
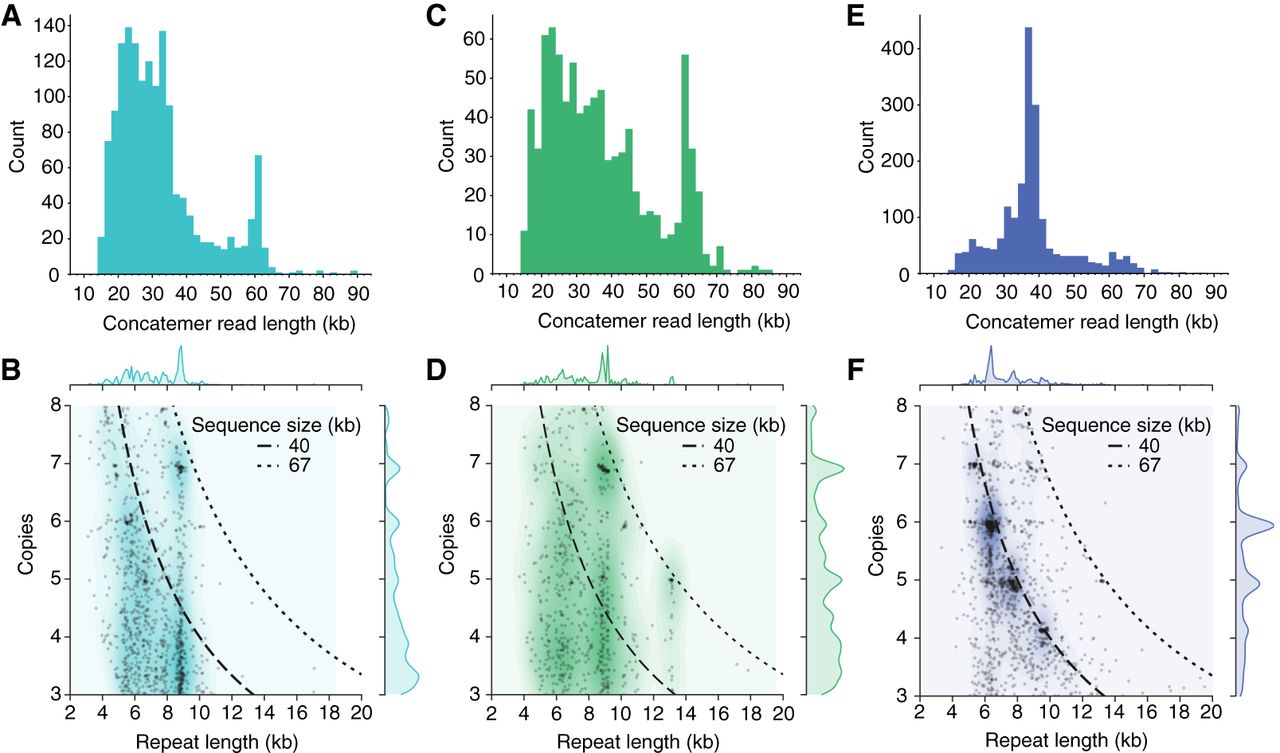
Read lengths and repeat counts in concatemeric nanopore reads. The length distribution of concatemeric nanopore reads is similar to the length distributions of polished AFVGs obtained from each sample (Supplemental Fig. S6). (A) Concatemeric reads obtained from the 25-m sample are predominately 20–40 kb with an additional enrichment for 60-kb reads. (B) In the 25-m sample, the length of the repeated unit in each concatemer and its associated repeat count. The repeat counts are enriched for whole integer values, primarily six and seven copies. Dashed lines indicate the sequence size associated with a given repeat unit count and length. (C) Concatemeric reads isolated from the 117-m sample show an enrichment in concatemer read lengths between 60 and 65 kb, which is similar in size to many of the complete phage genomes obtained from the 117-m sample. (D) The repeat unit counts are enriched at whole integer numbers, most prominently at five, six, or seven copies in the 117-m sample. Concatemers enriched for these counts in the 117-m sample are mostly associated with 60- to 65-kb concatemer reads. (E) Concatemer reads from the 250-m sample are predominantly between 35 and 40 kb in length. (F) The concatemer repeat unit counts in the 250-m sample are enriched at four, five, six, and seven whole copies. Given each specific combination of repeat unit count and length, the majority of concatemer reads remain just short of 40 kb.








