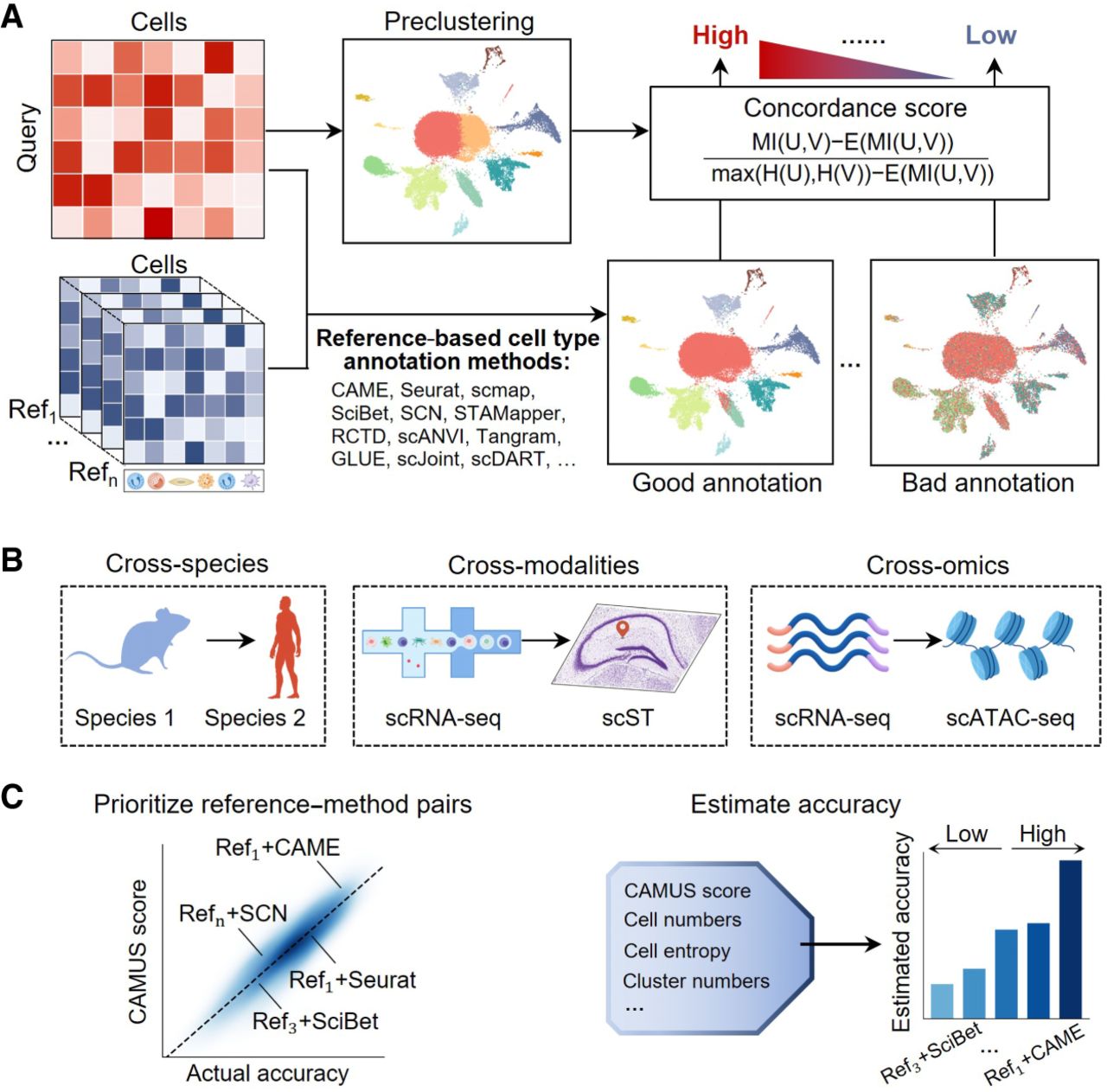
Overview of CAMUS. (A) CAMUS first preclusters single-cell data into several distinct clusters and then combines diverse reference data sets and reference-based annotation methods to annotate the query data set. CAMUS compares the concordance score between the preclustering and the various annotation results. A higher CAMUS score indicates a potentially higher annotation accuracy. (B) CAMUS is applied to three cell type annotation scenarios: (1) cross-species (including species from human, mouse, zebrafish, chick, lizard, turtle, and macaque), (2) cross-modalities (from scRNA-seq data set to scST data set),; and (3) cross-omics (from scRNA-seq data set to scATAC-seq data set). (C) CAMUS helps to define the rank of reference–method pairs, which is positively correlated with the corresponding actual accuracy. The CAMUS score serves as a predictor to estimate annotation accuracy for users.