
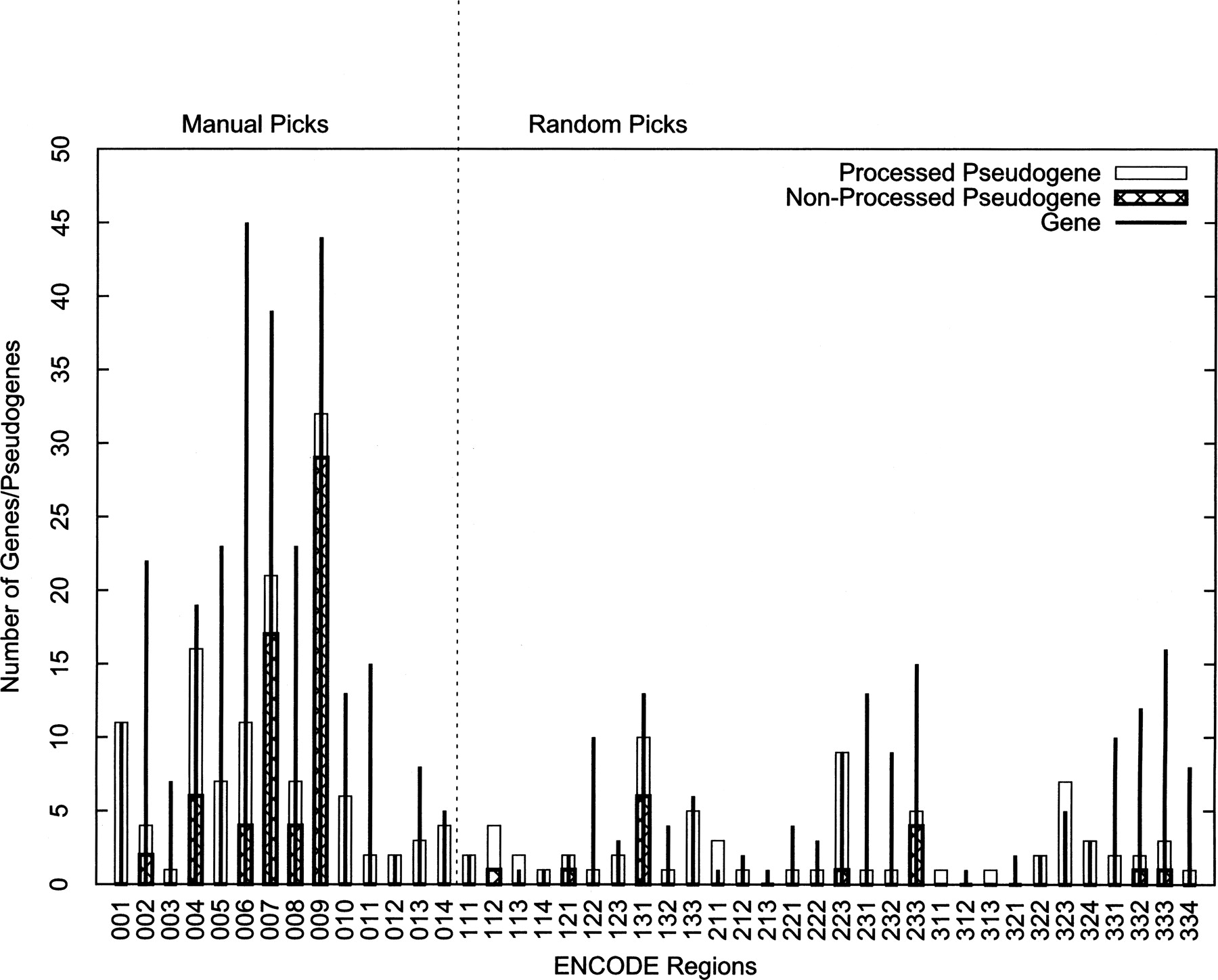
Figure 2.
The distribution of genes and the final 201 consensus pseudogenes within 44 ENCODE regions. Both genes and pseudogenes were concentrated in the manually picked regions (001–014).








