

Figure 3.
Data points represent the slopes of the linear regressions in Figure 2 for extension, with the corresponding value of k (which is k = C log n for a constant 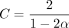 ). This dependence of the genome size, n (x-axis), is decently approximated by a naive A1log (n) + B1 fit, where A1 and B1 are parameters. However, our theory states that the dependence should be log (n)nCα with Cα ≈ 0.08 when θ = 0.05. Fitting A2log (n)n0.08 + B2 gives a better R2 value (0.928 vs. 0.766) with the same number of parameters (two parameters for both fits), indicating the goodness of our
theoretical predictions.
). This dependence of the genome size, n (x-axis), is decently approximated by a naive A1log (n) + B1 fit, where A1 and B1 are parameters. However, our theory states that the dependence should be log (n)nCα with Cα ≈ 0.08 when θ = 0.05. Fitting A2log (n)n0.08 + B2 gives a better R2 value (0.928 vs. 0.766) with the same number of parameters (two parameters for both fits), indicating the goodness of our
theoretical predictions.








