great interest in adopting AI technologies in structural biology and beyond. More recently, ChatGPT has been an unprecedented success of the transformer architecture, using a large language model (LLM) with 175 billion parameters (as of GPT-3) trained on massive web corpora (Brown et al. 2020). The newest version, ChatGPT4, integrates text, vision, and audio into one unified model, marking an important step toward multimodal human–machine interaction. Inspired by ChatGPT, LLMs have also been used to predict protein structure, evolution, and function with high confidence and speed without the need for multiple sequence alignment (Rives et al. 2021; Chowdhury et al. 2022; Lin et al. 2023; Johnson et al. 2024) and also to predict the effects of all approximately 450 million missense variants documented in the human genome (Brandes et al. 2023). In the cfDNA context, the recently invented HK model 2 (X Hu, Y Shi, SH Cheng, et al., in prep.) integrates a transformer architecture with the previously described CNN in HK model 1 (Tse et al. 2021), demonstrating enhanced 5mC versus C detection (AUC = 0.99) and HCC detection (AUC = 0.91) from plasma cfDNA. HK model 2 can also robustly distinguish 5hmC from 5mC (AUC = 0.97) and 6mA from A (AUC = 0.99).
Too many dimensions spoil the model
The huge number of tuning parameters in deep learning models necessitates the availability of large-scale training data sets. Adequate training data are crucial to combat the “curse” of dimensionality (Bellman 1961; Altman and Krzywinski 2018): In high-dimensional spaces, data become increasingly sparse as the search space grows exponentially with the dimensionality, and so, it becomes difficult to collect data that are representative of the population or to draw meaningful conclusions. As the flexibility of the prediction equations increases with dimensionality, the model becomes more prone to overfitting, which is when the model parameters capture intrinsic noise in the training data (Ying 2019). If the number of training samples is not proportionate to the number of parameters, even random noise can have undue effects on the model. Overfitted models perform poorly on new data sets and so are unreliable for making diagnostic decisions when faced with multifaceted clinical data. Despite the growing abundance of data available for training, data scarcity is still a major challenge when training deep learning models. On the other hand, classical ML algorithms may perform better in these instances, as their simplicity and reduced complexity allow them to adapt well to a smaller sample size, resulting in more stable and reliable model performance. Regardless of the model, a variety of approaches should be carefully considered in order to protect against overfitting, including dimensionality reduction and regularization, as well as model evaluation methods such as cross-validation and bootstrapping.
Dimensionality reduction and regularization
The “curse” of dimensionality may intuitively be addressed by reducing the number of dimensions of the parameter space by remapping the effective information to fewer dimensions through feature engineering algorithms (Jia et al. 2022) such as principal component analysis (PCA) and nonnegative matrix factorization (NMF). Along with reducing the number of dimensions, the effective size of each dimension can be constrained through regularization techniques. Regularization is an operation of deliberately calibrating model parameters to prevent overfitting or underfitting. Explicit regularization techniques in classical ML include L1 and L2 regularizations, which are used in ridge and LASSO regression, respectively, to shrink coefficients toward zero, so that no parameter unduly influences the model (Emmert-Streib and Dehmer 2019). In deep learning, early stopping during training and dropout of a certain proportion of neurons are important regularization algorithms that guard against overfitting (Greener et al. 2022). By concurrently monitoring the model performance on a validation set while training the model, early stopping halts model training when the validation performance begins to degrade. Dropout involves randomly excluding a fraction of the neurons during each training iteration, which theoretically prevents the model from overrelying on any single neuron, and also acts as an internal cross-validation mechanism.
Model evaluation
Cross-validation is an important step in ML model evaluation to monitor overfitting by training the model on different subsets of the training data and estimating the expected test error (Arlot and Celisse 2010; Ghojogh and Crowley 2023). Essentially, a data set containing n samples is split into k groups (also known as “folds”), the model is trained on k-1 groups, and then the model is used to predict the response of the remaining group (i.e., the validation/test set). If the model is overfit, the training error will be very small, but the test error will be large. By assessing the degree of model overfitting, cross-validation informs the maximum complexity to which the model can be trained before overfitting is risked.
For cross-validation, there exists a variety of splitting strategies, reviewed extensively elsewhere (Arlot and Celisse 2010). nCk is often computationally intractable, so partial data splitting methods such as k-fold cross-validation are used (Arlot and Celisse 2010). Crucially, the assumption that the data are independent and identically distributed (i.i.d.) must be examined: If a pair of samples are dependent, possibly because of confounding effects, having one sample in the training set and the other in the validation set would lead to “leakage” (discussed later). To address structural or temporal dependencies, blocked cross-validation may be considered, in which samples are partitioned into “blocks” whose size depends on the strength of correlation (Roberts et al. 2017; Yates et al. 2023).
In bootstrapping (Efron 1979), the training set is randomly sampled with replacements so that each bootstrap set is the same size as the training set. Applying the model to each bootstrap set gives a distribution of model prediction values. Simulations show that bootstrapping can perform comparably to k-fold cross-validation for model evaluation, the tradeoff being that it is more computationally expensive (Breiman and Spector 1992). In the majority of cases, the bootstrap distribution converges to the true population distribution as the number of bootstrap iterations tends to infinity (Chernick and LaBudde 2014). However, similar to cross-validation, bootstrapping may give inconsistent results if the sample size is too small or if the data are not i.i.d. (Chernick and LaBudde 2014).
Below, we shall discuss the applications of classical ML and deep learning–based AI technologies in NIPT, cancer liquid biopsies, and the development of the field of cfDNA fragmentomics (Fig. 3).
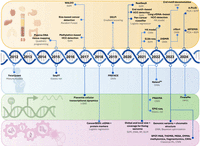
A timeline of applications of AI/ML algorithms to cfDNA analyses. Categories, from top to bottom: (orange) tissue-of-origin analyses and cancer liquid biopsies; (blue) noninvasive prenatal testing, including fetal fraction estimations; (green) fragmentomic-based methylomic and transcriptomic analyses; and (purple) multimodal cfDNA analyses, which leverage different cfDNA features in an integrated model. The name or a brief description of the technology is listed in bold, with the AI/ML algorithms used given below.
