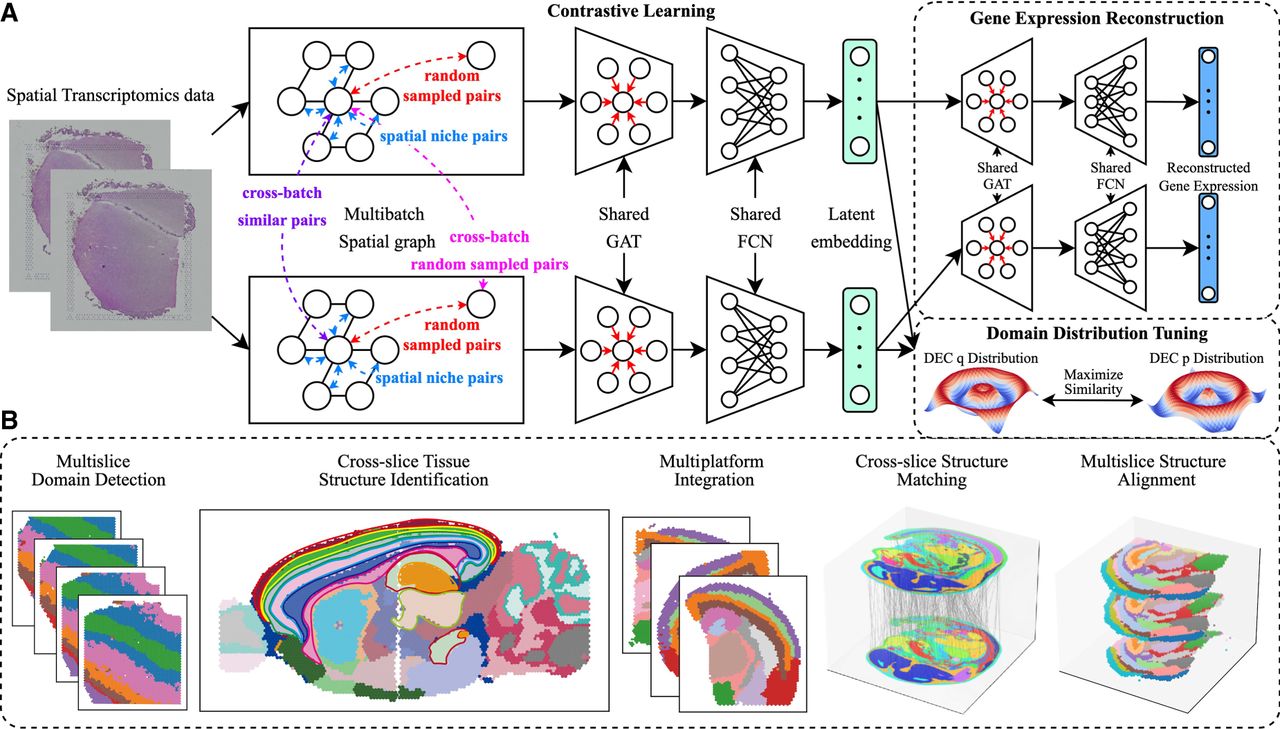
Figure 1.
Overview of the stMSA framework. (A) stMSA leverages multislice omics expression and spatial coordination information as input. It utilizes an auto-encoder to learn latent batch-corrected multislice representation and optimizes the model through three distinct optimization tasks. (B) The latent embedding learned by stMSA serves various downstream tasks, including multislice domain detection, cross-slice tissue structure identification, multiplatform integration, cross-slice matching, and multislice alignment.