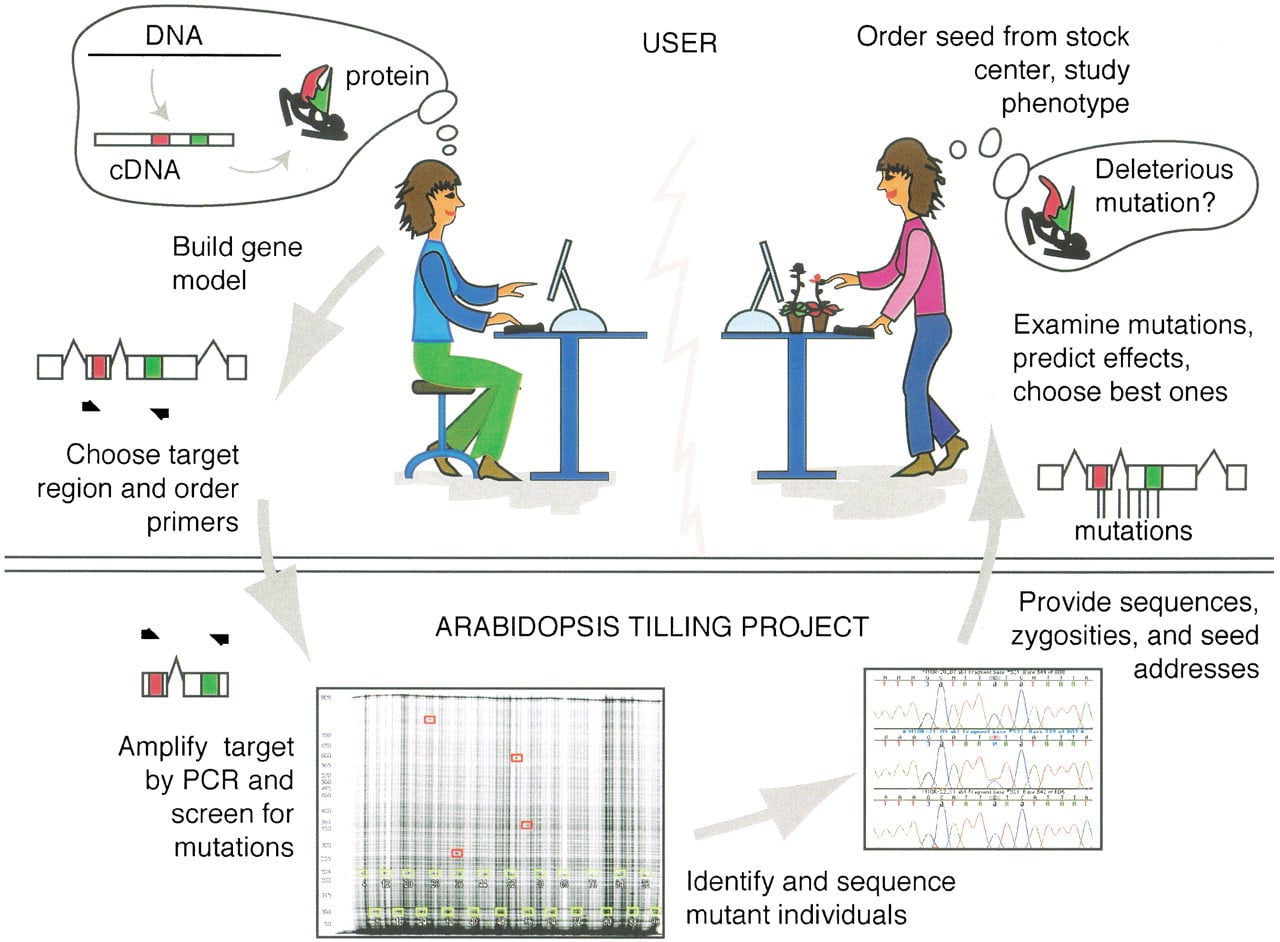
Outline of steps involved in the Arabidopsis TILLING Project. A user of the service builds a model for the target gene including conserved coding regions (red and green boxes) and chooses primers for a 1-kb region where she would like to find mutations. As part of our automated ordering system, we have developed tools for gene model and protein homology model assembly (CODDLE Input,http://www.proweb.org/input/), and for scoring genes to determine the regions with the highest probability of discovering deleterious changes (CODDLE, http://www.proweb.org/coddle/). Primers are ordered and paid for by the user and shipped directly from the oligonucleotide supplier (MWG Biotech) to the TILLING facility. Upon receipt of primers, 3072M 2 plant DNAs are screened in eightfold pools for induced mutations. The individuals harboring identified mutations are tracked down, and these samples enter a sequencing queue. For each mutation, the nucleotide change, its position, and its zygosity are determined by standard dye-terminator sequencing. Mutations are stored in a public database, and the researcher who placed the order is sent an E-mail message summarizing the mutations discovered. To aid the researcher in deciding which mutations to characterize, mutations are automatically analyzed by the PARSESNP program (http://www.proweb.org/parsesnp/), which provides information on the location and severity of mutations and provides information on the creation or loss of restriction sites caused by the induced polymorphisms (see Fig. 3). Hyperlinks are provided from each mutation to the Arabidopsis Information Resource (TAIR) for obtaining seed stocks from the Arabidopsis Biological Resource Center.