Noninvasive prenatal testing
The discovery of cell-free fetal DNA in maternal plasma (Lo et al. 1997) has facilitated a paradigm shift in prenatal testing, enabling applications such as noninvasive fetal RhD blood group genotyping (Lo et al. 1998a; Finning et al. 2008; Legler et al. 2021; Alford et al. 2023) fetal sex determination (Costa et al. 2002; Raman et al. 2019; Wu et al. 2023), detection of fetal chromosomal aneuploidies (Lo et al. 2007; Chiu et al. 2008, 2009, 2011; Fan et al. 2008; Straver et al. 2014; Yang et al. 2018; Paluoja et al. 2021; Lee et al. 2022a; Dar et al. 2022b; Schlaikjær Hartwig et al. 2023), subchromosomal structural aberrations (Fan et al. 2012; Srinivasan et al. 2013; Yu et al. 2013; Dar et al. 2022a), and diagnosis of monogenic diseases (Lo et al. 2010; Tsui et al. 2011; Lam et al. 2012; Ma et al. 2014; New et al. 2014; Yoo et al. 2015; Mohan et al. 2022).
NIPT requires sufficient fetal DNA amounts in a maternal sample, quantified as the fetal DNA fraction, for analytical and statistical robustness. The fetal DNA fraction is incorporated in mathematical models for calling fetal aneuploidies, such as in Illumina's VeriSeq NIPT solution v2 assay, and also for single gene disorder analysis. For the latter, relative mutation dosage (RMD) (Lun et al. 2008) and relative haplotype dosage (RHDO) (Lo et al. 2010) establish statistical thresholds for classifying fetal monogenic disorders from maternal plasma DNA analysis. RMD quantifies the allelic imbalance at a maternally heterozygous SNP (AB), in which the fetus being homozygous at that locus (AA/BB) would imbalance the allelic counts (Lun et al. 2008). In contrast to RMD, which analyzes a single genomic locus, RHDO uses parental genotypes to phase a series of fetal SNPs into haplotypes, increasing the performance of the analysis. A fetal DNA fraction of <4% would be commonly considered as “QC failure” for fetal chromosomal aneuploidy detection (Norton et al. 2012), although lower limits of down to 2% have been suggested (Fiorentino et al. 2016), and the threshold may vary according to the analytical platform used (Hestand et al. 2019; Becking et al. 2023).
Many methodologies have been developed to estimate the fetal DNA fraction in maternal plasma samples. Some approaches leverage fetal-specific sequences that are absent from the mother's genome, such as Y Chromosome–specific sequences (Lo et al. 1998b) and other paternally inherited sequences (Lo et al. 2010). Fetal-specific paternally inherited alleles include single-nucleotide polymorphisms (SNPs) in which the father is homozygous for a variant (AA) not carried by the mother (BB), and the fetal DNA fraction can be estimated by the ratio of A to B alleles in maternal plasma. However, Y-Chromosome analysis is only applicable to male fetuses. Methods that need parental genotypic information may present practical challenges, because only maternal blood samples would be collected for NIPT in most clinical settings, and the paternal genotype information may not be accurate owing to nonpaternity (Deignan et al. 2020).
To circumvent these difficulties, Jiang and colleagues (2012) developed a binomial mixture model (FetalQuant) that utilized maximum likelihood to estimate the fetal DNA fraction directly from target capture sequencing of maternal plasma. The allele ratios observed in maternal plasma would depend on the maternal and fetal genotypes and the fetal DNA fraction. At each SNP, there are four possible combinations of maternal and fetal genotypes: AAAA, AAAB, ABAA, and ABAB, in which the main text and subscript represent the maternal and fetal genotypes, respectively. If the fetal DNA fraction is f, the expected B allele fraction for each maternal–fetal genotype combination would be zero, f/2, 0.5 − f/2, and 0.5, respectively. As the allelic counts at each SNP follow a binomial distribution depending on the genotype combination, a binomial mixture model can be constructed using four binomial distributions parameterized by the expected B allele fractions. The fetal DNA fraction was iteratively tuned using expectation-maximization by fitting the observed allele ratios. An extension of this is that significant deviation from the expected allelic fractions for some SNPs may indicate fetal aneuploidy of a specific chromosome. Sparks and colleagues (2012) applied this algorithm to model allelic ratios in maternal plasma for fetal chromosomal aneuploidy detection, named FORTE.
Motivated by the differential cfDNA fragmentation patterns existing between fetal and maternal genomes (Lo et al. 2010), a generic method called SeqFF was developed to deduce the fetal DNA fraction from the same sequencing data used to generate the routine NIPT result, without any additional assays (Kim et al. 2015). SeqFF is based on the sequencing coverage signals across nonoverlapping 50 kb bins genome-wide (Fig. 1). The normalized read counts across bins were fitted into both a high-dimensional elastic net and a reduced-rank regression model with respect to fetal DNA fractions. Simple linear regression is the most straightforward approach to make predictions when a linear relationship between the features and outcomes is assumed, and it is fit by minimizing the cost function (sum of squared residuals), which parameterizes the difference between the predicted and observed values. However, it does not include any automated mechanism for feature selection: Each feature included in the model contributes to the explanation of the variance in the outcomes, regardless of the significance of its contribution, and is thus prone to overfitting when a large number of features is used (Bartlett et al. 2020). To protect against overfitting, regularization techniques penalize both the number and magnitude of the regression coefficients, such that the most informative coefficients are selected to meaningfully affect the model (Emmert-Streib and Dehmer 2019). Ridge regression (Hoerl and Kennard 1970) includes a regularization term that is added to the regression cost function, which forces less informative coefficients toward (but not exactly) zero. Although ridge regression can handle multicollinearity better than simple linear regression, it introduces bias to the model. Another regularization method is LASSO (Tibshirani 1996; Li et al. 2022), which is similar to ridge regression, but it assumes that the coefficients of the linear model are sparse, and hence, it shrinks the less informative coefficients to exactly zero. However, in some scenarios, an overstrict LASSO might overkill potentially informative features. Elastic net (Zou and Hastie 2005; Tay et al. 2023) combines both ridge and LASSO regression to attenuate their respective shortcomings, improving model accuracy and robustness. Importantly, elastic net introduces a key tuning parameter that balances the L1 and L2 regularization terms and thus achieves a compromise between variable selection and parameter shrinkage. Training of the elastic net used plasma sequencing data from 25,312 pregnant women and achieved a Pearson's correlation of >0.9 between predicted and actual fetal DNA fraction when applied to a validation set of 505 pregnant women (Kim et al. 2015). The results from the elastic net were averaged with those from reduced-rank regression to give the final fetal fraction estimate. In conclusion, SeqFF is applicable to both male and female pregnancies, can be integrated without additional cost into routine NIPT, and can greatly improve the accuracy of NIPT for fetal copy number aberrations.
