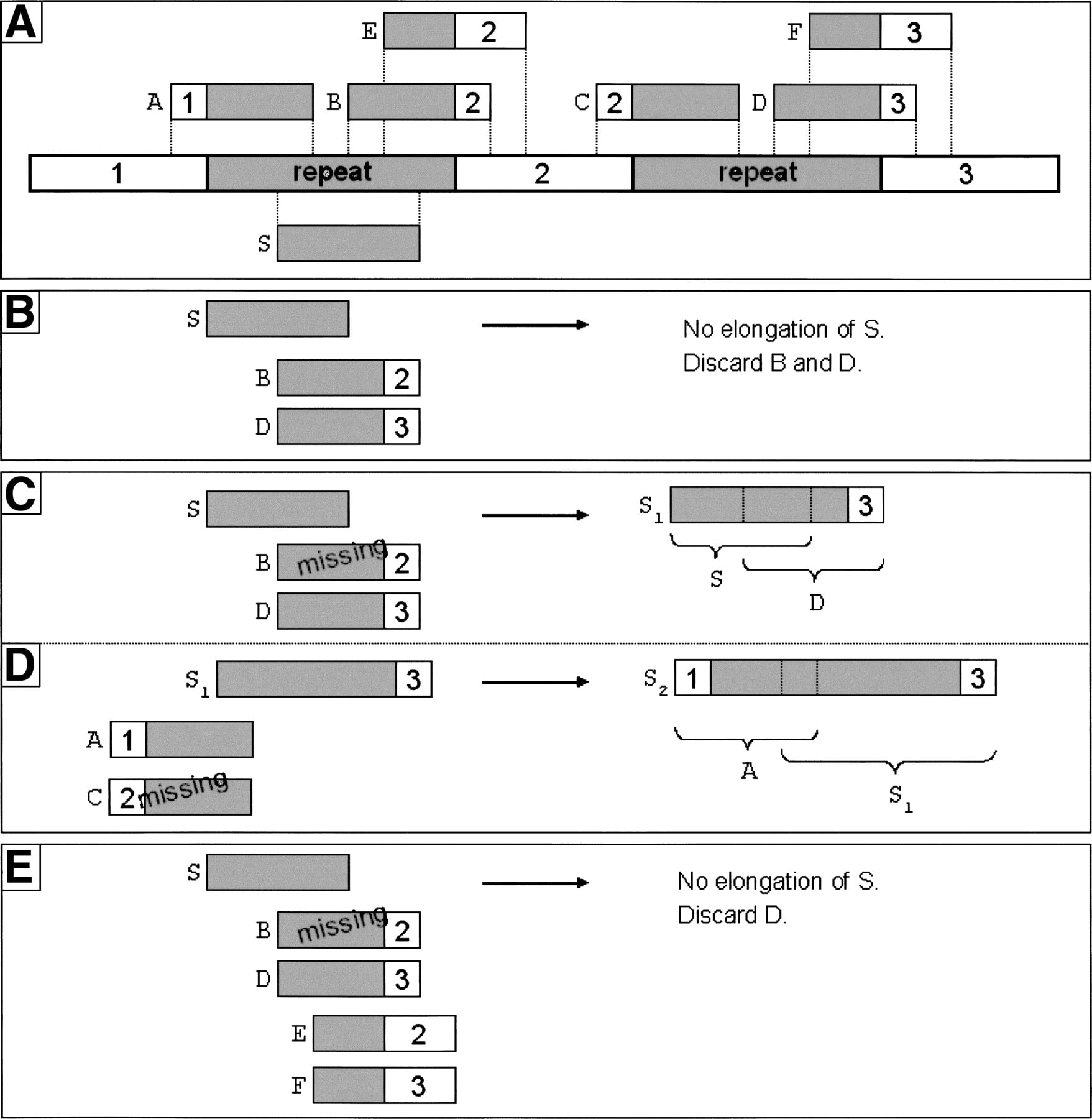
Detection of ambiguities during contig elongation despite missing read information. (A) Target sequence to assemble. Repetitive segments are shown in gray, unique sequence segments are shown in white and indicated with numbers. The positions of reads A–F and S are also shown in panel A. These reads are used to explain the principles of error-free contig extension in panels B–E. (B) Assembly under idealized assumptions (all reads present). Read S to be elongated to the right. An ambiguity is found, both reads B and D could extend read S; neither read D nor B will be assembled. (C, D) Assembly under real assumptions, but without robust contig extension. (C) Read S to be elongated to the right, read B is missing so that the ambiguity cannot be detected; read D would be assembled to S. (D) Naively built contig S1 will be elongated to the far right end (not shown), then the elongation to the left starts, one crucial read is missing again (read C) and the ambiguity cannot be detected; read A would be assembled to contig S1, wrongly connecting sequence segment 1 with sequence segment 3. (E) Assembly under real assumptions with SHARCGS’ robust contig extension. Different overlaps are checked before assembling D, and if any ambiguity is found for smaller overlaps the assembly of D will be rejected. Since both reads E and F could be assembled to the read S, read D will not be assembled to read S.