
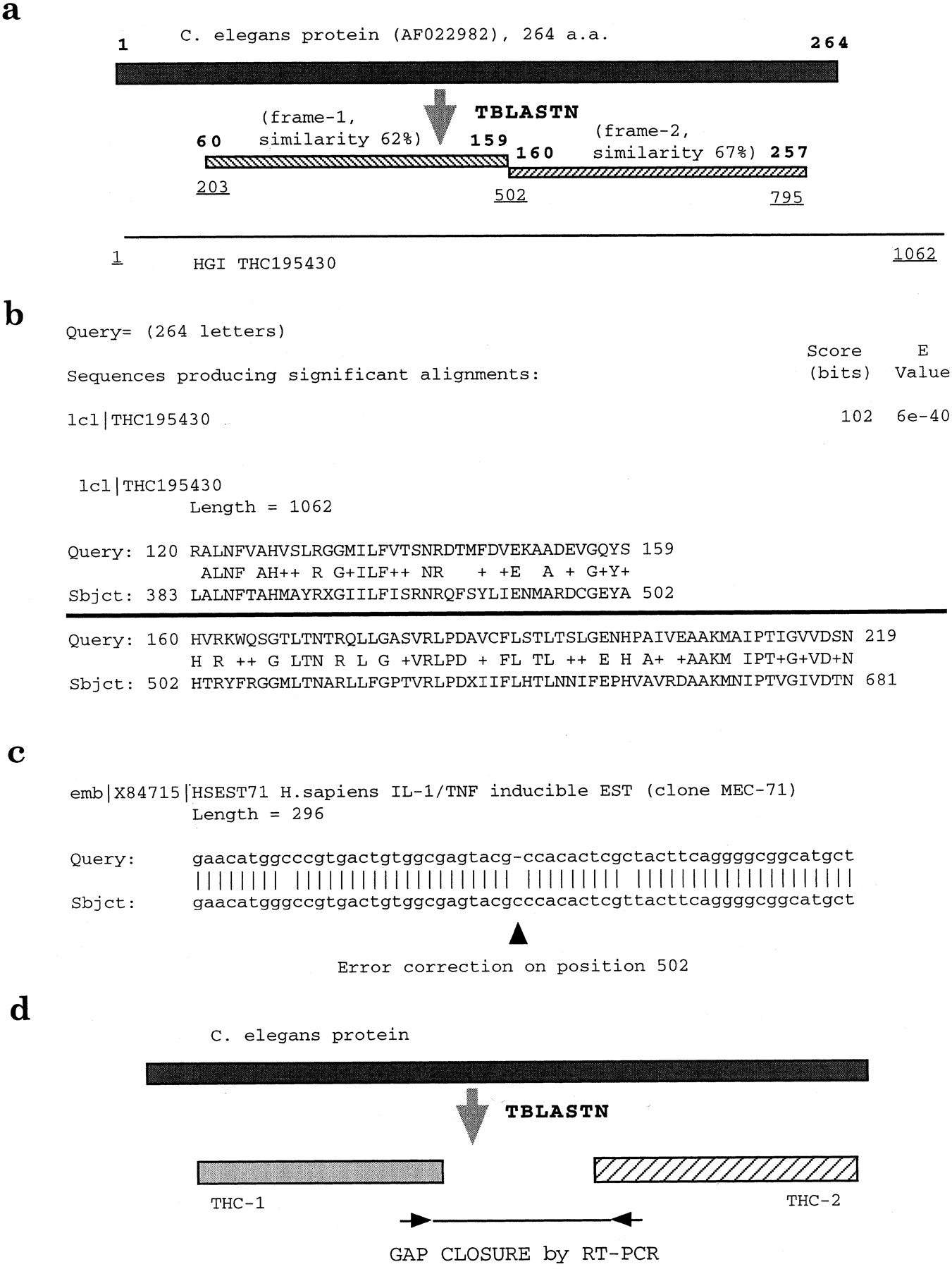
Illustration of CGI gene identification by error correction and gap closure. (a and b), A C. elegans protein sequence of 264 amino acids (AF022982) was used in an initial search against the HGI database. Two different reading frames (frame-1 and frame-2) in THC195430 matched the C. elegans query. Positions of amino acid residues on AF022982 are listed in bold, and positions of nucleotide sequences of THC195430 are underlined. Please note the overlapping nucleotide sequence at position 502 at both reading frames. (b) The TBLASTN results around position 502. A high-level of similarity was observed at both reading frames. (c) Upon further sequence analysis on dbEST, one dbEST entry (X84715) was used to correct the reading frame by inserting a carboxy nucleotide at position 502 as indicated by the arrowhead. A continuous translatable reading frame was generated following the correction. (d) CGI gene identification by a gap closure procedure. In these cases, two separated THC entries were linked by a C. elegans protein scaffold and the gap sequences were determined by performing RT-PCR experiments with primers designed from each THC entry.