More recently, deep learning has been applied to fetal fraction estimation in the PREFACE pipeline (Raman et al. 2019). Similar to SeqFF, PREFACE also uses local coverage information in genomic bins as its input variables, which are clustered into a set of linearly uncorrelated components by PCA. These new parameters are then fed into a DNN with two hidden layers to estimate fetal fraction, trained on the values obtained from Y-Chromosome count analysis. The parameter weights in the DNN are cross-validated with ordinary least-square regression to ensure robustness. PREFACE generally performs better than the traditional elastic net, achieving a Pearson's correlation of up to 0.940 (Raman et al. 2019).
The set of informative features used to establish a model is as important as the selection of an appropriate model, in order to avoid overfitting and circularity. Notably, SeqFF and PREFACE exclude windows located on Chromosomes 13, 18, and 21 from the model, as the copy number variation can also be used to estimate fetal DNA fraction (Yu et al. 2017). Because the training data set might include fetal aneuploidies, the model may wrongly predict that loci on Chromosomes 13, 18, and 21 are highly associated with fetal fraction (Raman et al. 2019). As SeqFF does not rely on sex chromosome reads like PREFACE, SeqFF also excludes windows on Chromosomes X and Y because of possible sex chromosome aneuploidies (Kim et al. 2015).
Although NIPT for fetal chromosomal aneuploidies boasts high sensitivity and specificity (Chiu et al. 2008, 2011), its performance in detecting fetal subchromosomal aberrations significantly diminishes. This reduction in robustness is owing to the decreased number of sequenced fragments in the affected genomic regions, which increases sampling variation and reduces the sensitivity of the z-score approach. ML is emerging as a potential method to attenuate this decreased statistical robustness by holistically analyzing aberrant signals. Notably, Dar and colleagues (2022a) constructed an ensemble of DNNs to learn the linkages between SNPs from 1.6 million maternal plasma sequencing samples, which was used for the prenatal screening of the 22q11.2 microdeletion at much lower coverage than classical read count-based approaches (Fig. 1). Beyond the more popular applications of NIPT to chromosomal aneuploidies, structural aberrations, and fetal monogenic diseases, ML could offer alternative pathways to the screening for other maternal complications, such as diagnosis of preeclampsia or prediction of miscarriage.
Genetic mutation–based cancer liquid biopsies
Early attempts to leverage ctDNA as a cancer biomarker were based on the detection of tumor-specific genetic mutations, reviewed elsewhere (Wan et al. 2017). Although genetic aberrations such as point mutations commonly occur in cancer genomes, the proportion of fragments that may harbor tumor-specific mutations is often low, typically in patients with early-stage tumors. Thus, it is challenging to differentiate true variants from overwhelming background noises that could have been introduced in library preparation and sequencing. Historically, studies sought to overcome this difficulty by using targeted deep sequencing of multiple loci in parallel (Forshew et al. 2012; Murtaza et al. 2013), but their efficacy may be limited by low variant allele frequency in the blood circulation, and also the wide heterogeneity of cancer genomes among different patients.
More recent attempts at cancer SNV detection (Newman et al. 2016; Chabon et al. 2020; Li et al. 2021b, 2023a; Christensen et al. 2023; Widman et al. 2024) implement ML algorithms to distinguish true cancer-associated variants from preanalytical or analytical errors. In particular, cfSNV (Li et al. 2021b, 2023a) and MRD-EDGESNV (Widman et al. 2024) demonstrate robust tumor mutation detection without the need for deep tumor tissue sequencing. However, cfSNV requires matched white blood cell sequencing data to remove nontumor clonal hematopoietic mutations from the analysis. MRD-EDGESNV uses a CNN to analyze SNVs in their sequence context and uses a multilayer perceptron framework to integrate other fragmentomic features such as size and chromatin accessibility. When applied to the detection of melanoma, a cancer well known to involve specific mutational signatures (Brash 2015; Alexandrov et al. 2020), MRD-EDGESNV achieves an AUC of 0.94.
In contrast to somatic mutations, methylomic and fragmentomic alterations can span millions of genomic coordinates, and thus, these perturbations may be more readily detected even at shallow-depth sequencing. Methylomics and fragmentomics also encode tissue-specific information, enabling diseases to be localized to their tissue of origin. Below, we discuss some exemplary studies that use classical ML- or AI-based technologies to perform cancer liquid biopsies, as well as highlight the importance of appropriate marker selection.
Methylation-based cancer liquid biopsies
The tissue of origin of cfDNA is encoded in their biological properties, offering many opportunities for developing tissue-specific diagnostic tools for cancer. These properties include methylation patterns (Lun et al. 2013; Sun et al. 2015; Moss et al. 2018), fragmentomics (Chan et al. 2004; Lo et al. 2010; Yu et al. 2014; Jiang et al. 2015, 2018, 2020b; Chan et al. 2016), and histone modifications (Gezer et al. 2015; Sadeh et al. 2021; Fedyuk et al. 2023). With the abundance of available sequencing data, many attempts have used classical ML algorithms such as SVMs and decision trees to leverage these properties for cancer detection. In the 2020s, deep learning is becoming increasingly exploited in this area, supported by large-scale clinical studies.
