

Simulated data and results. (A) Simulated data for 5 cell types generated using the process described in Methods with noise parameter set to 0.1 and 40
sampled time points. Nonuniform sampling of time points increases complexity. Dots represent data points for each of the 5
cell types. The orange line is the average learned DIISCO dynamics after fitting the data over 1000 samplings. The shaded
region shows 95% confidence intervals. No normalization was used. (B) Interactions inferred by DIISCO between the cell types are shown in (A). Ground truth W interactions are shown in dotted lines whereas DIISCO predictions are solid lines. Only dynamic interactions with W(t) > 0.1 in at least one time point t for either true W or learned W are shown. (C) Same as in A, except noise parameter set to 0.5. (D) Same as in B, except learned interactions for the noisier data set shown in (C). (E) Method robustness to number of time points: R2 calculated between inferred and ground truth W(t). Mean and SD across five iterations are shown. (F) Runtime for varying numbers of clusters and time points. (G) Table demonstrating DIISCO performance compared to linear model (LM) and rolling linear model (RLM) as described in Methods
for 40 time points. Metrics for different numbers of time points from 10 to 90 can be found in Supplemental Tables S1 and S2. Each model was tested over 10 iterations and mean and SD are shown for each metric across all iterations. Model acronyms
denote the following: (LM) linear model with prior, (LM_nop) linear model, (RLM) rolling linear model with prior, (RLM_nop)
rolling linear model. Model details can be found in Methods. Comparison metrics used are as follows:  ,
, 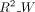 : R2 value comparing predictions to ground truth for dynamics (Y) or interactions (W). Higher is better.
: R2 value comparing predictions to ground truth for dynamics (Y) or interactions (W). Higher is better. 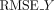 ,
, 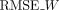 : Root mean squared error for dynamics (Y) or interactions (W). Lower is better. (AUC) area under ROC curve. Higher is better. (AUPRC) area under precision–recall curve. Higher is better.
F1: Max F1 score. Higher is better. AUC, AUPRC, and F1 scores were calculated by comparing predicted interactions to ground
truth interactions.
: Root mean squared error for dynamics (Y) or interactions (W). Lower is better. (AUC) area under ROC curve. Higher is better. (AUPRC) area under precision–recall curve. Higher is better.
F1: Max F1 score. Higher is better. AUC, AUPRC, and F1 scores were calculated by comparing predicted interactions to ground
truth interactions.








