
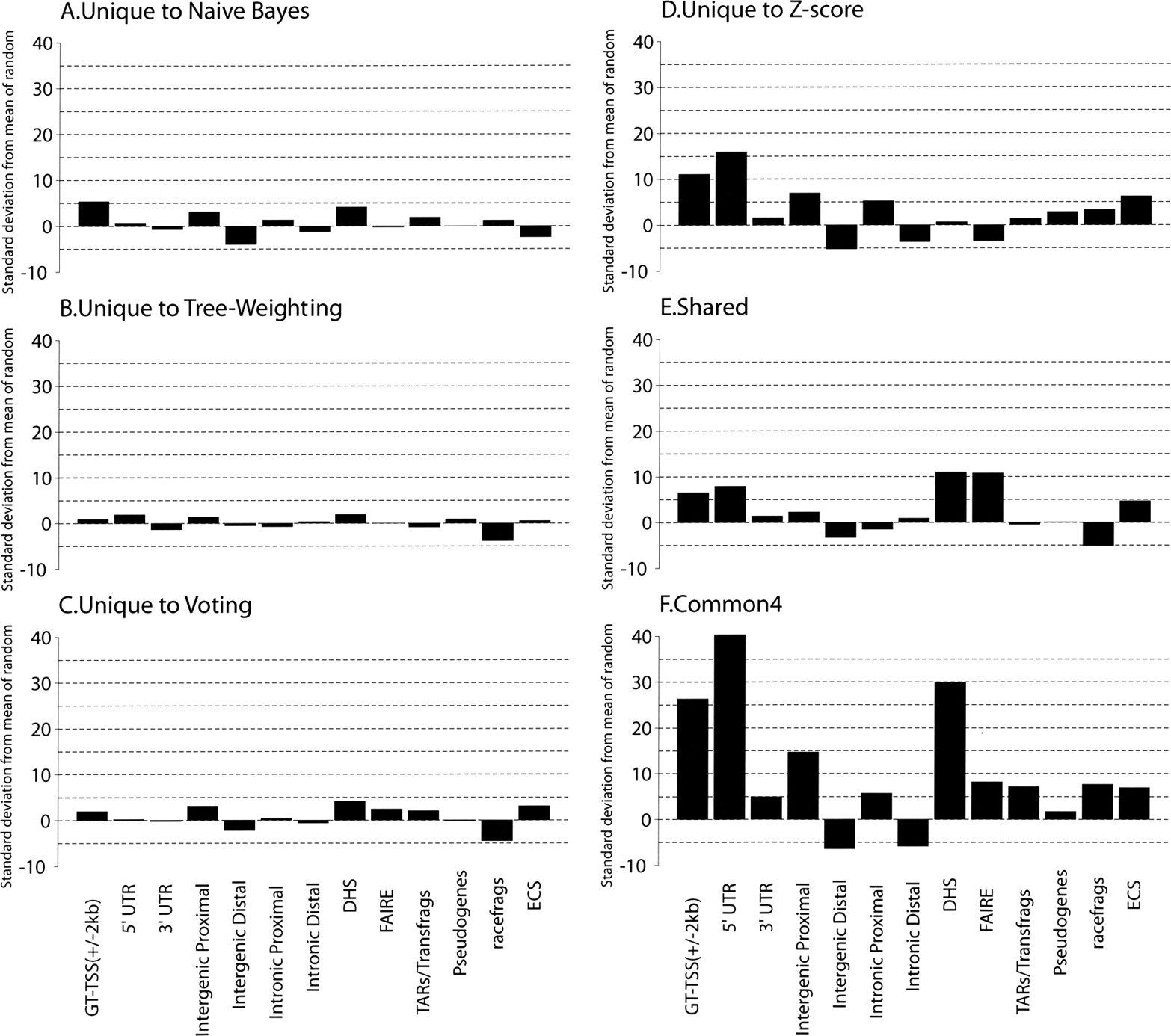
The significance of the overlap of predicted regions in different categories with various genomic features. See Methods for their definitions and origins, as well as details on randomization. The significance is given in terms of the number of standard deviations away from the mean number of overlaps between a set of predicted regions and a set of randomly placed, size-matched regions corresponding to the genomic features. (A) Regions unique to the naïve Bayes method. (B) Regions unique to the tree-weighting method. (C) Regions unique to the voting method. (D) Regions unique to the Z-score method. (E) Regions shared by two or three methods (Shared). (F) Regions supported by all the methods (Common4).








