
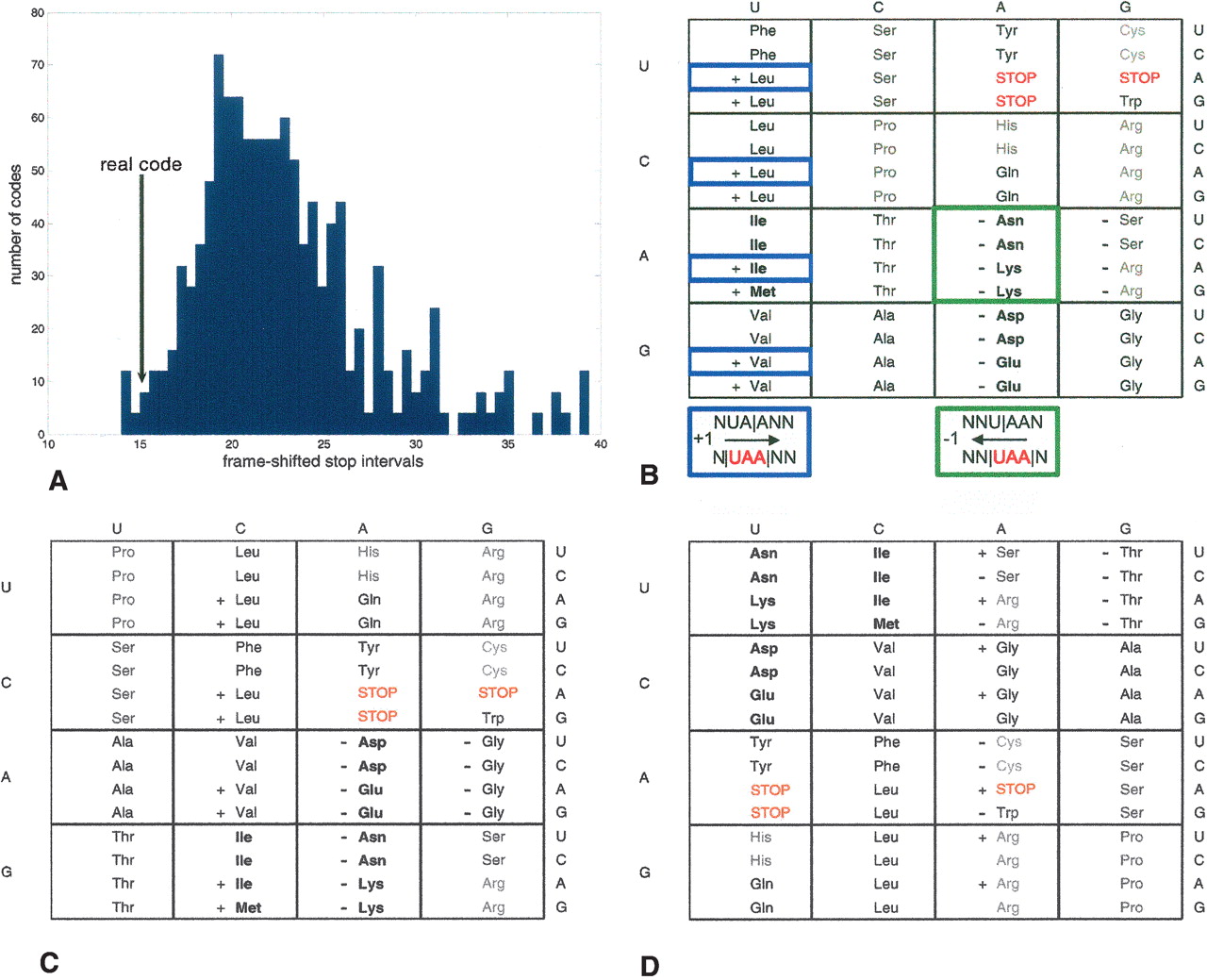
Optimality of the genetic code for minimizing the impact of frame-shift translation errors. (A) Distribution of average number of translated codons until a stop codon is encountered after a frame-shift event for the alternative genetic codes. This number corresponds to the mean length of the nonsense polypeptide translated after a frame-shift event, and is the inverse of the frame-shifted stop probability, averaged over the +1 and −1 frame-shifts. (B) In the real code, frame-shifted stop codons overlap with abundant codons. Codons with two-letter overlap with a stop codon are marked by + for a +1 frame-shift and – for a −1 frame-shift. Abundant codons are shown in heavier font. For example, the stop codon UAA, when frame shifted, results in codons such as AAN (green box), or NUA (blue boxes), which are relatively abundant. (C) The “best code,” which achieves the highest frame-shifted stop probability both in a +1 frame-shift and in a −1 frame shift. Stop codons are CAA, CAG, and CGA. In the “best code,” a stop codon has an overlap of two positions with codons of Glycine instead of codons of Serine and Arginine in the real code. (D) The “worst code” with the lowest frame-shifted stop probability. Stop codons are AUA, AUG, and AAA. Note that the stop codons overlap either with themselves (AAA) or with codons for nonabundant amino-acids (those with light font), in contrast to B and C.








