
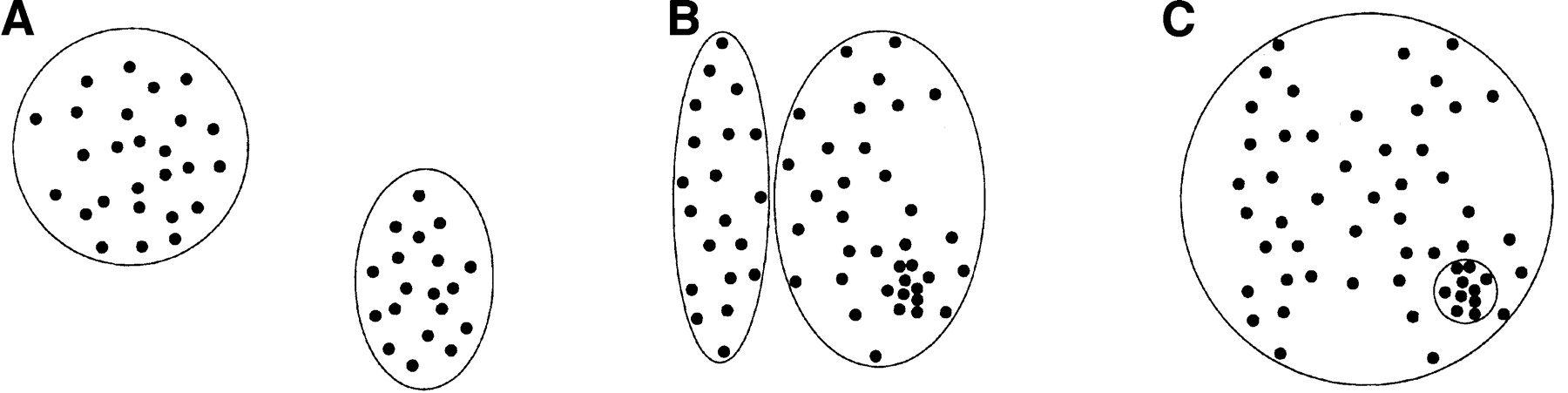
Figure 1.
Applicability of k-means clustering to different kinds of clustering problems. Disjoint clusters of similar size are easily identified (A). Small subfamilies nested inside large subfamilies, a typical scenario in Alu repeat subfamilies, are not easily identified, because there is a tendency to split off a larger cluster (B) instead of identifying the nested subfamily (C).








