
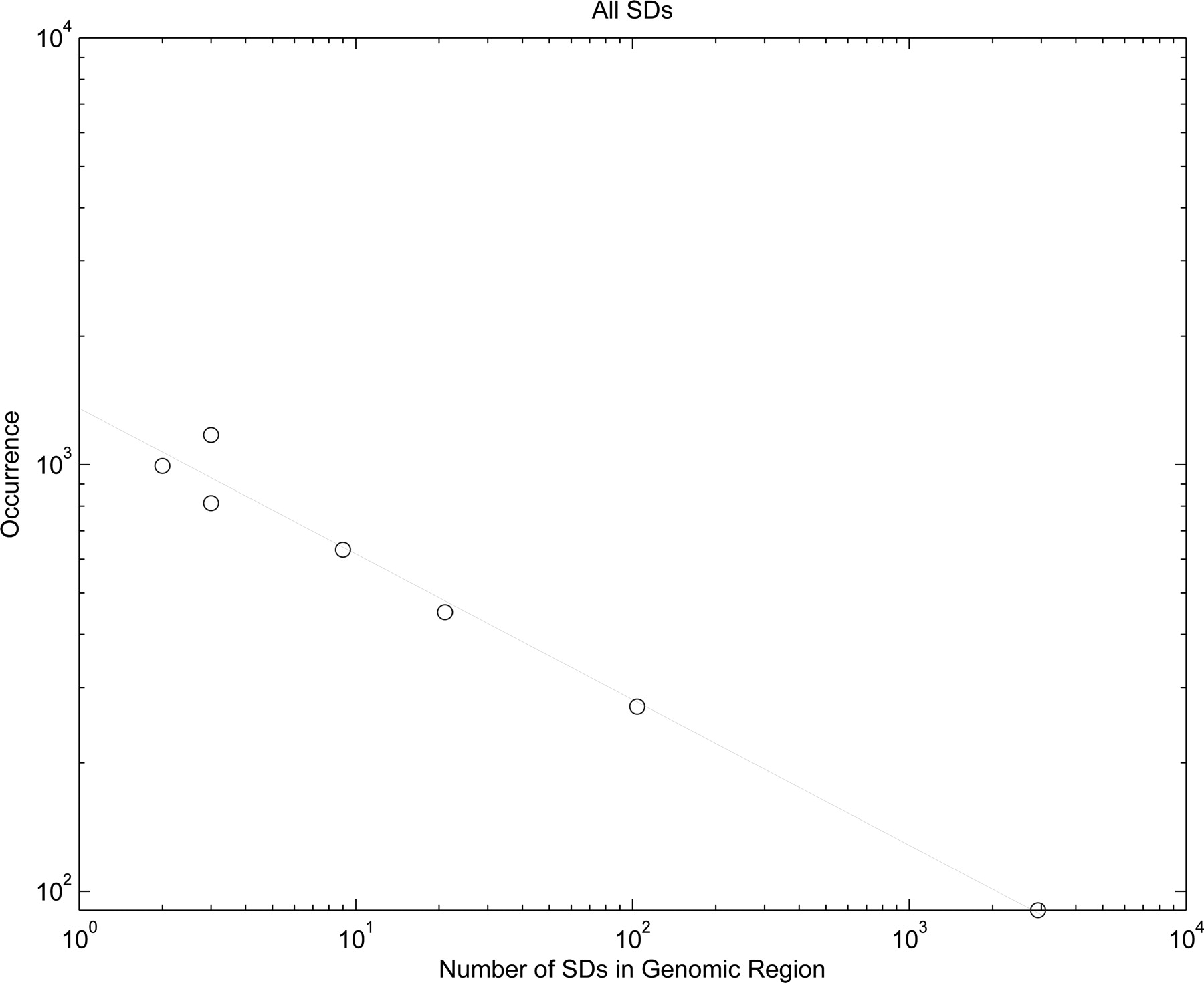
Figure 2.
Segmental duplications are distributed according to a power law in the human genome. As can be seen, segmental duplications follow a power-law distribution, that is, while most regions in the genome are relatively poor in SDs, there are a small number of regions with much higher SD occurrence [p(x) ∼ x−0.31]. This is indicative of a preferential attachment (“rich get richer”) mechanism.








