
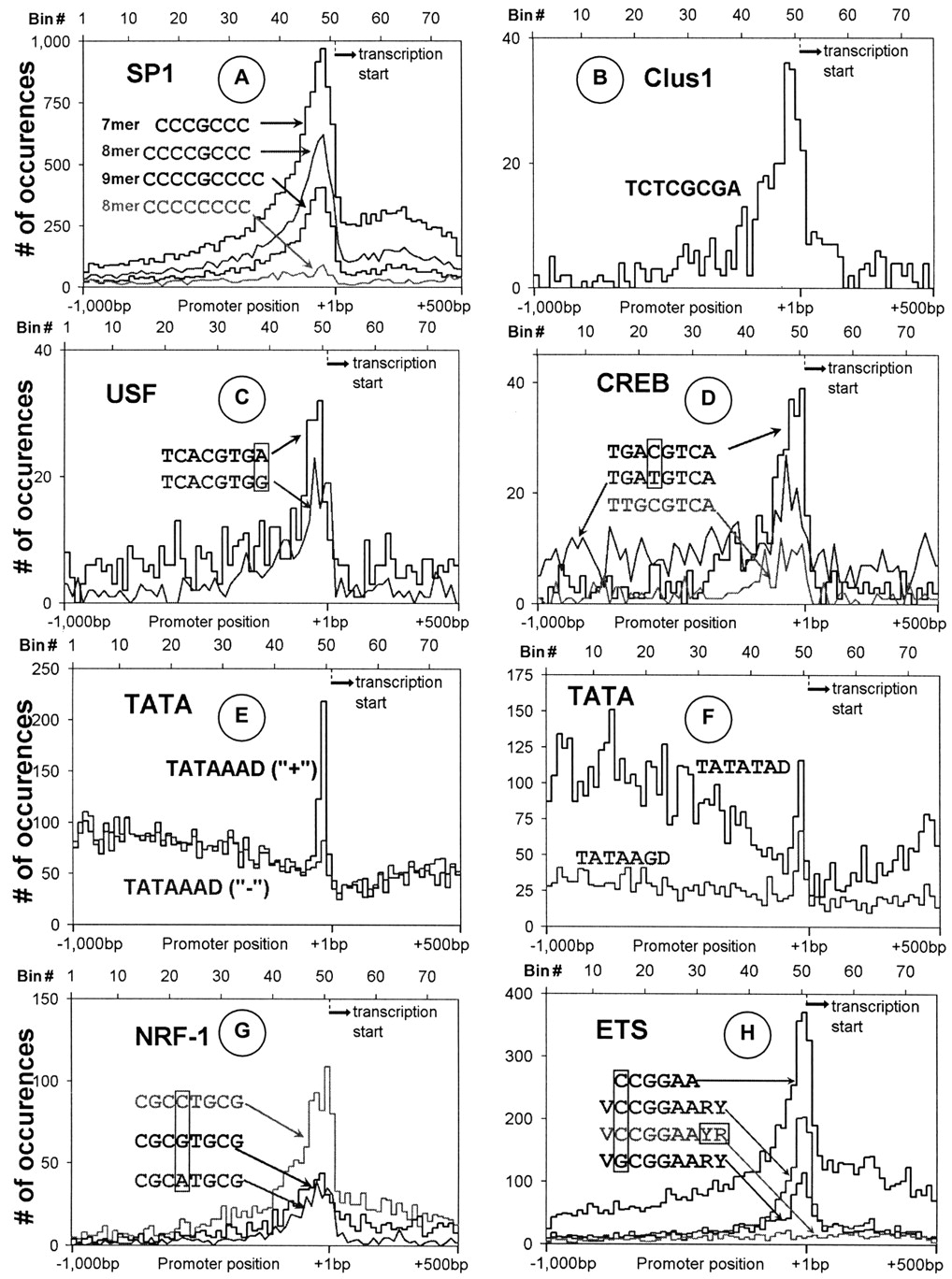
Figure 7
Distribution of selected sequences (8-mers and consensus patterns). (A) Three SP1 (CCCGCCC, CCCCGCCC, CCCCGCCCC) sequences and a nonpeaking single base variation (CCCCCCCC). (B) Clus1 (TCTCGCGA) sequence. (C) Two USF (TCACGTGG, TCACGTGA) sequences. (D) Three (TGACGTCA, TGATGTCA, TTGCGTCA) CREB like sequences. (E) Strand-specific localization of the TATAAAD sequence. (F) Two variants (TATATAD and TATAAGD) of TATA, plus strand (+) only. (G) Three NRF-1 (CGCCTGCG, CGCGTGCG, CGCATGCG) sequences. (H) ETS core (CCGGAA), consensus sequence (VCCGGAARY), and a peaking (VGCGGAARY) and nonpeaking VCCGGAAYR variant.