Decoding tissue-of-origin information in cfDNA methylation patterns
Sun and colleagues (2015) demonstrated that the methylation profile of plasma DNA could be deconvoluted into methylation profiles of various tissues linearly weighted by their contributions, thus allowing for the deduction of proportional contributions of various tissues into the plasma DNA pool, referred to as plasma DNA tissue mapping. This approach made use of 5820 tissue-associated methylation markers from 14 tissues including the liver, lungs, esophagus, heart, pancreas, colon, small intestines, adipose tissues, adrenal glands, brain, T cells, B cells, and neutrophils. These markers were selected because they were either (1) specific to one particular tissue (type I) or (2) highly variable among all tissues analyzed (type II). For the final model, 1013 type I markers and 4807 type II markers were selected (Sun et al. 2015). The methylation level of such a marker in the plasma is theoretically equal to the sum of tissue-specific methylation weighted by the tissue percentage contributions. Thus, a system of simultaneous equations can be constructed, one for each marker, and quadratic programming (Van den Meersche et al. 2009) was used to obtain the proportional contributions from different tissues. Quadratic programming is an unsupervised learning algorithm that iteratively finds the vertex of a quadratic objective function without the requirement of prior training. In plasma DNA tissue mapping, the proportional contributions from different tissues are estimated in a way that minimizes the quadratic cost function. The validity of the plasma DNA tissue mapping was supported by the agreement between the placental contribution and fetal DNA fraction (Pearson's r = 0.99) in pregnant women, as well as the high correlation between the liver contribution and donor liver DNA fraction in plasma of patients with liver transplantation (Pearson's r = 0.99), using gold-standard SNP-based approaches as previously described (Lo et al. 2010; Zheng et al. 2012). Plasma DNA tissue mapping also revealed that the organs suffering from cancer generally shed more DNA into plasma: For example, patients with HCC had higher liver contribution than those without. More importantly, by analyzing cfDNA molecules originating from regions with copy number variants, the anatomical site affected by the malignancy could be pinpointed. This principle for plasma DNA tissue mapping has been further extended by many other studies (Kang et al. 2017; Moss et al. 2018; Sun et al. 2022). As tissues usually have some heterogeneity in cell type, cell-type resolution of methylation patterns (Loyfer et al. 2023) would further enhance the resolution and accuracy of plasma DNA tissue deconvolution. For example, Loyfer and colleagues (2023) demonstrated the ability to differentiate the contributions of megakaryocytes and erythrocytes (i.e., 31% and 5%, respectively), even though they are derived from common progenitors.
Plasma DNA tissue mapping identifies that neutrophils, lymphocytes, and the liver (and, in pregnant women, the placenta) are the main contributors to plasma cfDNA. Using high-resolution methylation atlases, cfDNA of megakaryocyte origin has also been identified (Moss et al. 2023). However, to further extend the resolution for plasma DNA tissue mapping, a number of algorithms have recently been developed that are based on deep learning. Li and colleagues (2023b) developed cfSort for tissue deconvolution of cfDNA. Similar to the plasma DNA tissue mapping described previously (Sun et al. 2015), methylation markers were selected for training the deep learning model. In addition to the type I markers as defined previously (markers specific to one tissue), the authors also selected markers that show differential methylation between two tissue groups defined by developmental phylogeny, for example, the digestive system and lymphatic system (here defined as type II), and markers that show differential methylation between two tissue types, which could help distinguish similar tissue types from adjacent organs, such as the esophagus and stomach (type III). A total of 51,035 markers were identified (3775 type I markers, 6660 type II markers, and 40,600 type III markers), which were grouped using k-means clustering to merge individual tissue markers into 10,183 marker clusters. For every marker cluster, the fraction of tissue-specific DNA fragments at all markers within the cluster was calculated, which was used as the input vector for two DNNs with three dense hidden layers each. To avoid model overfitting, a batch normalization layer was used before each dense layer, followed by a dropout layer that prunes relatively unimportant nodes from the model. The predicted fractional tissue contributions were determined by averaging the predictions from the two DNNs. cfSort was reported to potentially outperform existing methods in terms of accuracy and detection limit.
cfDNA methylation–based cancer detection, localization, and staging
DNA methylation at the cellular level is cell type specific (Loyfer et al. 2023) and tumor specific (Liang et al. 2023). Thus, it is theoretically possible to infer the tissue of origin of ctDNA and the type of cancer. Indeed, Sun and colleagues (2015) had demonstrated the feasibility of tracing the tumor origin on the basis of plasma DNA methylation patterns. Briefly, this method leverages genomic regions that exhibit copy number variants in cancer. The prevalence of tissue-specific methylation markers in these genomic regions would theoretically show the largest deviation from normal (ΔMtissue) in cfDNA released from the tumor tissue of origin. ΔMtissue was able to pinpoint the tumor tissue of origin in both HCC and lymphoma patients. Subsequently, a number of studies have leveraged classical ML (Guo et al. 2017; Xu et al. 2017; Li et al. 2018; Shen et al. 2018; Liu et al. 2020; Liang et al. 2021; Stackpole et al. 2022; Gao et al. 2023) and deep learning (Peneder et al. 2021; Li et al. 2021a; Abbosh et al. 2023) for cancer detection, localization, staging, and prognosis based on cfDNA methylation information.
