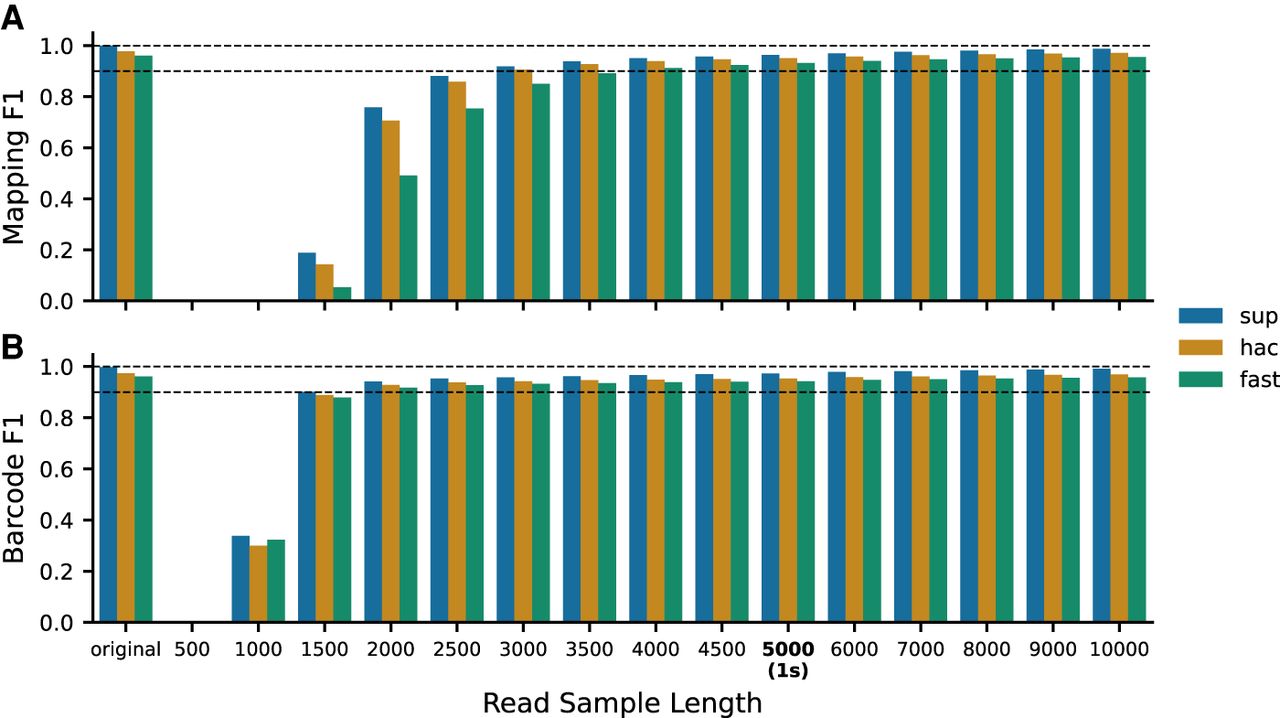
Figure 1.
Comparison of Alignment and Barcode classification F1 as a result of signal length. In total, 10,000 reads were truncated into 500 sample increments up to 5000 samples, with a 1000 sample increment after that, to a maximum of 10,000. Reads were base-called and demultiplexed using the super accuracy (sup), high accuracy (hac), and fast (fast) Dorado models. (A) F1 scores for alignment, where “truth” alignments were defined as the start position of the mapping being within 100 base pairs of the full-length “sup” model read alignment. (B) F1 scores for barcoding classifications, where “truth” barcode classifications were defined as the barcode classification as assigned by the “sup” model for the full-length read.