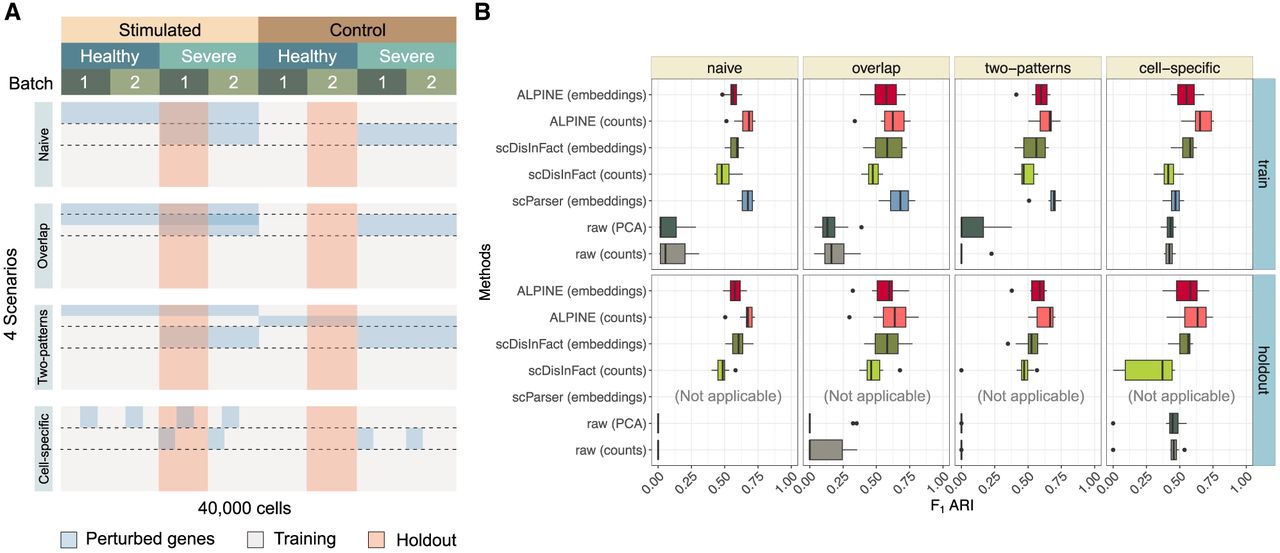
Systematic benchmarking for multibatch and multicondition disentanglement using different simulated scenarios. (A) Perturbation arrangement of count matrices in the simulated data sets. For each scenario, 10 count matrices are generated, corresponding to batch and two condition types (simulation and severity). The four scenarios include: adding signals to one label of each condition with independent perturbations (Naive); shared gene perturbations between conditions (Overlap); signals added to both labels of each condition (Two-pattern); and cell-specific signals (Cell-specific). (B) Box plots compare the F1 ARI performance based on k-means clustering (with the known number of cell types) of ALPINE (embedding and counts) with two existing methods (scParser and scDisInFact) and two baseline approaches (raw, which uses the confounded counts including both batch and covariate effects directly, and raw [PCA], which uses the top 50 PCs of the raw counts) across training and holdout data sets. ALPINE (both embedding and counts) shows consistently strong performance, especially in more complex scenarios.