Marker selection prior to the main learning task was approached diligently. For example, Xu and colleagues (2017) implemented a pipeline that narrowed down 485,000 CpGs from The Cancer Genome Atlas (TCGA) and Gene Expression Omnibus (GEO) to only 10 markers in the two final learning tasks for HCC detection. First, the 1000 CpGs that showed the most significantly different methylation rates between HCC and healthy control plasma were selected using a moderated t-test. Out of these 1000, 401 markers were validated using targeted BS-seq in 28 paired HCC tissue DNA and plasma cfDNA samples. These 401 markers were further filtered using random forest (RF) (Breiman 2001) and LASSO independently. RF constructs decision trees on bootstraps of the training data and averages the results from all trees. Combining multiple decisions often increases the robustness of the model (Dietterich 2000). Many authors propose that RF is inherently resistant to overfitting from a mathematical perspective, as increasing the number of trees decreases the model variance but does not lead to overfitting (Hastie et al. 2009; Biau and Scornet 2016; Barreñada et al. 2024). However, RF can overfit if the trees are grown too deeply (Barreñada et al. 2024). RF and LASSO identified 24 and 30 markers, respectively, in which 10 markers were identified by both algorithms. Finally, these 10 markers served as the input variables for the main classification task, which was performed robustly by logistic regression (AUC = 0.944 on validation) and unsupervised hierarchical clustering.
Liang and colleagues (2021) developed a deep methylation sequencing approach (ELSA-seq) that identifies methylation patterns at high resolution and implemented a ML classifier to distinguish lung cancer patients from sex-matched healthy controls. The authors took a different approach to that of Xu and colleagues regarding marker selection, in that they defined methylation “blocks” in which the methylation status of the CpGs was similar and closely linked. From 80,672 raw CpGs taken from TCGA and GEO, the authors defined 8312 methylation blocks. The authors argued that in silico binning of CpGs protects against sampling variance and technical noise, which would be more significant on individual CpGs. Then, a subset of 2473 blocks that were most informative for lung cancer were selected for the final classification task, which was done using a soft-margin SVM (Fig. 1). An SVM is a classical supervised learning algorithm that classifies data points by learning the boundary that separates the classes. This boundary is called the maximum-margin hyperplane, as it maximizes the distance between itself and the nearest point from two classes. In high-dimensional space, classes are often not linearly separable, so sometimes a “soft margin” is implemented to allow for a few anomalous misclassified points with a certain penalty, reducing the risk of overfitting on noisy data. The SVM achieves an AUC of 0.93 and 0.90 on the training/validation and single-blind test sets, respectively.
The first commercially available pan-cancer detection assay was developed by Liu and colleagues (2020), who systematically assessed the performance of methylation pattern–based detection and localization of 12 cancer types across all four stages, using data from the Circulating Cell-free Genome Atlas (CCGA). A total of 15,254 plasma DNA samples with (n = 8584; 56%) and without (n = 6670; 44%) cancer was collected from 142 sites in North America in the CCGA. The authors first identified genomic regions that were most likely to contain cancer- or tissue-specific methylation patterns. Then, after bisulfite treatment of the plasma DNA samples, cfDNA fragments in these regions were enriched using biotinylated probes, and a panel of 1,116,720 CpGs was then selected from the probes. After assembly in silico into <1 kb contiguous regions, a Bernoulli mixture model was trained using maximum likelihood to compute the probability that the fragments originated from specific source populations (i.e., individuals with cancer originating from a particular tissue). Each region was then ranked by its ability to differentiate between cancer types or from noncancer, and the top 256 regions for each cancer type were selected for the final analysis. On this final panel, a binomial logistic regression model was trained to differentiate cancer and noncancer signals, whereas a multinomial logistic regression model was trained to classify the tissue source of cancer. This ensemble achieved an overall specificity of 99.3%, a sensitivity of 67.3% for stage I–III cancers, and an accuracy of 93% in the tissue-of-origin analysis, outperforming classical pan-cancer detection approaches such as WGS and targeted mutation panels.
Several studies (Peneder et al. 2021; Li et al. 2021a; Jamshidi et al. 2022) highlight the potential of deep learning in noninvasive cancer detection across a variety of modalities, particularly because of their high flexibility of model structure, and the value of deep learning in cfDNA methylation-based cancer detection has been increasingly recognized. An example of this is DISMIR, a deep learning–based HCC classifier that integrates methylation and surrounding sequence information using convolutional and recurrent architectures (Li et al. 2021a). First, the most informative HCC-specific differentially methylated regions referred to as “switching regions” were identified, which showed above-threshold hypomethylation compared with the background methylation rate around that locus. Each “switching region” was encoded as a matrix upon which a convolutional layer was applied. Then, a recurrent layer (bidirectional long short-term memory) captures the sequential information in both forward and backward directions, followed by another 1D convolution. Finally, a DNN was applied to ultimately generate a continuous score that parameterizes the probability that the read is from a cancer tissue. DISMIR achieves an AUC of 0.99 for distinguishing HCC from healthy controls and is much more resistant to low sequencing depth (AUC = 0.91 at 0.01–0.1×) than a previous classical ML-based method by the same authors (AUC = 0.74) (Li et al. 2018). However, multicenter large-scale clinical trials across different cancer types are still necessary to address the actual benefit of using deep learning algorithms with a large number of parameters, compared with the conventional ML methods with less parameters.
Fragmentomics
An emerging paradigm in cfDNA-based diagnostics is the usage of cfDNA fragmentomics, which contain a wealth of information about physiological and pathological conditions. There are many levels to fragmentomics, including cfDNA fragment size (Chan et al. 2004; Lo et al. 2010; Jiang et al. 2015; Underhill et al. 2016; Mouliere et al. 2018; Kwon et al. 2023; Yu et al. 2023b), nucleosome footprints (Snyder et al. 2016; Sun et al. 2019; Yang et al. 2021; Jacob et al. 2024), fragment end motifs (Jiang et al. 2020a; Zhou et al. 2022, 2023), preferred ends (Jiang et al. 2018), and jagged ends (Jiang et al. 2020b; Ding et al. 2022). The richness of the fragmentomic landscape has spurred the development of ML algorithms to leverage fragmentomics in cancer liquid biopsies. Below, we discuss some recent advances in fragmentomics that rely on ML.
