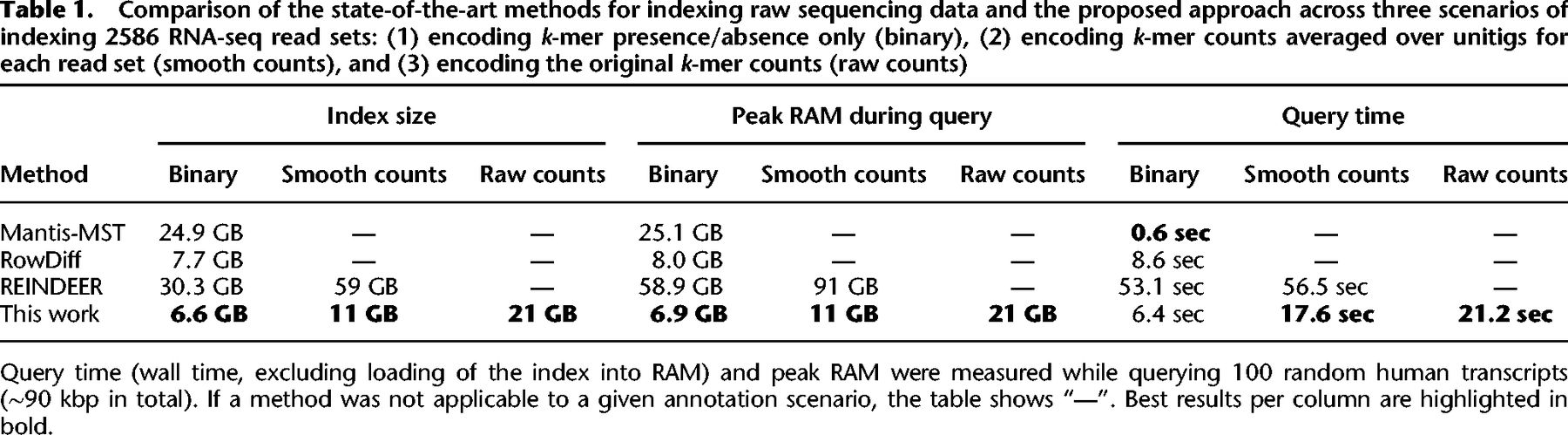
Table 1.
Comparison of the state-of-the-art methods for indexing raw sequencing data and the proposed approach across three scenarios of indexing 2586 RNA-seq read sets: (1) encoding k-mer presence/absence only (binary), (2) encoding k-mer counts averaged over unitigs for each read set (smooth counts), and (3) encoding the original k-mer counts (raw counts)