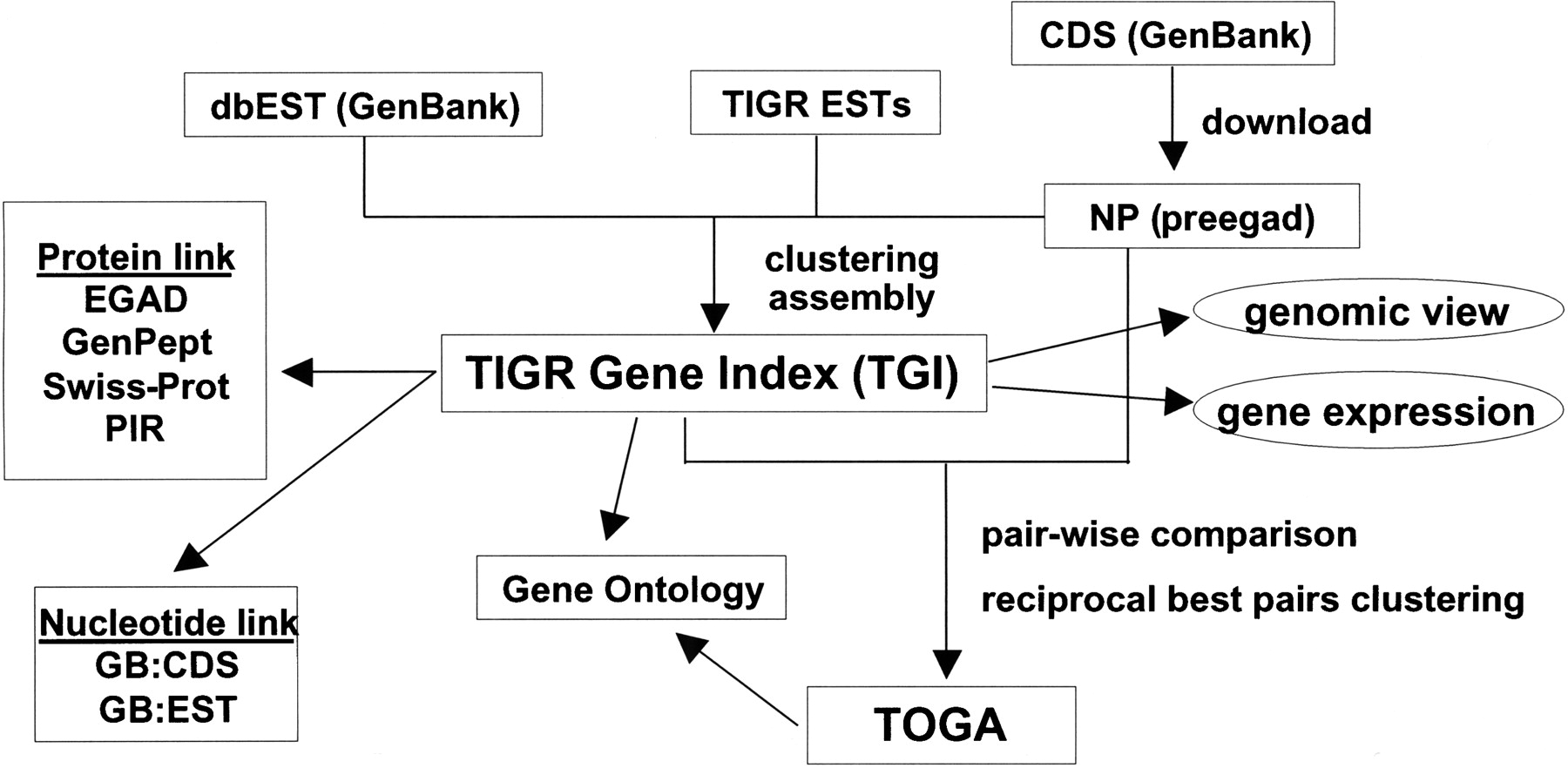
Figure 2.
Conceptual overview of information flow and the database construction process for the TIGR gene index (TGI) databases and TIGR Orthologous Gene Alignment (TOGA). For each species included in the TGI, expressed sequence tag (EST) and gene sequence data are downloaded from public sources and cleaned to remove low-quality and contaminating sequences. These are clustered at high-stringency, individual clusters assembled using CAP3 to construct the tentative consensus (TC) sequences that comprise the individual species-specific TGI databases, annotated, and released through the TGI Web site. Finally, TOGA is assembled using pair-wise comparisons and the reflexive transitive best hit process described in the text.