Size profiles
Perturbations in the cfDNA size profile serve as biomarkers for the detection and monitoring of cancer. However, the overall size profile alone cannot easily distinguish cancer from healthy controls (van der Vaart et al. 2009), and so, enrichment and isolation of the tumor-derived signal are needed. By focusing on chromosome arms that exhibited copy number aberrations in HCC, Jiang and colleagues (2015) discovered that plasma DNA of patients with HCC had aberrant size profiles depending on the tumor-derived DNA fraction and demonstrated that the tumoral cfDNA is shorter than the background cfDNA, which is mainly of hematopoietic origin. Based on this, Moulière and colleagues (2018) found that enriching fragments between 90 and 150 bp improved ctDNA detection and that the proportions of certain size ranges could be used to detect cancer using RF. As a corollary, the size profile across the genome would be dependent on the copy number aberrations present in the tumor cells and on tissue-specific differences in genomic chromatin architecture. This is a supporting biological basis of the DELFI approach (Cristiano et al. 2019), which considers local size profile information in 5 Mb windows across the entire genome. In each window, the ratio of short (100–150 bp) to long (151–200 bp) cfDNA fragments and overall sequencing coverage were used to construct the features to train a gradient boosting algorithm (Fig. 1). Gradient boosting sequentially builds a multitude of weak learners, in which each one is trained to minimize the loss function of the previous model using gradient descent. DELFI had sensitivities of detection ranging from 57% to >99% among seven cancer types at 98% specificity, with an overall AUC of 0.94. Combining DELFI with mutation detection in cfDNA raised the sensitivity to 91% while still at 98% specificity. At a threshold of 95% specificity, 79% of patients with stage I–III cancers could be detected. Moreover, the tissue of origin of the tumor could be identified in 61% of cases. Recently, DELFI has also been applied to diagnose, classify, and predict the prognosis of lung (Mathios et al. 2021) and liver (Foda et al. 2023) cancers.
End motifs
Mechanistically, an aspect of the biology that underpins fragmentomics is likely to be the action of nucleases (Han and Lo 2021). Mammalian DNA nucleases are unlike bacterial restriction enzymes (REs): Although RE cutting sites are strictly defined, it is believed that these nucleases exhibit a certain level of preference in the cutting signatures, which can manifest as preferentially generated base sequences at the 5′ ends of cfDNA fragments. However, with increasing resolution, that is, the inclusion of more bases in the end motif, the search space increases exponentially (for a k-mer, there would be 4k end motifs). Earlier work focused on isolating the motifs whose abundances experienced the most significant changes when nuclease activity was perturbed artificially (Serpas et al. 2019; Han et al. 2020) or in pathology (Jiang et al. 2020a). However, only choosing a few specific motifs out of the 256 possible 4-mers would not completely reflect the variety of end motifs that nucleases can generate. Jiang and colleagues (2020a) trained an SVM for distinguishing patients with and without HCC, taking into account all 256 4-mer end motifs, with an AUC of 0.89. This is an improvement on a classifier using the motif diversity score, which parameterizes the diversity of end motifs found in cfDNA fragments. As perturbations in the end motif profile may reflect pathological changes in nuclease action, this is potentially generalizable to a wide range of cancers. For example, one of the major players governing cfDNA fragmentation is DNASE1L3, which is downregulated in many cancers such as colorectal cancer, lung cancer, nasopharyngeal carcinoma, and head and neck squamous cell carcinoma (Jiang et al. 2020a), providing a biological basis for end motif–based pan-cancer detection.
Zhou and colleagues (2023) used NMF to deconvolute the high-dimensional end motif profile, mathematically deriving six distinct types of cfDNA cleavage patterns, referred to as “founder” end motif profiles (F-profiles) (Fig. 1). NMF is an unsupervised clustering algorithm that approximates a data matrix as the product of (usually) two source matrices (Lee and Seung 1999). Training the algorithm with murine cfDNA samples from different nuclease-knockout mice yielded three F-profiles that were linked to DNASE1L3, DNASE1, and DFFB, and three F-profiles that have not been assigned yet. Interestingly, F-profile VI shows no obvious sequence preference among the 256 4-mer motifs but is able to robustly differentiate HCC patients and HBV carriers (AUC = 0.97), and thus, the authors speculated that it may be related to oxidative stress. The percentage contribution of F-profile I, corresponding to DNASE1L3 action, could inform pathological states such as familial SLE (AUC = 0.97) and HCC (AUC = 0.89), as familial SLE is linked to genetic DNASE1L3 deficiency and HCC with DNASE1L3 downregulation. In summary, NMF can be used for generating testable hypotheses that could yield further insight into the mechanisms of cfDNA fragmentation. However, more work needs to be done to reveal and characterize the biological mechanisms behind the remaining putative components. In particular, the training data used by Zhou and colleagues (2023) only included knockouts of DNASE1L3, DNASE1, and DFFB, but there may be other DNA nucleases at play that need to be investigated further. It remains to be seen whether incorporating more nuclease knockout models into the analysis will reveal novel components of the end motif profile. Interestingly, NMF was also used in a proof-of-concept study to infer the ctDNA size profile and derive cancer-specific and chromatin state–specific size signatures, achieving early detection of various cancers (Renaud et al. 2022).
Hidden fragmentomic signals in repeat elements
Based on the knowledge that tumor-derived cfDNA exhibits changes in methylation and fragmentation patterns (Lo et al. 2021), Douville and colleagues (2024) hypothesized that the representation of specific Alu elements might be different in plasma DNA of patients with cancer compared with healthy controls. The abundance of Alu in the human genome lends itself well to ML-based analyses, for which the authors developed a method called Alu profile learning using sequencing (A-PLUS) (Douville et al. 2024). A-PLUS employed a single primer pair to amplify approximately 350,000 Alu elements across the genome. After discarding the elements that were unstable or had insufficient coverage, dimensionality reduction was performed on the remainder using PCA, and the top 60 principal components were selected for the final panel. An SVM was then trained on the 60-marker panel using 7615 samples from 5178 individuals, among which 2073 were solid cancers, obtaining a sensitivity of 40.5% across 11 different cancer types at a specificity of 98.5%. Although it is well known that cancer genomes often exhibit copy number aberrations (Shlien and Malkin 2009; Yi and Ju 2018), A-PLUS could detect 41% of the cancer samples that were not detected by either copy number aberrations or common protein biomarkers (e.g., CA135, AFP, CA15-3); combining A-PLUS with copy number aberrations and eight common protein biomarkers detected 51% of the cancers at a specificity of 98.9%. The authors found that the power of A-PLUS could be partly attributed to the global reduction of AluS subfamily elements in plasma DNA with solid cancers. In a similar vein, another group also demonstrated the application of ML to the analysis of de novo k-mers within 1280 repeat elements for predicting disease in patients with early-stage lung or liver cancer (Annapragada et al. 2024). These recent findings suggest that repeat elements contain novel fragmentomic signals in addition to copy number aberrations and so have the potential to improve existing copy number–based and fragmentomic-based models with their integration.
