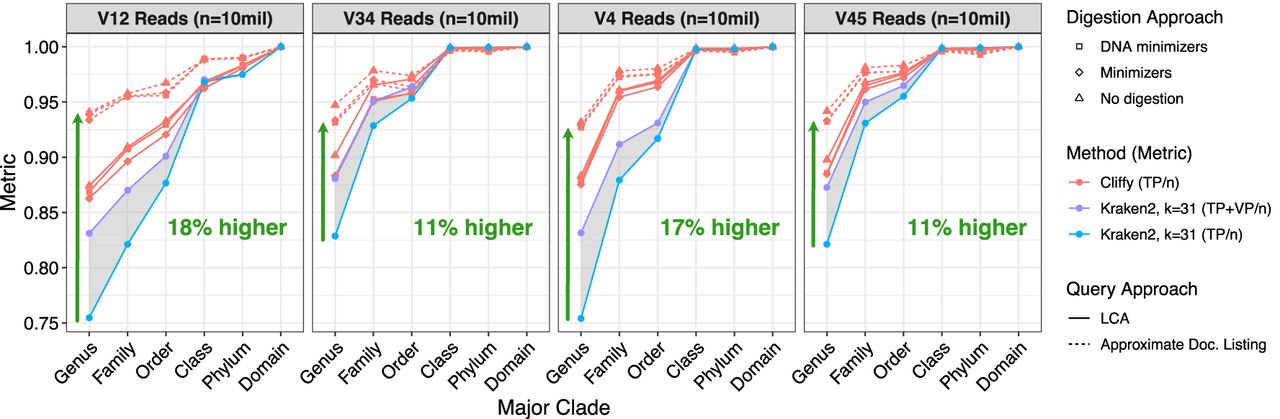
Figure 3.
Read-level classification accuracy of Cliffy and Kraken2 on the aquatic data set. Shows the read-level classification (n = 10 million Illumina 250 bp paired-end) accuracy for Cliffy and Kraken2 on the Aquatic data set using four different hypervariable regions at different levels of the tree. Each subplot shows Cliffy's performance when using three different types of digestion strategy and two different query approaches: lowest common ancestor and approximate document listing. The gray-shaded region ranges from Kraken2's accuracy when treating all vague positives (VPs) as incorrect compared with treating them all as correct.