Fragmentomic-based inference of methylomic and transcriptomic signals
With an improved understanding of the biological systems implicated in the cfDNA landscape, it would be greatly informative to consider the links between cfDNA fragmentomics and the underlying methylome and transcriptome. As methylation and gene expression patterns can be tissue and tumor specific, a single fragmentomic assay could have the potential to offer disease detection and tissue-of-origin analysis based on cfDNA sequencing, without having to resort to complicated or low-yield experimental protocols such as BS-seq or RNA sequencing. Indeed, cfDNA fragmentation has been revealed to be closely linked to DNA methylation (Zhou et al. 2022) and gene expression (Ulz et al. 2016; Esfahani et al. 2022), opening possibilities for new diagnostic approaches.
Zhou and colleagues (2022) developed fragmentomic-based methylation analysis (FRAGMA) based on the realization that fragmentation around a CpG site depends on its methylation status, with twofold higher cleavage at methylated cytosine (5mC) than its unmethylated counterpart. In other words, CpG methylation would elevate the “CGN/NCG ratio” observed at that CpG. This would allow the determination of the methylome from cfDNA sequencing data alone without the need for bisulfite treatment (which is destructive) or currently expensive single-molecule sequencing. In one implementation of FRAGMA, a CNN was implemented to integrate fragmentation information across five consecutive nucleotides on either side of the CpG cytosine for classification of CpG methylation status (Fig. 1). The CNN was trained on cfDNA cleavage patterns associated with a number of hypermethylated and hypomethylated CpG sites, achieving an AUC of 0.93 for differentiation between methylated and unmethylated cytosines. The authors also successfully used CGN/NCG ratios across all eight CG-containing motifs to train an SVM to distinguish HCC from non-HCC individuals at a specificity of 96% (AUC = 0.98).
Based on this knowledge, there has also been a recent effort to predict CpG methylation from shallow-depth cfDNA WGS using a hidden Markov model (HMM), which the authors called FinaleMe (Liu et al. 2024b). HMMs model a chain of observable probabilistic processes that depend on “hidden” internal factors: In this case, the observations are the fragment lengths, normalized coverage, and the position of the CpG in the fragment. FinaleMe assumed that the CpG methylation status was a multivariate Gaussian distribution of these three fragmentomic features. Then, the key training step in an HMM was to determine the transition and emission probabilities. In FinaleMe, the emission probabilities for the three fragmentomic features were learned (i.e., the likelihood of making such an observation given an underlying methylation state), whereas the transition probabilities were precalculated based on the distance between each pair of adjacent CpG sites. Finally, the authors used the Viterbi algorithm (Viterbi 1967; Forney 1973) to estimate the methylation status of each CpG with an AUC of 0.91 for CpGs at fragments with five or more CpGs.
In addition to the deduction of DNA methylation signals, transcriptomic analysis from cfDNA fragmentomics is being actively pursued. Theoretically, transcriptionally active promoters would be less protected by nucleosomes, which would result in a more random cleavage pattern than that of inactive promoters. Based on this hypothesis, Esfahani and colleagues (2022) developed an approach, named epigenetic expression inference from cell-free DNA sequencing (EPIC-seq), that inferred RNA expression from the cfDNA fragmentation profile around the transcriptional start site (TSS). To estimate the RNA expression, the authors performed deep sequencing of TSS-flanking regions in cfDNA to obtain the diversity of fragment sizes, parameterized as promoter fragmentation entropy (PFE), which was then used to estimate gene expression using an ensemble of linear models. These estimated expression levels were used to train an elastic net logistic regression model for non-small-cell lung cancer (NSCLC) detection (AUC = 0.91) and subtype classification (AUC = 0.90). As expected, the genes with the largest coefficients included canonical markers for lung adenocarcinoma and squamous cell carcinoma, highlighting the importance of biological validation of conclusions drawn from ML.
Although these recent approaches hold significant promise, their true sensitivity, specificity, and clinical value are required to be further confirmed through extensive multicenter trials. Data gathered from these large-scale trials would open up exciting possibilities for exploring more complex AI-based models for healthcare. These more sophisticated models, like transformer-based LLMs, often require huge sample sizes to achieve their full potential. The interplay between methylation- and transcription-associated cfDNA fragmentation features, sample sizes, and model complexity may shape the future dynamic landscape of AI-based noninvasive diagnostics. It is worth noting that although the review has presented various methodologies, there remains a significant gap in direct comparative analysis between these approaches. Such comparisons are essential to accurately assess the true efficacy and potential collaborative benefits of these technologies.
Common pitfalls
The amount of cfDNA sequencing data, coupled with the accessibility of ML toolkits, has driven the increasingly popular application of various ML algorithms to cfDNA analyses. However, an awareness of the possible pitfalls in pipeline design is paramount in ensuring that the model will be robust on unseen data or yield any reliable mechanistic insight. Common pitfalls general to ML in genomics have been reviewed elsewhere (Whalen et al. 2022). Here we discuss two pitfalls that may be particularly pertinent in the field of cfDNA-based diagnostics and highlight examples of previous research that addresses them.
Confounding effects
Confounders are unmeasured variables that induce dependence between predictor variables and output. If confounding effects are not accounted for, the biological interpretations of the learned predictor–output relationships may be invalid, and the model may perform poorly when the confounder is eliminated or distributed differently. A classic example of a confounder is ancestry in genetic association studies (Kittles and Weiss 2003; Tang et al. 2005; Sohail et al. 2019). Confounding effects introduce bias in the training data, and it is well known that ML classifiers can be prone to amplifying these inherent biases (Zhao et al. 2017; Hall et al. 2022).
In the context of cfDNA-based diagnostics, batch effects resulting from preanalytical or analytical factors may be a pervasive source of confounders. It has been shown that plasma cfDNA end motifs obtained from different processing centers using the same preparation protocol may cluster separately (van der Pol et al. 2022). Physiological variables such as gender and BMI may also be associated with differences in cfDNA parameters. In particular, increased maternal BMI was shown to be associated with low fetal fraction in multiple large-scale clinical studies (Wang et al. 2013; Hou et al. 2019; Pan et al. 2024). Furthermore, environmental factors influencing physiological behavior may also have measurable effects. For example, it was previously identified that lower ambient temperatures of blood collection were independently associated with increased plasma EBV DNA, which the authors attributed to impairment of the immune response allowing transient viral replication in cold temperatures (Chan et al. 2018).
Methods of addressing batch effects, including study design considerations and quality-control analyses such as hierarchical clustering, are reviewed elsewhere (Leek et al. 2010). For example, Liang and colleagues (2021) explicitly address and minimize possible batch effects by recruiting independently from two hospitals and processing cancer and control samples together. It may also be important in the future to establish external validation controls for emerging areas of cfDNA biology such as fragmentomics (van der Pol et al. 2022).
Leakage
It may be ideal that a model is built only on the training data set, namely, without any dependence on the validation data set, to ensure that the testing phase is fair. Information “leakage” from the validation into the training set because of an unsound data preprocessing pipeline may cause spurious circular relationships between the independent and dependent variables (Pulini et al. 2019; Whalen et al. 2022; Kapoor and Narayanan 2023). Indeed, many authors have identified leakage as a major cause of overoptimism in ML-based predictions across many fields of science (Rocke et al. 2009; Pulini et al. 2019; Kapoor and Narayanan 2023). When leakage is corrected for in these instances, the ML model may not even exhibit meaningful improvement over classical statistical models (Kapoor and Narayanan 2023). Dependency between samples may also contribute to leakage (Whalen et al. 2022), for which blocked cross-validation should be considered (Roberts et al. 2017; Yates et al. 2023).
Leakage is particularly relevant in cases in which feature selection must be performed: For example, selection of a panel of differentially methylated regions, from which an ML classifier is built. In particular, Whalen and colleagues (2022) warn against selecting such a methylation panel from the whole data set before cross-validation. Given that much work in cfDNA-based diagnostics involves extracting and selecting methylomic information for the final classification step, this consideration of leakage is particularly important. Liu and colleagues (2020) demonstrate commendable diligence in pipeline design: In particular, it was clear that the validation data set was not released until the final classifiers were trained and locked, and all analyses were double-blinded.
Future directions and concluding remarks
With an increasing variety of biomarkers available for disease detection, combining biomarkers into integrated multianalyte assays would theoretically increase the statistical power of the analysis, if overfitting is appropriately protected against. There have been a number of attempts that use AI or ML to combine multiple types of cfDNA features (Peneder et al. 2021; Siejka-Zielińska et al. 2021; Lee et al. 2022b; Bae et al. 2023; Bie et al. 2023; Nguyen et al. 2023; Pham et al. 2023; Li et al. 2024; Moldovan et al. 2024; Wong et al. 2024; Liu et al. 2024a) or integrate cfDNA and protein analysis (Cohen et al. 2018; Douville et al. 2024). New developments in multimodal AI (Baltrušaitis et al. 2019) are moving beyond biochemical analytes to imaging, histopathology (Chen et al. 2022b; Haque et al. 2023), and clinical data (Vale-Silva and Rohr 2021; Tong et al. 2022; Peng et al. 2023). Indeed, clinical data can even be collected and inferred from interactive conversations using LLM-based chatbots (Peng et al. 2023). We eagerly await this holistic approach to cfDNA-based diagnostics, especially with the rise of transformer architectures in AI (Vaswani et al. 2017), which can be the basis of a general model architecture for all modalities (Lu et al. 2021; Acosta et al. 2022). It must, however, be emphasized again that transformers require even larger amounts of data than classical deep learning algorithms for them to be a meaningful and robust improvement.
Improvements in our understanding of biological processes governing the cfDNA epigenetic and fragmentomic landscape, coupled with recent advancements in sequencing technologies, have given rise to a number of invaluable molecular features for liquid biopsies in oncology, pregnancy, organ transplantation, and immune diseases. ML and AI are powerful tools to leverage such features in high-dimensional space and produce robust predictions for diagnosis and prognosis. With the ever-expanding body of sequencing data available, researchers are increasingly exploring highly adaptable and multimodal AI frameworks for cfDNA-based diagnostics. These frameworks hold immense promise for enhancing our ability to detect various diseases at their early stages, making it possible to revolutionize precision medicine.
Competing interest statement
Y.M.D.L. holds equities in DRA, Take2, and Insighta. P.J. holds equities in Illumina. P.J. is a Director of DRA, KingMed Future, Take2, and Insighta. P.J. and Y.M.D.L. have filed a number of patents or patent applications related to liquid biopsies.
Acknowledgments
This study was supported by the Innovation and Technology Commission of the Hong Kong SAR Government (InnoHK initiative). Y.M.D.L. received an endowed chair from the Li Ka Shing Foundation.
Footnotes
-
Article and publication date are at https://www.genome.org/cgi/doi/10.1101/gr.278413.123.
-
Freely available online through the Genome Research Open Access option.
This article, published in Genome Research, is available under a Creative Commons License (Attribution-NonCommercial 4.0 International), as described at http://creativecommons.org/licenses/by-nc/4.0/.
References
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵








